 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Hyper-Scaling with KV Cache Compression
Jun 05, 2025Inference-time scaling trades efficiency for increased reasoning accuracy by generating longer or more parallel sequences. However, in Transformer LLMs, generation cost is bottlenecked by the size of the key-value (KV) cache, rather than the number of generated tokens. Hence, we explore inference-time hyper-scaling: by compressing the KV cache, we can generate more tokens within the same compute budget and further improve the accuracy of scaled inference. The success of this approach, however, hinges on the ability of compression methods to preserve accuracy even at high compression ratios. To make hyper-scaling practical, we introduce Dynamic Memory Sparsification (DMS), a novel method for sparsifying KV caches that only requires 1K training steps to achieve 8$\times$ compression, while maintaining better accuracy than training-free sparse attention. Instead of prematurely discarding cached tokens, DMS delays token eviction, implicitly merging representations and preserving critical information. We demonstrate the effectiveness of inference-time hyper-scaling with DMS on multiple families of LLMs, showing that it boosts accuracy for comparable inference runtime and memory load. For instance, we enhance Qwen-R1 32B by an average of 9.1 points on AIME 24, 7.6 on GPQA, and 9.6 on LiveCodeBench across compute budgets.
Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference
Mar 14, 2024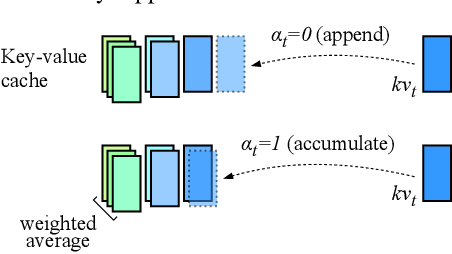
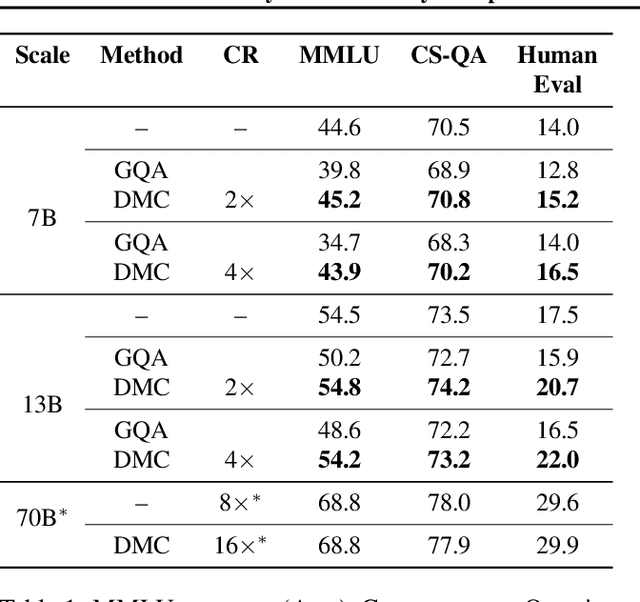
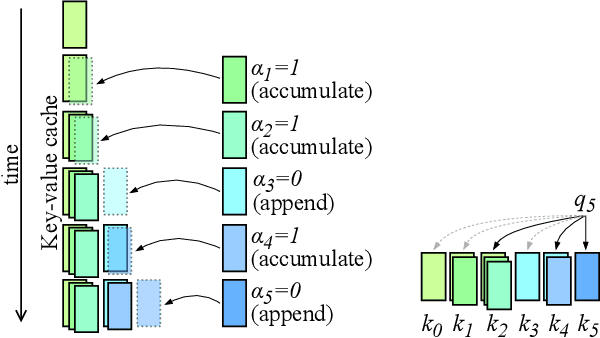

Transformers have emerged as the backbone of large language models (LLMs). However, generation remains inefficient due to the need to store in memory a cache of key-value representations for past tokens, whose size scales linearly with the input sequence length and batch size. As a solution, we propose Dynamic Memory Compression (DMC), a method for on-line key-value cache compression at inference time. Most importantly, the model learns to apply different compression rates in different heads and layers. We retrofit pre-trained LLMs such as Llama 2 (7B, 13B and 70B) into DMC Transformers, achieving up to ~3.7x throughput increase in auto-regressive inference on a NVIDIA H100 GPU. DMC is applied via continued pre-training on a negligible percentage of the original data without adding any extra parameters. We find that DMC preserves the original downstream performance with up to 4x cache compression, outperforming up-trained grouped-query attention (GQA). GQA and DMC can be even combined to obtain compounded gains. As a result DMC fits longer contexts and larger batches within any given memory budget.
