 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastPitch: Parallel Text-to-speech with Pitch Prediction
Paper and Code
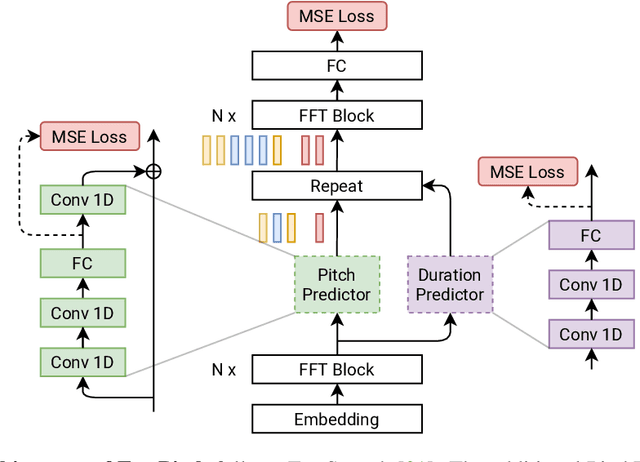
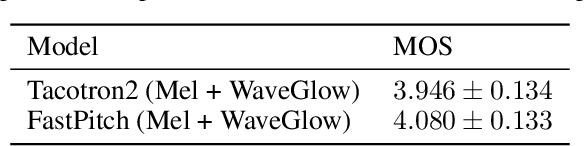
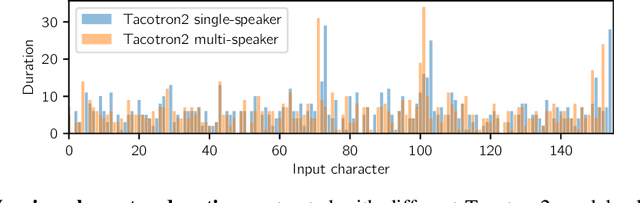

We present FastPitch, a fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference, and generates speech that could be further controlled with predicted contours. FastPitch can thus change the perceived emotional state of the speaker or put emphasis on certain lexical units. We find that uniformly increasing or decreasing the pitch with FastPitch generates speech that resembles the voluntary modulation of voice. Conditioning on frequency contours improves the quality of synthesized speech, making it comparable to state-of-the-art. It does not introduce an overhead, and FastPitch retains the favorable, fully-parallel Transformer architecture of FastSpeech with a similar speed of mel-scale spectrogram synthesis, orders of magnitude faster than real-time.