 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025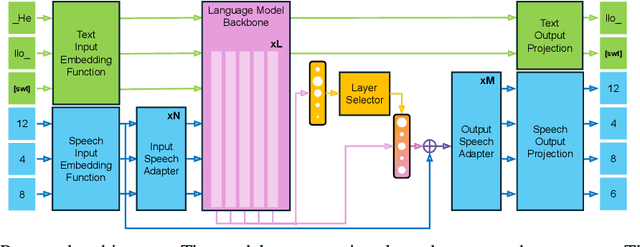
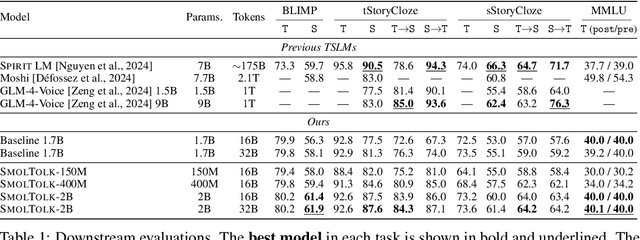
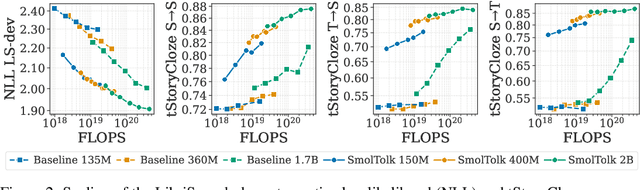
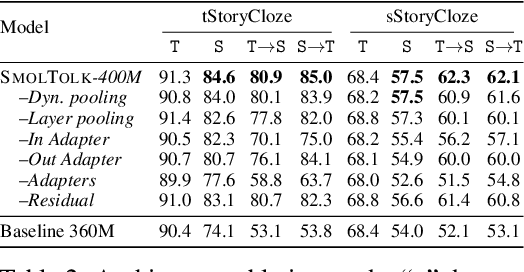
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
Transfer Learning from Whisper for Microscopic Intelligibility Prediction
Apr 02, 2024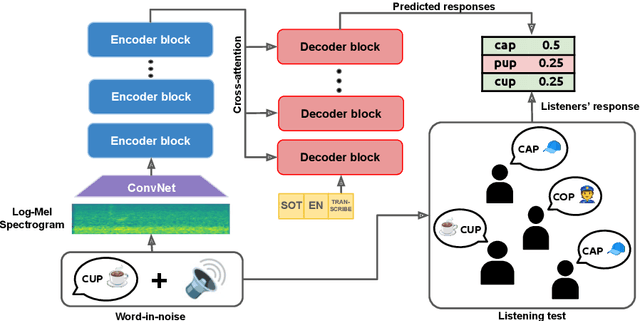
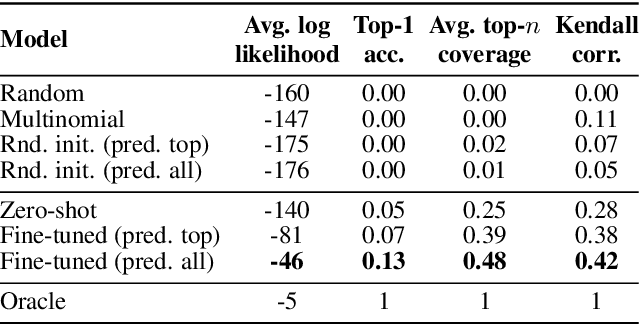
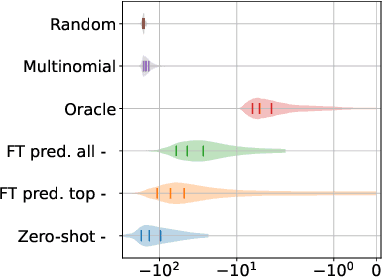
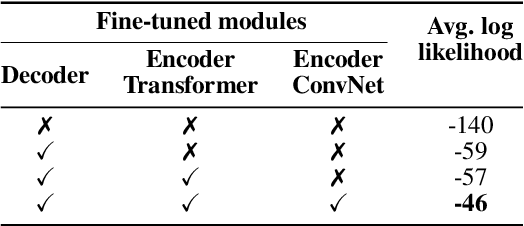
Macroscopic intelligibility models predict the expected human word-error-rate for a given speech-in-noise stimulus. In contrast, microscopic intelligibility models aim to make fine-grained predictions about listeners' perception, e.g. predicting phonetic or lexical responses. State-of-the-art macroscopic models use transfer learning from large scale deep learning models for speech processing, whereas such methods have rarely been used for microscopic modeling. In this paper, we study the use of transfer learning from Whisper, a state-of-the-art deep learning model for automatic speech recognition, for microscopic intelligibility prediction at the level of lexical responses. Our method outperforms the considered baselines, even in a zero-shot setup, and yields a relative improvement of up to 66\% when fine-tuned to predict listeners' responses. Our results showcase the promise of large scale deep learning based methods for microscopic intelligibility prediction.