Efficient Transformers with Dynamic Token Pooling
Nov 17, 2022Transformers achieve unrivalled performance in modelling language, but remain inefficient in terms of memory and time complexity. A possible remedy is to reduce the sequence length in the intermediate layers by pooling fixed-length segments of tokens. Nevertheless, natural units of meaning, such as words or phrases, display varying sizes. To address this mismatch, we equip language models with a dynamic-pooling mechanism, which predicts segment boundaries in an autoregressive fashion. We compare several methods to infer boundaries, including end-to-end learning through stochastic re-parameterisation, supervised learning (based on segmentations from subword tokenizers or spikes in conditional entropy), as well as linguistically motivated boundaries. We perform character-level evaluation on texts from multiple datasets and morphologically diverse languages. The results demonstrate that dynamic pooling, which jointly segments and models language, is often both faster and more accurate than vanilla Transformers and fixed-length pooling within the same computational budget.
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022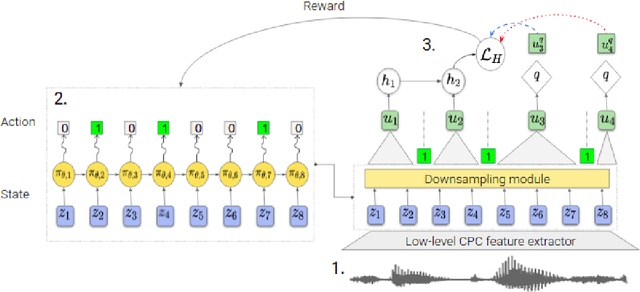
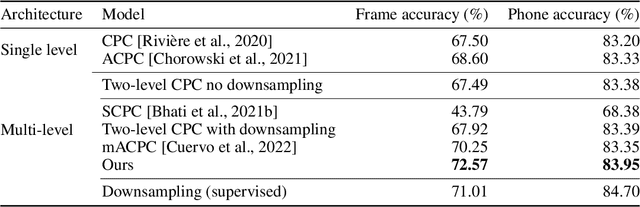


The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Contrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words
Oct 29, 2021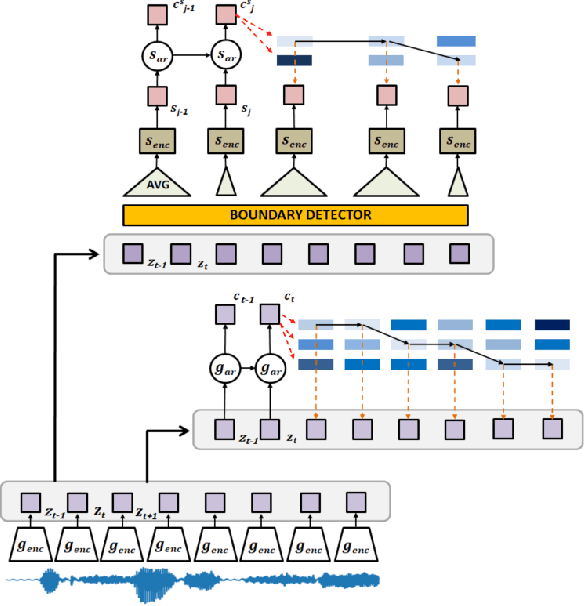
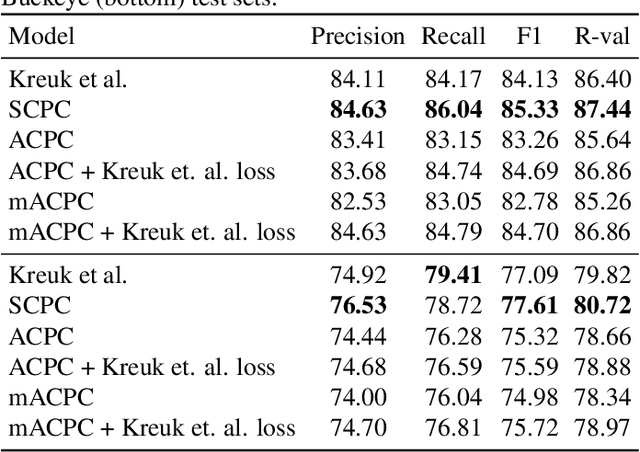
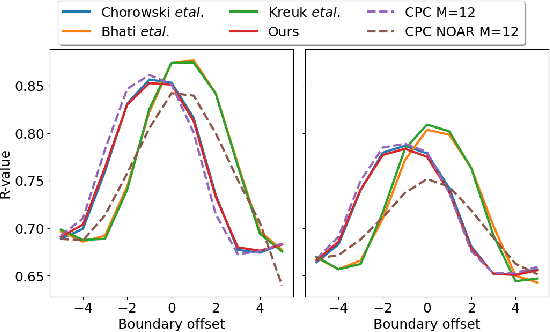
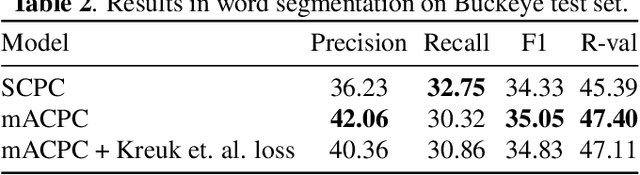
