 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022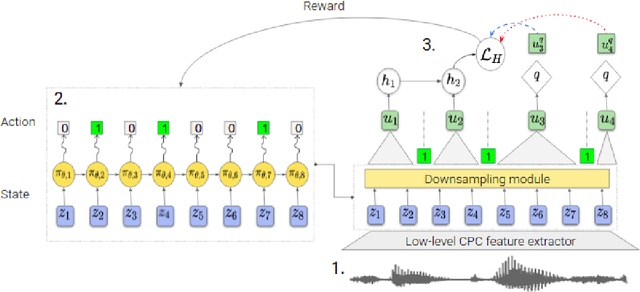
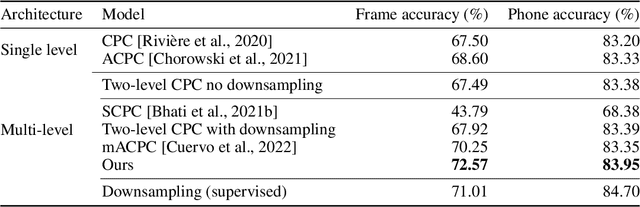


The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Contrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words
Oct 29, 2021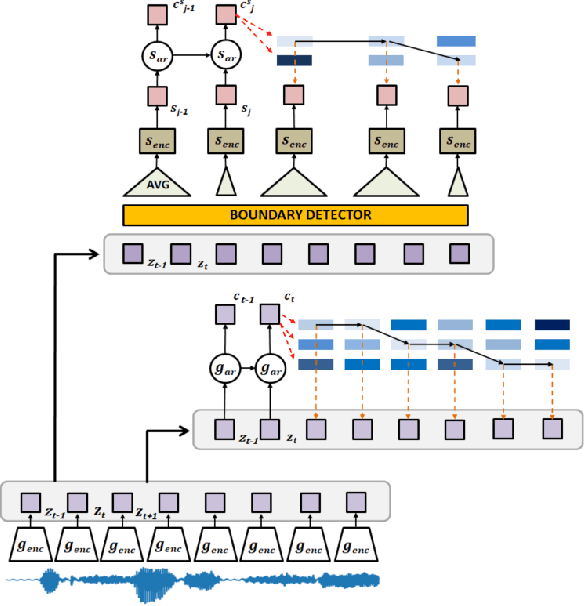
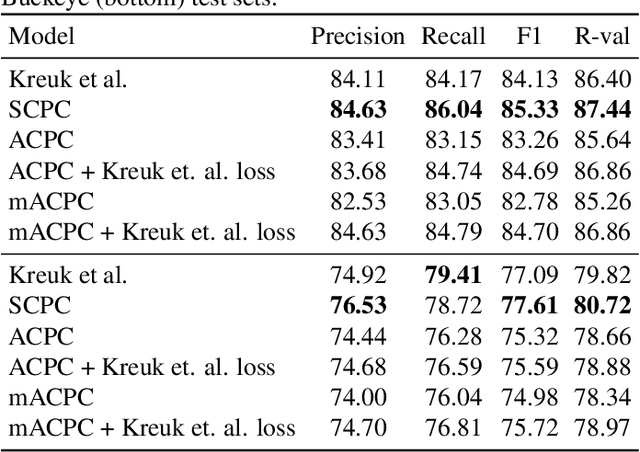
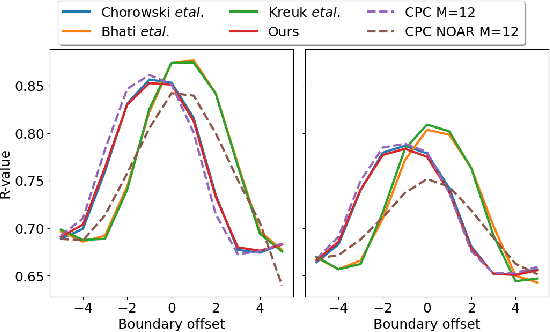
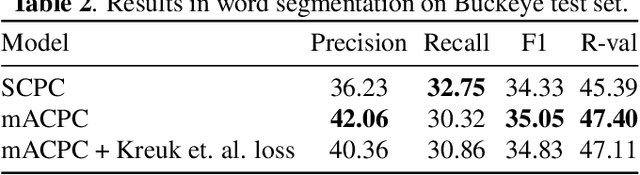
We investigate the performance on phoneme categorization and phoneme and word segmentation of several self-supervised learning (SSL) methods based on Contrastive Predictive Coding (CPC). Our experiments show that with the existing algorithms there is a trade off between categorization and segmentation performance. We investigate the source of this conflict and conclude that the use of context building networks, albeit necessary for superior performance on categorization tasks, harms segmentation performance by causing a temporal shift on the learned representations. Aiming to bridge this gap, we take inspiration from the leading approach on segmentation, which simultaneously models the speech signal at the frame and phoneme level, and incorporate multi-level modelling into Aligned CPC (ACPC), a variation of CPC which exhibits the best performance on categorization tasks. Our multi-level ACPC (mACPC) improves in all categorization metrics and achieves state-of-the-art performance in word segmentation.
Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw
Jun 22, 2021

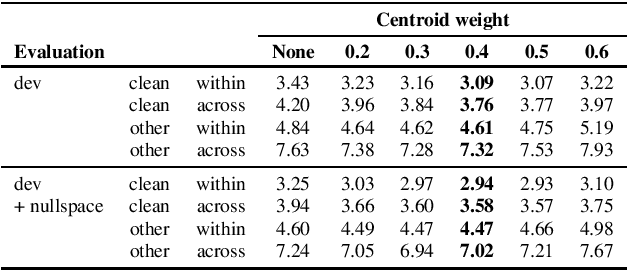
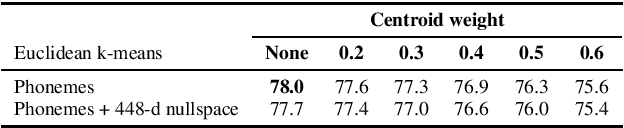
We present a number of low-resource approaches to the tasks of the Zero Resource Speech Challenge 2021. We build on the unsupervised representations of speech proposed by the organizers as a baseline, derived from CPC and clustered with the k-means algorithm. We demonstrate that simple methods of refining those representations can narrow the gap, or even improve upon the solutions which use a high computational budget. The results lead to the conclusion that the CPC-derived representations are still too noisy for training language models, but stable enough for simpler forms of pattern matching and retrieval.
Aligned Contrastive Predictive Coding
Apr 29, 2021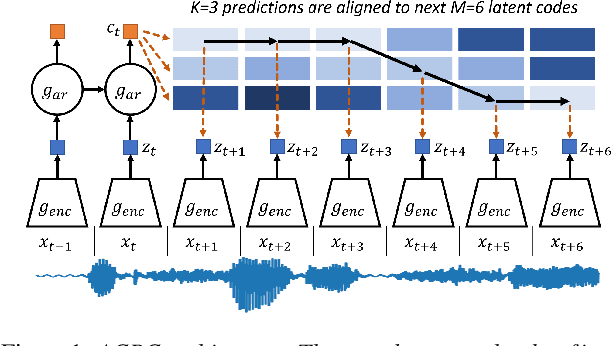

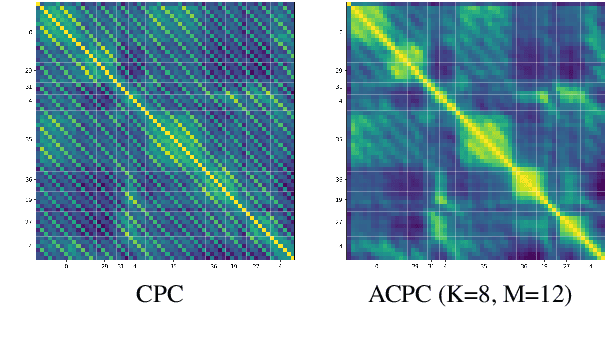
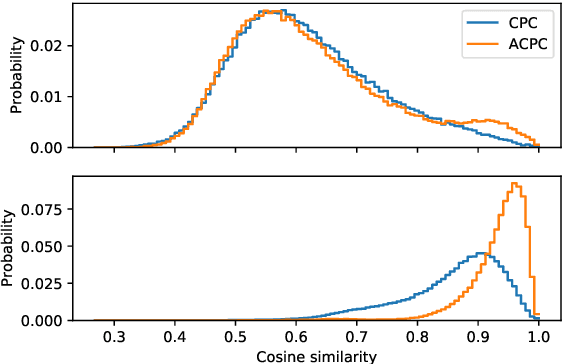
We investigate the possibility of forcing a self-supervised model trained using a contrastive predictive loss to extract slowly varying latent representations. Rather than producing individual predictions for each of the future representations, the model emits a sequence of predictions shorter than that of the upcoming representations to which they will be aligned. In this way, the prediction network solves a simpler task of predicting the next symbols, but not their exact timing, while the encoding network is trained to produce piece-wise constant latent codes. We evaluate the model on a speech coding task and demonstrate that the proposed Aligned Contrastive Predictive Coding (ACPC) leads to higher linear phone prediction accuracy and lower ABX error rates, while being slightly faster to train due to the reduced number of prediction heads.
