 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen ASR Leaderboard: Towards Reproducible and Transparent Multilingual and Long-Form Speech Recognition Evaluation
Oct 08, 2025Despite rapid progress, ASR evaluation remains saturated with short-form English, and efficiency is rarely reported. We present the Open ASR Leaderboard, a fully reproducible benchmark and interactive leaderboard comparing 60+ open-source and proprietary systems across 11 datasets, including dedicated multilingual and long-form tracks. We standardize text normalization and report both word error rate (WER) and inverse real-time factor (RTFx), enabling fair accuracy-efficiency comparisons. For English transcription, Conformer encoders paired with LLM decoders achieve the best average WER but are slower, while CTC and TDT decoders deliver much better RTFx, making them attractive for long-form and offline use. Whisper-derived encoders fine-tuned for English improve accuracy but often trade off multilingual coverage. All code and dataset loaders are open-sourced to support transparent, extensible evaluation.
Discrete Audio Tokens: More Than a Survey!
Jun 12, 2025Discrete audio tokens are compact representations that aim to preserve perceptual quality, phonetic content, and speaker characteristics while enabling efficient storage and inference, as well as competitive performance across diverse downstream tasks.They provide a practical alternative to continuous features, enabling the integration of speech and audio into modern large language models (LLMs). As interest in token-based audio processing grows, various tokenization methods have emerged, and several surveys have reviewed the latest progress in the field. However, existing studies often focus on specific domains or tasks and lack a unified comparison across various benchmarks. This paper presents a systematic review and benchmark of discrete audio tokenizers, covering three domains: speech, music, and general audio. We propose a taxonomy of tokenization approaches based on encoder-decoder, quantization techniques, training paradigm, streamability, and application domains. We evaluate tokenizers on multiple benchmarks for reconstruction, downstream performance, and acoustic language modeling, and analyze trade-offs through controlled ablation studies. Our findings highlight key limitations, practical considerations, and open challenges, providing insight and guidance for future research in this rapidly evolving area. For more information, including our main results and tokenizer database, please refer to our website: https://poonehmousavi.github.io/dates-website/.
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025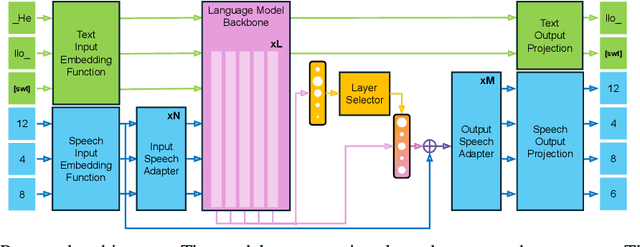
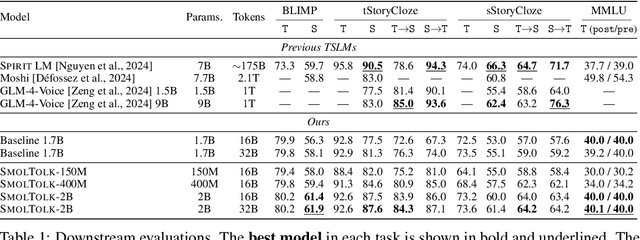
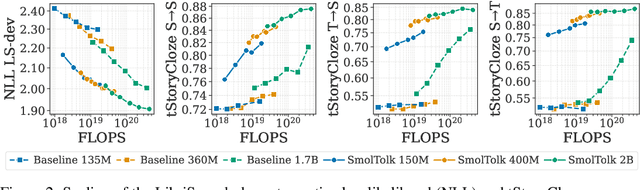
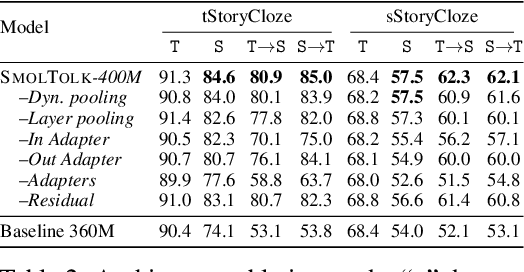
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
An Analysis of Linear Complexity Attention Substitutes with BEST-RQ
Sep 04, 2024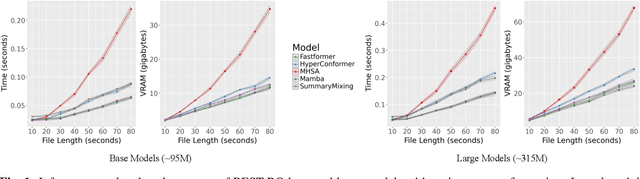
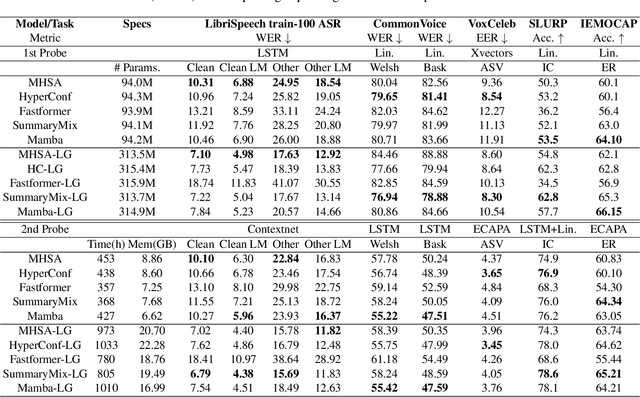
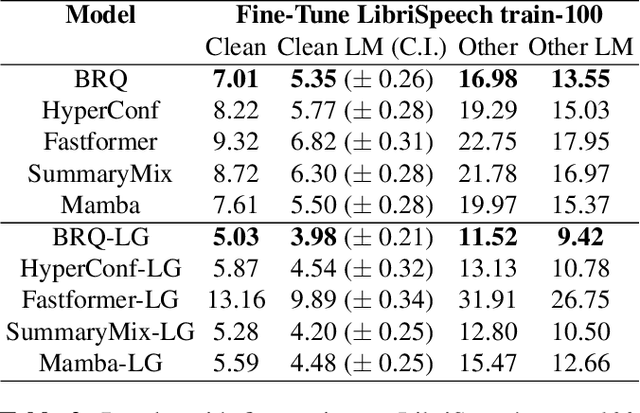
