Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition and Linking Augmented with Large-Scale Structured Data
Apr 27, 2021
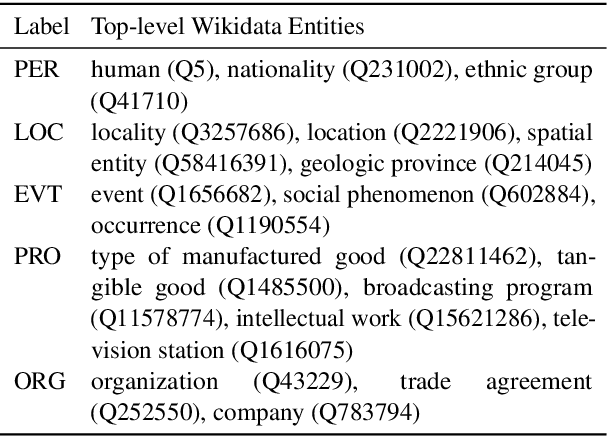
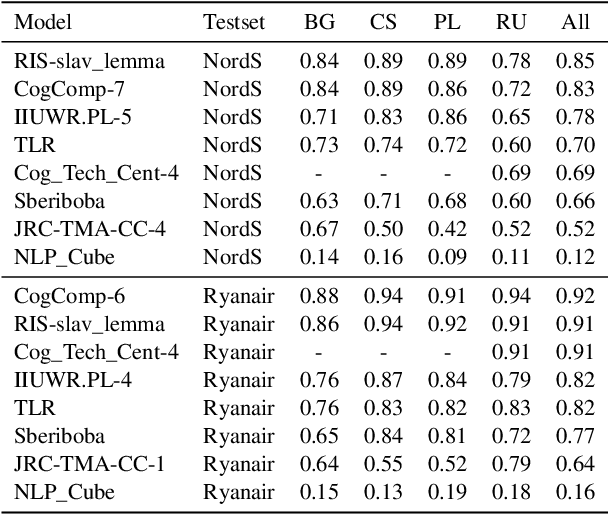
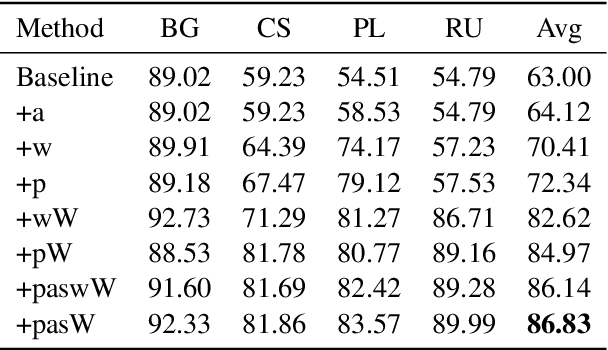
In this paper we describe our submissions to the 2nd and 3rd SlavNER Shared Tasks held at BSNLP 2019 and BSNLP 2021, respectively. The tasks focused on the analysis of Named Entities in multilingual Web documents in Slavic languages with rich inflection. Our solution takes advantage of large collections of both unstructured and structured documents. The former serve as data for unsupervised training of language models and embeddings of lexical units. The latter refers to Wikipedia and its structured counterpart - Wikidata, our source of lemmatization rules, and real-world entities. With the aid of those resources, our system could recognize, normalize and link entities, while being trained with only small amounts of labeled data.
Via