Named Entity Recognition and Linking Augmented with Large-Scale Structured Data
Apr 27, 2021
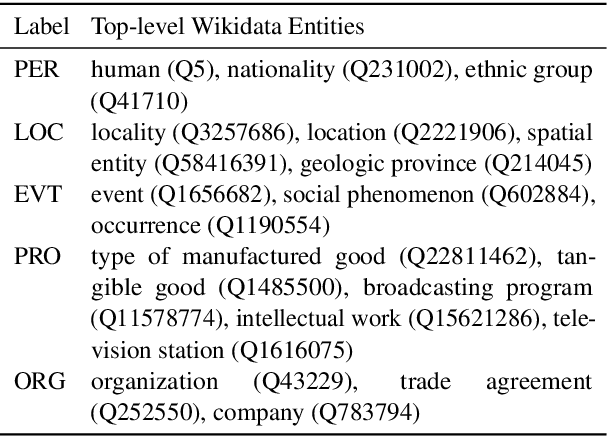
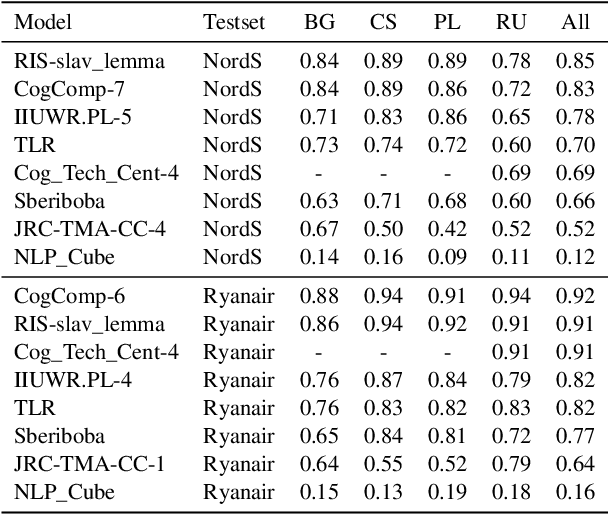
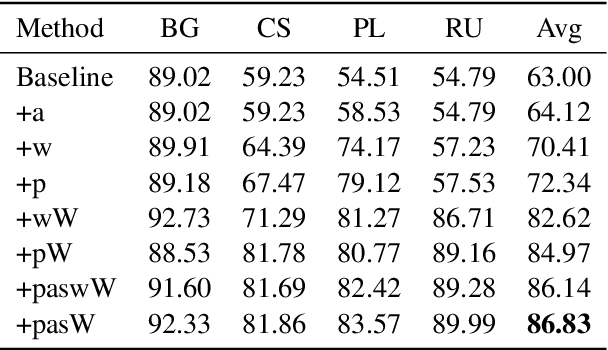
In this paper we describe our submissions to the 2nd and 3rd SlavNER Shared Tasks held at BSNLP 2019 and BSNLP 2021, respectively. The tasks focused on the analysis of Named Entities in multilingual Web documents in Slavic languages with rich inflection. Our solution takes advantage of large collections of both unstructured and structured documents. The former serve as data for unsupervised training of language models and embeddings of lexical units. The latter refers to Wikipedia and its structured counterpart - Wikidata, our source of lemmatization rules, and real-world entities. With the aid of those resources, our system could recognize, normalize and link entities, while being trained with only small amounts of labeled data.