Self-Supervised Learning (SSL) has proven to be effective in various domains, including speech processing. However, SSL is computationally and memory expensive. This is in part due the quadratic complexity of multi-head self-attention (MHSA). Alternatives for MHSA have been proposed and used in the speech domain, but have yet to be investigated properly in an SSL setting. In this work, we study the effects of replacing MHSA with recent state-of-the-art alternatives that have linear complexity, namely, HyperMixing, Fastformer, SummaryMixing, and Mamba. We evaluate these methods by looking at the speed, the amount of VRAM consumed, and the performance on the SSL MP3S benchmark. Results show that these linear alternatives maintain competitive performance compared to MHSA while, on average, decreasing VRAM consumption by around 20% to 60% and increasing speed from 7% to 65% for input sequences ranging from 20 to 80 seconds.
ProGRes: Prompted Generative Rescoring on ASR n-Best
Aug 30, 2024Large Language Models (LLMs) have shown their ability to improve the performance of speech recognizers by effectively rescoring the n-best hypotheses generated during the beam search process. However, the best way to exploit recent generative instruction-tuned LLMs for hypothesis rescoring is still unclear. This paper proposes a novel method that uses instruction-tuned LLMs to dynamically expand the n-best speech recognition hypotheses with new hypotheses generated through appropriately-prompted LLMs. Specifically, we introduce a new zero-shot method for ASR n-best rescoring, which combines confidence scores, LLM sequence scoring, and prompt-based hypothesis generation. We compare Llama-3-Instruct, GPT-3.5 Turbo, and GPT-4 Turbo as prompt-based generators with Llama-3 as sequence scorer LLM. We evaluated our approach using different speech recognizers and observed significant relative improvement in the word error rate (WER) ranging from 5% to 25%.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024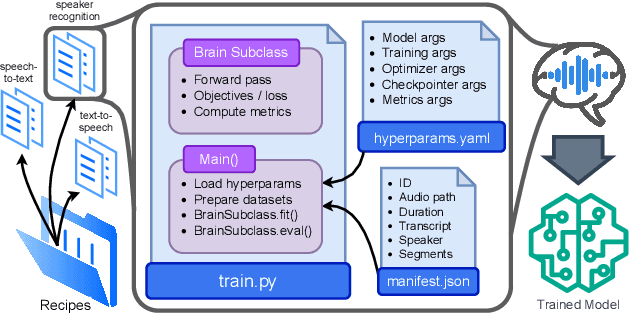

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Jun 09, 2024In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5\%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
* Accepted to INTERSPEECH 2024
Stabilising and accelerating light gated recurrent units for automatic speech recognition
Feb 16, 2023The light gated recurrent units (Li-GRU) is well-known for achieving impressive results in automatic speech recognition (ASR) tasks while being lighter and faster to train than a standard gated recurrent units (GRU). However, the unbounded nature of its rectified linear unit on the candidate recurrent gate induces an important gradient exploding phenomenon disrupting the training process and preventing it from being applied to famous datasets. In this paper, we theoretically and empirically derive the necessary conditions for its stability as well as engineering mechanisms to speed up by a factor of five its training time, hence introducing a novel version of this architecture named SLi-GRU. Then, we evaluate its performance both on a toy task illustrating its newly acquired capabilities and a set of three different ASR datasets demonstrating lower word error rates compared to more complex recurrent neural networks.