Scaling Properties of Speech Language Models
Mar 31, 2024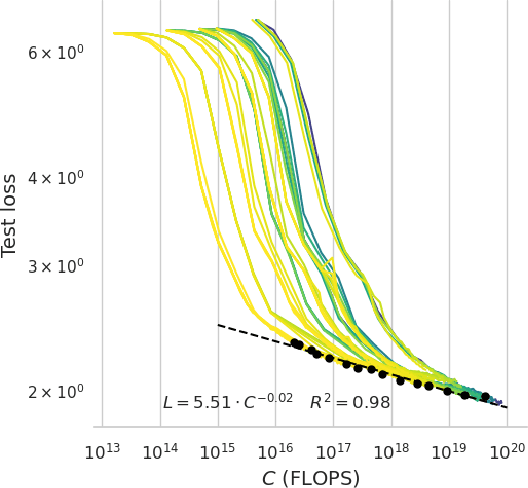
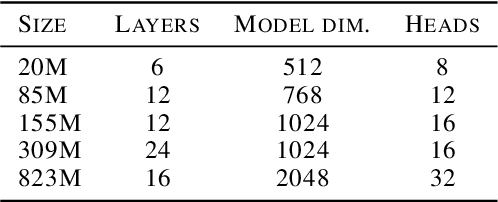
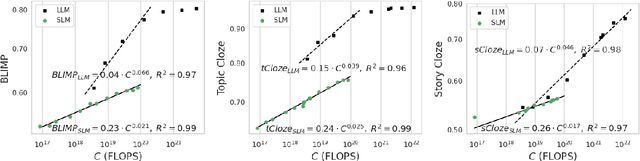
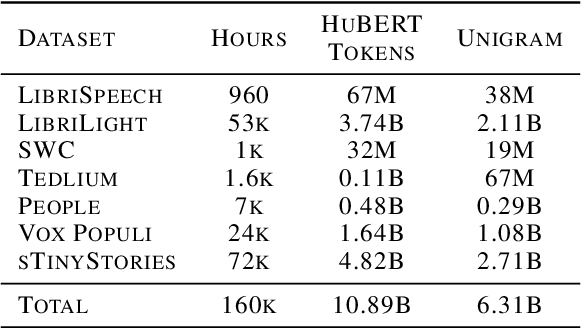
Speech Language Models (SLMs) aim to learn language from raw audio, without textual resources. Despite significant advances, our current models exhibit weak syntax and semantic abilities. However, if the scaling properties of neural language models hold for the speech modality, these abilities will improve as the amount of compute used for training increases. In this paper, we use models of this scaling behavior to estimate the scale at which our current methods will yield a SLM with the English proficiency of text-based Large Language Models (LLMs). We establish a strong correlation between pre-training loss and downstream syntactic and semantic performance in SLMs and LLMs, which results in predictable scaling of linguistic performance. We show that the linguistic performance of SLMs scales up to three orders of magnitude more slowly than that of text-based LLMs. Additionally, we study the benefits of synthetic data designed to boost semantic understanding and the effects of coarser speech tokenization.
Speech foundation models on intelligibility prediction for hearing-impaired listeners
Jan 24, 2024Speech foundation models (SFMs) have been benchmarked on many speech processing tasks, often achieving state-of-the-art performance with minimal adaptation. However, the SFM paradigm has been significantly less explored for applications of interest to the speech perception community. In this paper we present a systematic evaluation of 10 SFMs on one such application: Speech intelligibility prediction. We focus on the non-intrusive setup of the Clarity Prediction Challenge 2 (CPC2), where the task is to predict the percentage of words correctly perceived by hearing-impaired listeners from speech-in-noise recordings. We propose a simple method that learns a lightweight specialized prediction head on top of frozen SFMs to approach the problem. Our results reveal statistically significant differences in performance across SFMs. Our method resulted in the winning submission in the CPC2, demonstrating its promise for speech perception applications.