We investigate the performance on phoneme categorization and phoneme and word segmentation of several self-supervised learning (SSL) methods based on Contrastive Predictive Coding (CPC). Our experiments show that with the existing algorithms there is a trade off between categorization and segmentation performance. We investigate the source of this conflict and conclude that the use of context building networks, albeit necessary for superior performance on categorization tasks, harms segmentation performance by causing a temporal shift on the learned representations. Aiming to bridge this gap, we take inspiration from the leading approach on segmentation, which simultaneously models the speech signal at the frame and phoneme level, and incorporate multi-level modelling into Aligned CPC (ACPC), a variation of CPC which exhibits the best performance on categorization tasks. Our multi-level ACPC (mACPC) improves in all categorization metrics and achieves state-of-the-art performance in word segmentation.
Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw
Jun 22, 2021

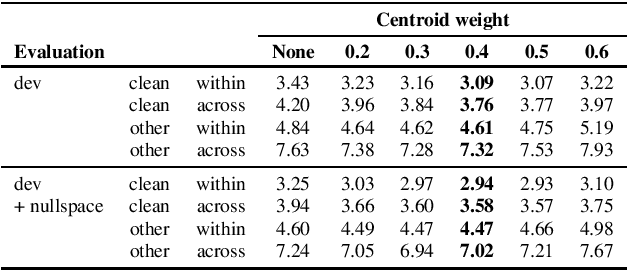
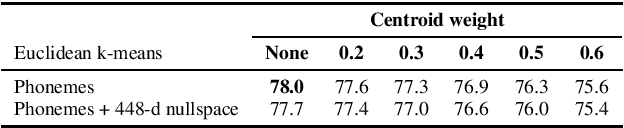
We present a number of low-resource approaches to the tasks of the Zero Resource Speech Challenge 2021. We build on the unsupervised representations of speech proposed by the organizers as a baseline, derived from CPC and clustered with the k-means algorithm. We demonstrate that simple methods of refining those representations can narrow the gap, or even improve upon the solutions which use a high computational budget. The results lead to the conclusion that the CPC-derived representations are still too noisy for training language models, but stable enough for simpler forms of pattern matching and retrieval.