A Talker Ensemble: the University of Wrocław's Entry to the NIPS 2017 Conversational Intelligence Challenge
May 21, 2018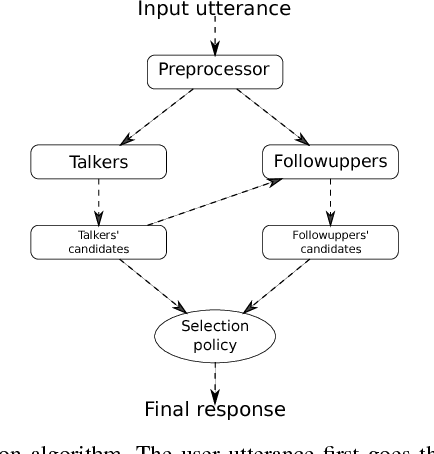
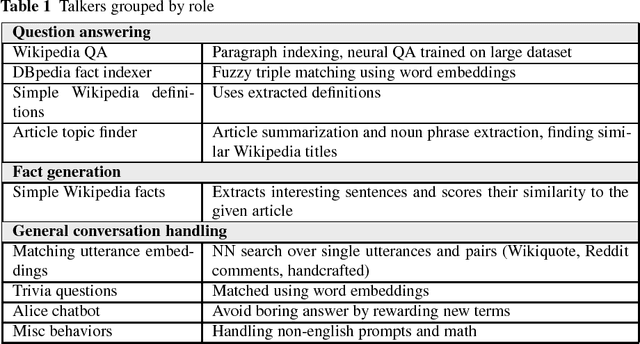
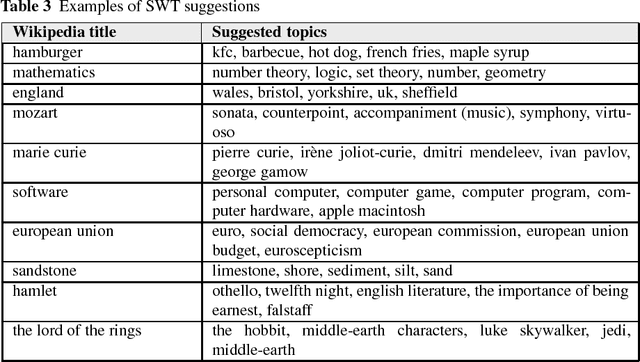
We present Poetwannabe, a chatbot submitted by the University of Wroc{\l}aw to the NIPS 2017 Conversational Intelligence Challenge, in which it ranked first ex-aequo. It is able to conduct a conversation with a user in a natural language. The primary functionality of our dialogue system is context-aware question answering (QA), while its secondary function is maintaining user engagement. The chatbot is composed of a number of sub-modules, which independently prepare replies to user's prompts and assess their own confidence. To answer questions, our dialogue system relies heavily on factual data, sourced mostly from Wikipedia and DBpedia, data of real user interactions in public forums, as well as data concerning general literature. Where applicable, modules are trained on large datasets using GPUs. However, to comply with the competition's requirements, the final system is compact and runs on commodity hardware.
Read, Tag, and Parse All at Once, or Fully-neural Dependency Parsing
Jun 05, 2017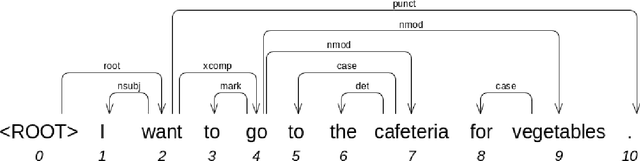

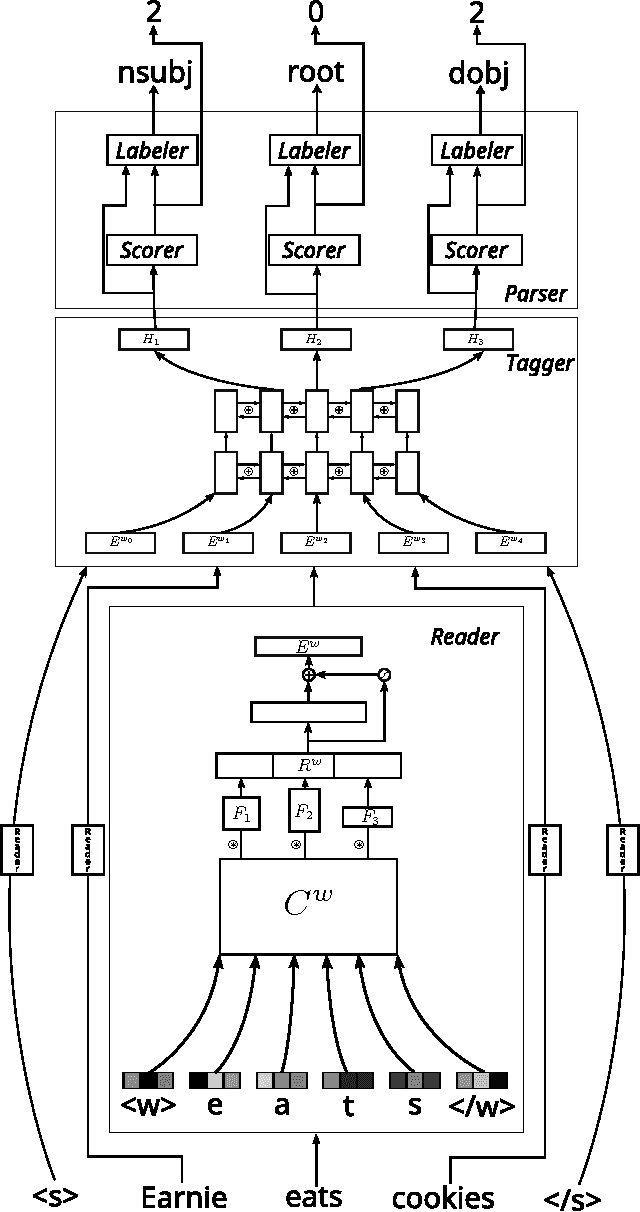
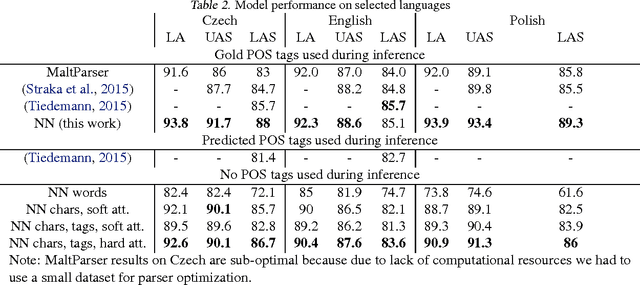
