 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words
Oct 29, 2021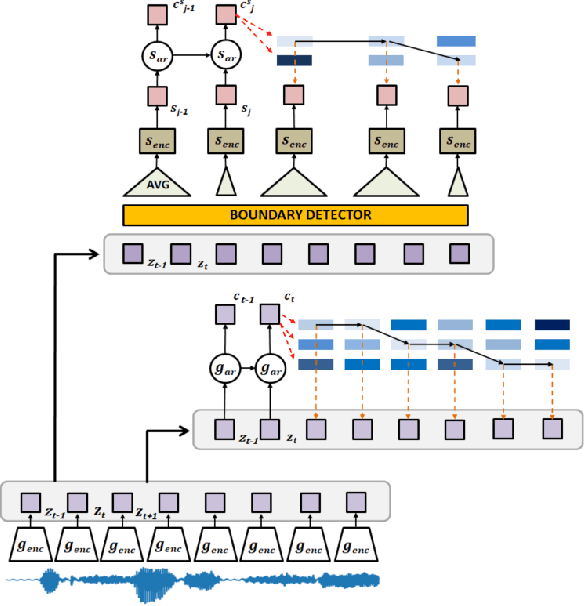
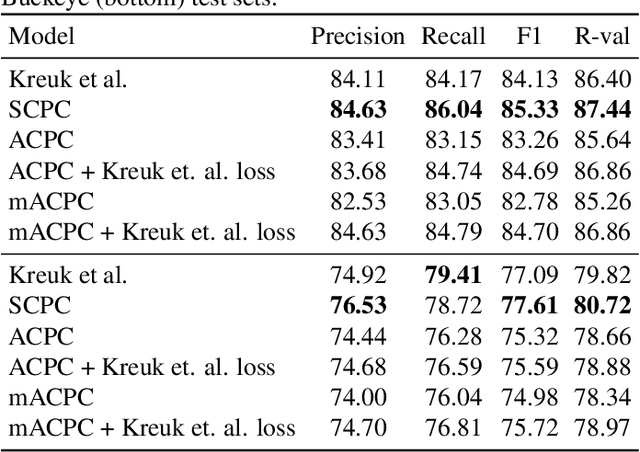
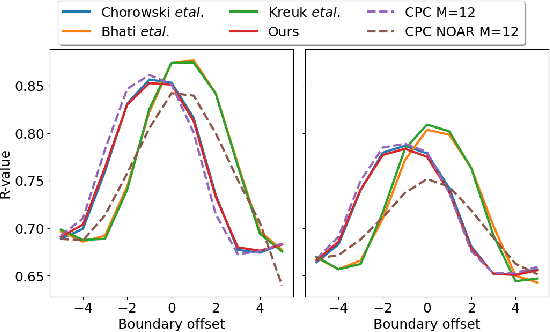
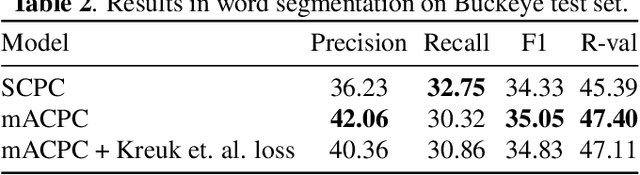
We investigate the performance on phoneme categorization and phoneme and word segmentation of several self-supervised learning (SSL) methods based on Contrastive Predictive Coding (CPC). Our experiments show that with the existing algorithms there is a trade off between categorization and segmentation performance. We investigate the source of this conflict and conclude that the use of context building networks, albeit necessary for superior performance on categorization tasks, harms segmentation performance by causing a temporal shift on the learned representations. Aiming to bridge this gap, we take inspiration from the leading approach on segmentation, which simultaneously models the speech signal at the frame and phoneme level, and incorporate multi-level modelling into Aligned CPC (ACPC), a variation of CPC which exhibits the best performance on categorization tasks. Our multi-level ACPC (mACPC) improves in all categorization metrics and achieves state-of-the-art performance in word segmentation.
Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw
Jun 22, 2021

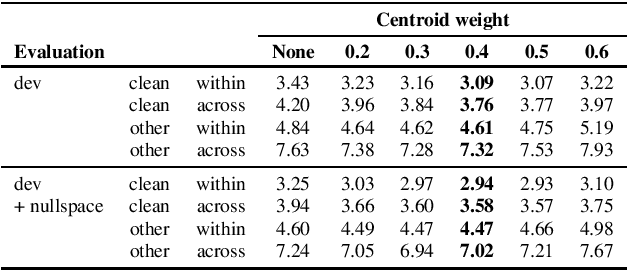
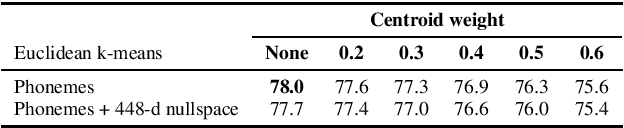
We present a number of low-resource approaches to the tasks of the Zero Resource Speech Challenge 2021. We build on the unsupervised representations of speech proposed by the organizers as a baseline, derived from CPC and clustered with the k-means algorithm. We demonstrate that simple methods of refining those representations can narrow the gap, or even improve upon the solutions which use a high computational budget. The results lead to the conclusion that the CPC-derived representations are still too noisy for training language models, but stable enough for simpler forms of pattern matching and retrieval.
Aligned Contrastive Predictive Coding
Apr 29, 2021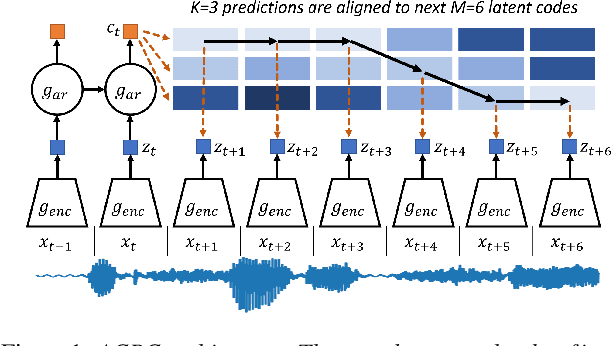

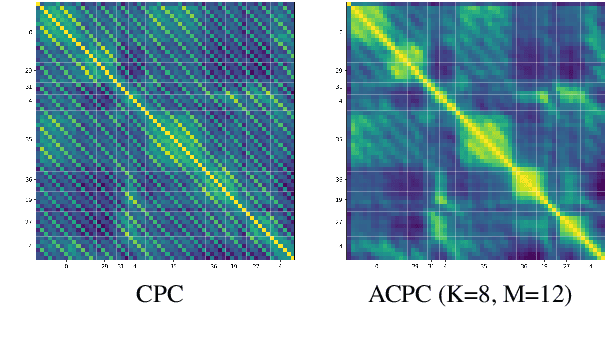
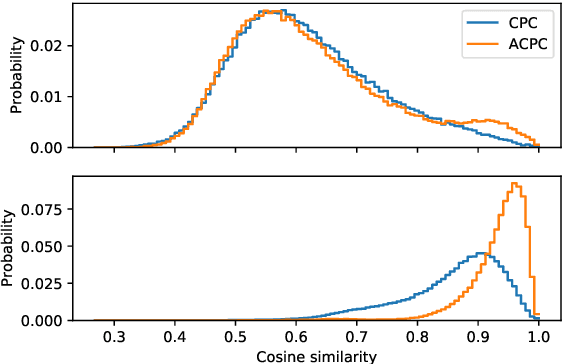
We investigate the possibility of forcing a self-supervised model trained using a contrastive predictive loss to extract slowly varying latent representations. Rather than producing individual predictions for each of the future representations, the model emits a sequence of predictions shorter than that of the upcoming representations to which they will be aligned. In this way, the prediction network solves a simpler task of predicting the next symbols, but not their exact timing, while the encoding network is trained to produce piece-wise constant latent codes. We evaluate the model on a speech coding task and demonstrate that the proposed Aligned Contrastive Predictive Coding (ACPC) leads to higher linear phone prediction accuracy and lower ABX error rates, while being slightly faster to train due to the reduced number of prediction heads.