Aligned Contrastive Predictive Coding
Apr 29, 2021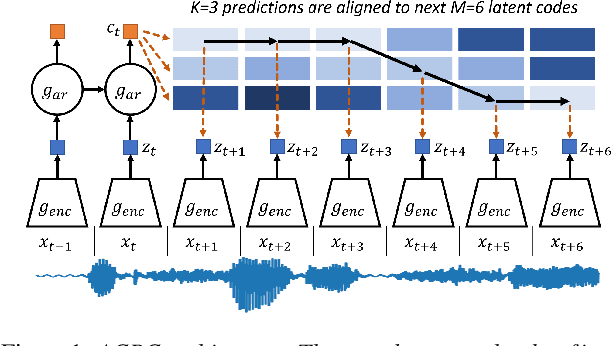

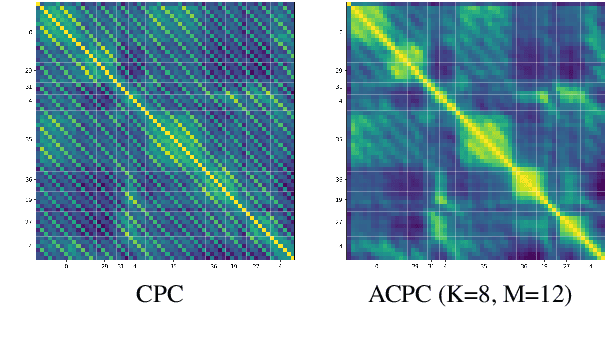
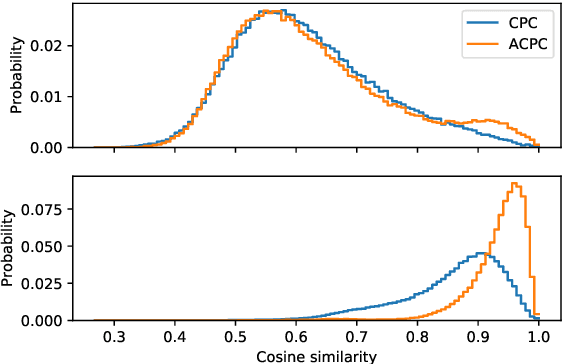
We investigate the possibility of forcing a self-supervised model trained using a contrastive predictive loss to extract slowly varying latent representations. Rather than producing individual predictions for each of the future representations, the model emits a sequence of predictions shorter than that of the upcoming representations to which they will be aligned. In this way, the prediction network solves a simpler task of predicting the next symbols, but not their exact timing, while the encoding network is trained to produce piece-wise constant latent codes. We evaluate the model on a speech coding task and demonstrate that the proposed Aligned Contrastive Predictive Coding (ACPC) leads to higher linear phone prediction accuracy and lower ABX error rates, while being slightly faster to train due to the reduced number of prediction heads.