We present a dependency parser implemented as a single deep neural network that reads orthographic representations of words and directly generates dependencies and their labels. Unlike typical approaches to parsing, the model doesn't require part-of-speech (POS) tagging of the sentences. With proper regularization and additional supervision achieved with multitask learning we reach state-of-the-art performance on Slavic languages from the Universal Dependencies treebank: with no linguistic features other than characters, our parser is as accurate as a transition- based system trained on perfect POS tags.
On Multilingual Training of Neural Dependency Parsers
May 29, 2017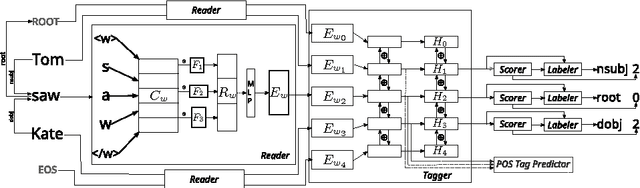
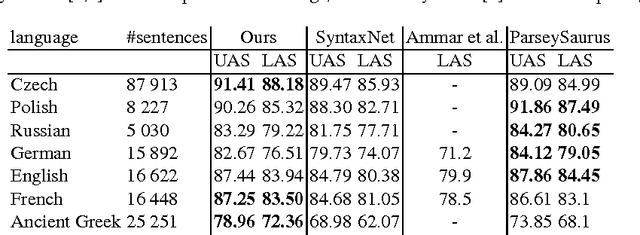
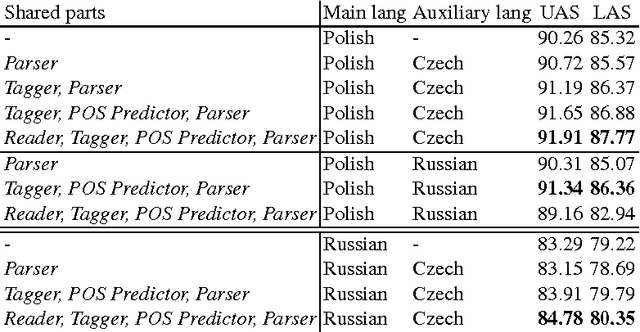

We show that a recently proposed neural dependency parser can be improved by joint training on multiple languages from the same family. The parser is implemented as a deep neural network whose only input is orthographic representations of words. In order to successfully parse, the network has to discover how linguistically relevant concepts can be inferred from word spellings. We analyze the representations of characters and words that are learned by the network to establish which properties of languages were accounted for. In particular we show that the parser has approximately learned to associate Latin characters with their Cyrillic counterparts and that it can group Polish and Russian words that have a similar grammatical function. Finally, we evaluate the parser on selected languages from the Universal Dependencies dataset and show that it is competitive with other recently proposed state-of-the art methods, while having a simple structure.