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022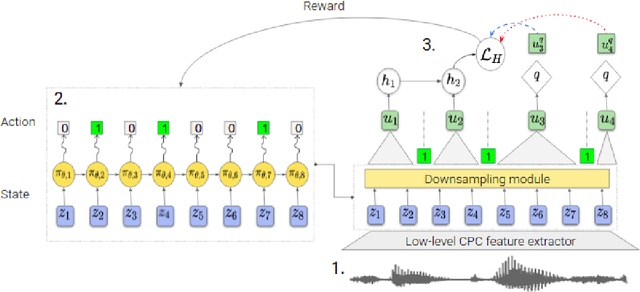
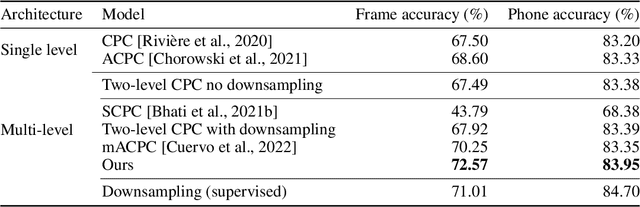


The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Contrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words
Oct 29, 2021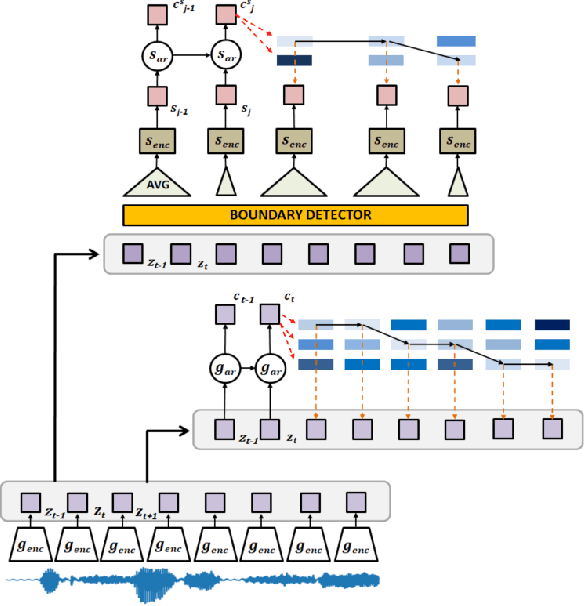
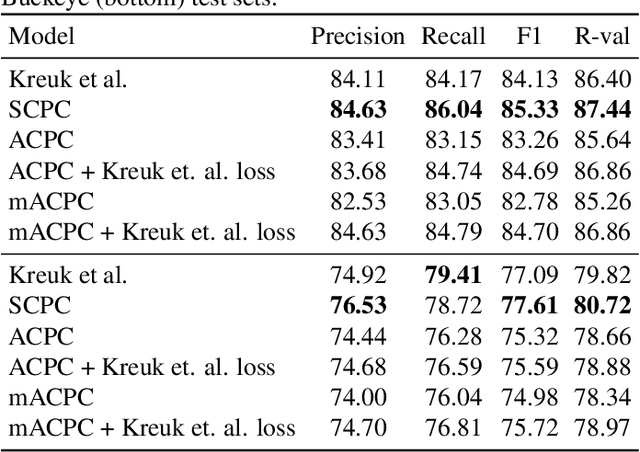
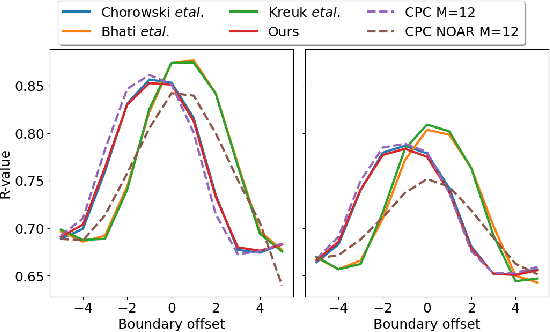
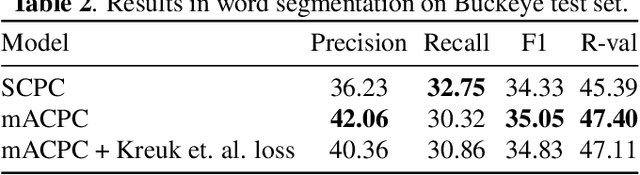
We investigate the performance on phoneme categorization and phoneme and word segmentation of several self-supervised learning (SSL) methods based on Contrastive Predictive Coding (CPC). Our experiments show that with the existing algorithms there is a trade off between categorization and segmentation performance. We investigate the source of this conflict and conclude that the use of context building networks, albeit necessary for superior performance on categorization tasks, harms segmentation performance by causing a temporal shift on the learned representations. Aiming to bridge this gap, we take inspiration from the leading approach on segmentation, which simultaneously models the speech signal at the frame and phoneme level, and incorporate multi-level modelling into Aligned CPC (ACPC), a variation of CPC which exhibits the best performance on categorization tasks. Our multi-level ACPC (mACPC) improves in all categorization metrics and achieves state-of-the-art performance in word segmentation.