Named Entity Recognition and Linking Augmented with Large-Scale Structured Data
Apr 27, 2021
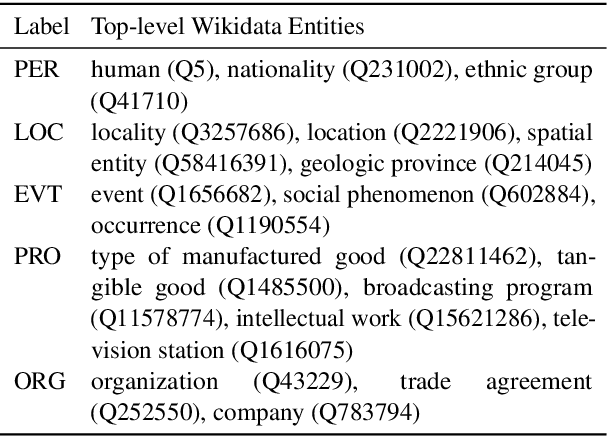
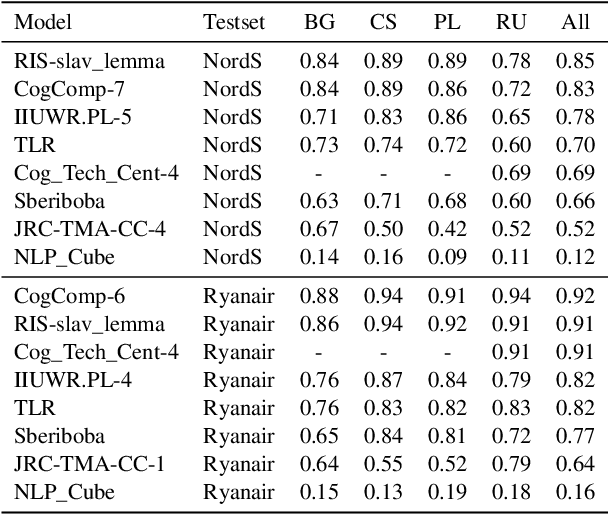
In this paper we describe our submissions to the 2nd and 3rd SlavNER Shared Tasks held at BSNLP 2019 and BSNLP 2021, respectively. The tasks focused on the analysis of Named Entities in multilingual Web documents in Slavic languages with rich inflection. Our solution takes advantage of large collections of both unstructured and structured documents. The former serve as data for unsupervised training of language models and embeddings of lexical units. The latter refers to Wikipedia and its structured counterpart - Wikidata, our source of lemmatization rules, and real-world entities. With the aid of those resources, our system could recognize, normalize and link entities, while being trained with only small amounts of labeled data.
FastPitch: Parallel Text-to-speech with Pitch Prediction
Jun 11, 2020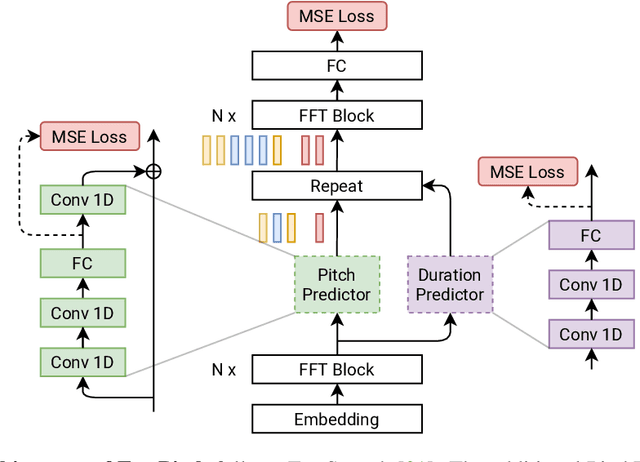
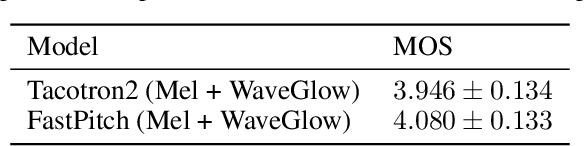
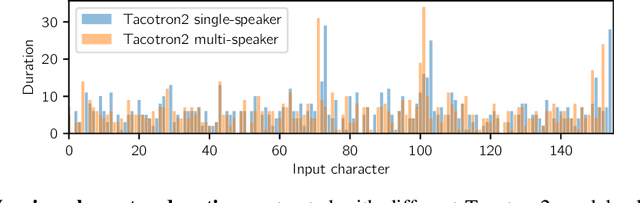

We present FastPitch, a fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference, and generates speech that could be further controlled with predicted contours. FastPitch can thus change the perceived emotional state of the speaker or put emphasis on certain lexical units. We find that uniformly increasing or decreasing the pitch with FastPitch generates speech that resembles the voluntary modulation of voice. Conditioning on frequency contours improves the quality of synthesized speech, making it comparable to state-of-the-art. It does not introduce an overhead, and FastPitch retains the favorable, fully-parallel Transformer architecture of FastSpeech with a similar speed of mel-scale spectrogram synthesis, orders of magnitude faster than real-time.
Robust Training of Vector Quantized Bottleneck Models
May 18, 2020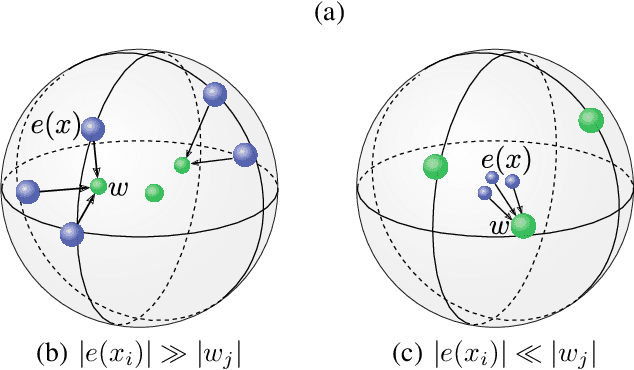
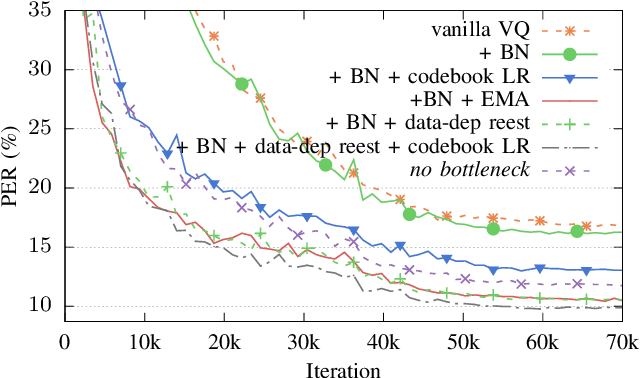
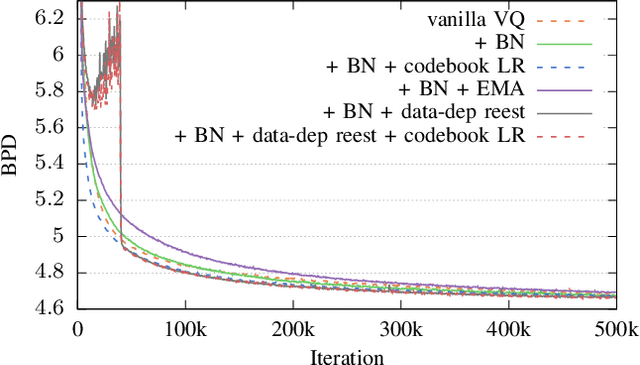

In this paper we demonstrate methods for reliable and efficient training of discrete representation using Vector-Quantized Variational Auto-Encoder models (VQ-VAEs). Discrete latent variable models have been shown to learn nontrivial representations of speech, applicable to unsupervised voice conversion and reaching state-of-the-art performance on unit discovery tasks. For unsupervised representation learning, they became viable alternatives to continuous latent variable models such as the Variational Auto-Encoder (VAE). However, training deep discrete variable models is challenging, due to the inherent non-differentiability of the discretization operation. In this paper we focus on VQ-VAE, a state-of-the-art discrete bottleneck model shown to perform on par with its continuous counterparts. It quantizes encoder outputs with on-line $k$-means clustering. We show that the codebook learning can suffer from poor initialization and non-stationarity of clustered encoder outputs. We demonstrate that these can be successfully overcome by increasing the learning rate for the codebook and periodic date-dependent codeword re-initialization. As a result, we achieve more robust training across different tasks, and significantly increase the usage of latent codewords even for large codebooks. This has practical benefit, for instance, in unsupervised representation learning, where large codebooks may lead to disentanglement of latent representations.