PAMELI: A Meta-Algorithm for Computationally Expensive Multi-Objective Optimization Problems
Mar 19, 2021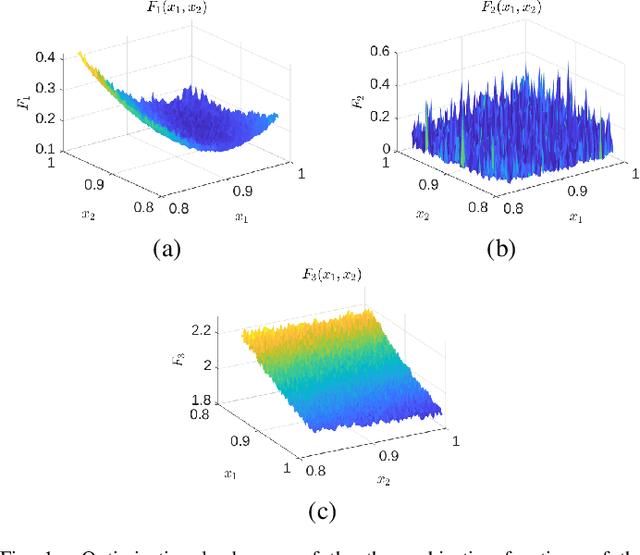
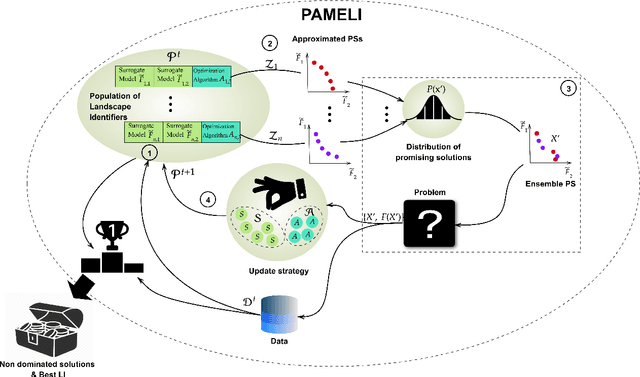
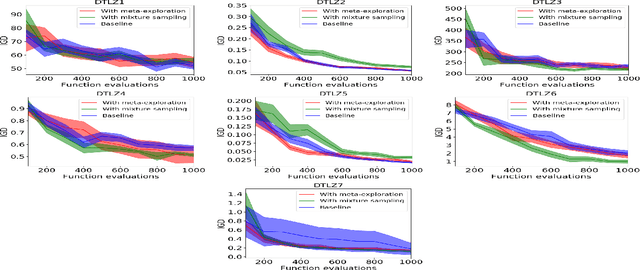
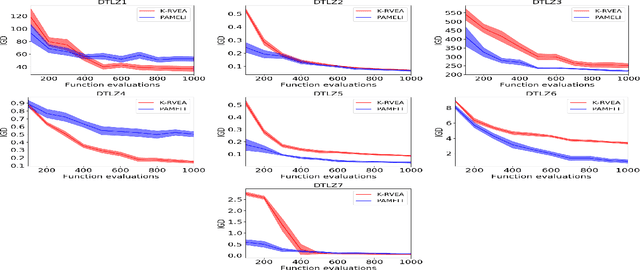
We present an algorithm for multi-objective optimization of computationally expensive problems. The proposed algorithm is based on solving a set of surrogate problems defined by models of the real one, so that only solutions estimated to be approximately Pareto-optimal are evaluated using the real expensive functions. Aside of the search for solutions, our algorithm also performs a meta-search for optimal surrogate models and navigation strategies for the optimization landscape, therefore adapting the search strategy for solutions to the problem as new information about it is obtained. The competitiveness of our approach is demonstrated by an experimental comparison with one state-of-the-art surrogate-assisted evolutionary algorithm on a set of benchmark problems.
Emergent cooperation through mutual information maximization
Jun 21, 2020



With artificial intelligence systems becoming ubiquitous in our society, its designers will soon have to start to consider its social dimension, as many of these systems will have to interact among them to work efficiently. With this in mind, we propose a decentralized deep reinforcement learning algorithm for the design of cooperative multi-agent systems. The algorithm is based on the hypothesis that highly correlated actions are a feature of cooperative systems, and hence, we propose the insertion of an auxiliary objective of maximization of the mutual information between the actions of agents in the learning problem. Our system is applied to a social dilemma, a problem whose optimal solution requires that agents cooperate to maximize a macroscopic performance function despite the divergent individual objectives of each agent. By comparing the performance of the proposed system to a system without the auxiliary objective, we conclude that the maximization of mutual information among agents promotes the emergence of cooperation in social dilemmas.