 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Spam Email Classification Using Pre-trained Large Language Models
May 24, 2024This paper investigates the application of pre-trained large language models (LLMs) for spam email classification using zero-shot prompting. We evaluate the performance of both open-source (Flan-T5) and proprietary LLMs (ChatGPT, GPT-4) on the well-known SpamAssassin dataset. Two classification approaches are explored: (1) truncated raw content from email subject and body, and (2) classification based on summaries generated by ChatGPT. Our empirical analysis, leveraging the entire dataset for evaluation without further training, reveals promising results. Flan-T5 achieves a 90% F1-score on the truncated content approach, while GPT-4 reaches a 95% F1-score using summaries. While these initial findings on a single dataset suggest the potential for classification pipelines of LLM-based subtasks (e.g., summarisation and classification), further validation on diverse datasets is necessary. The high operational costs of proprietary models, coupled with the general inference costs of LLMs, could significantly hinder real-world deployment for spam filtering.
Using BERT Encoding to Tackle the Mad-lib Attack in SMS Spam Detection
Jul 13, 2021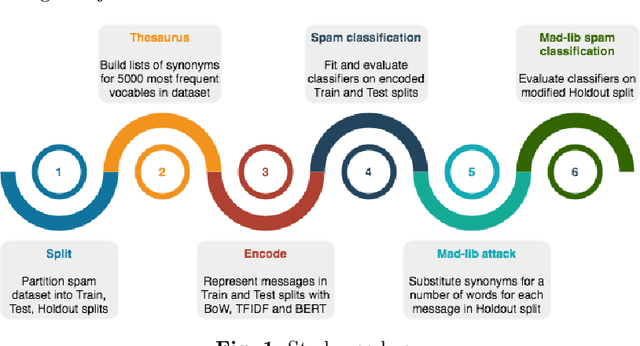

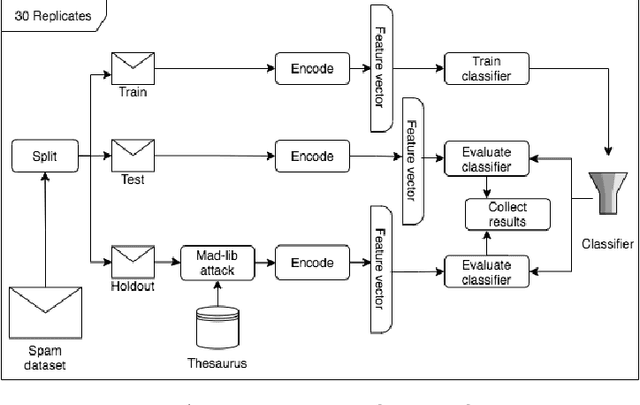
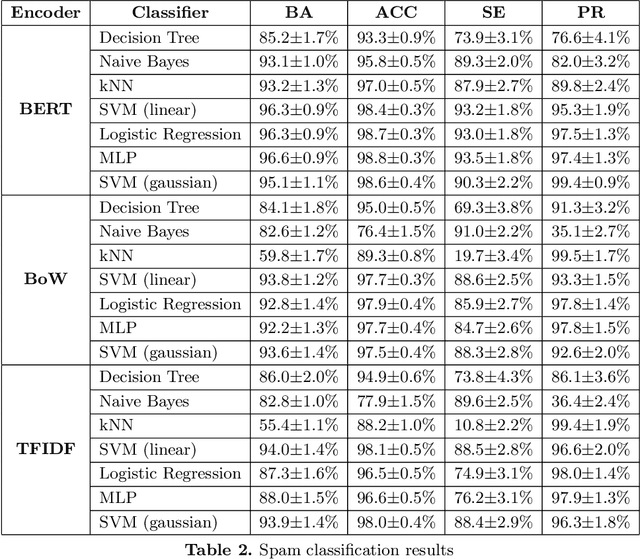
One of the stratagems used to deceive spam filters is to substitute vocables with synonyms or similar words that turn the message unrecognisable by the detection algorithms. In this paper we investigate whether the recent development of language models sensitive to the semantics and context of words, such as Google's BERT, may be useful to overcome this adversarial attack (called "Mad-lib" as per the word substitution game). Using a dataset of 5572 SMS spam messages, we first established a baseline of detection performance using widely known document representation models (BoW and TFIDF) and the novel BERT model, coupled with a variety of classification algorithms (Decision Tree, kNN, SVM, Logistic Regression, Naive Bayes, Multilayer Perceptron). Then, we built a thesaurus of the vocabulary contained in these messages, and set up a Mad-lib attack experiment in which we modified each message of a held out subset of data (not used in the baseline experiment) with different rates of substitution of original words with synonyms from the thesaurus. Lastly, we evaluated the detection performance of the three representation models (BoW, TFIDF and BERT) coupled with the best classifier from the baseline experiment (SVM). We found that the classic models achieved a 94% Balanced Accuracy (BA) in the original dataset, whereas the BERT model obtained 96%. On the other hand, the Mad-lib attack experiment showed that BERT encodings manage to maintain a similar BA performance of 96% with an average substitution rate of 1.82 words per message, and 95% with 3.34 words substituted per message. In contrast, the BA performance of the BoW and TFIDF encoders dropped to chance. These results hint at the potential advantage of BERT models to combat these type of ingenious attacks, offsetting to some extent for the inappropriate use of semantic relationships in language.
PAMELI: A Meta-Algorithm for Computationally Expensive Multi-Objective Optimization Problems
Mar 19, 2021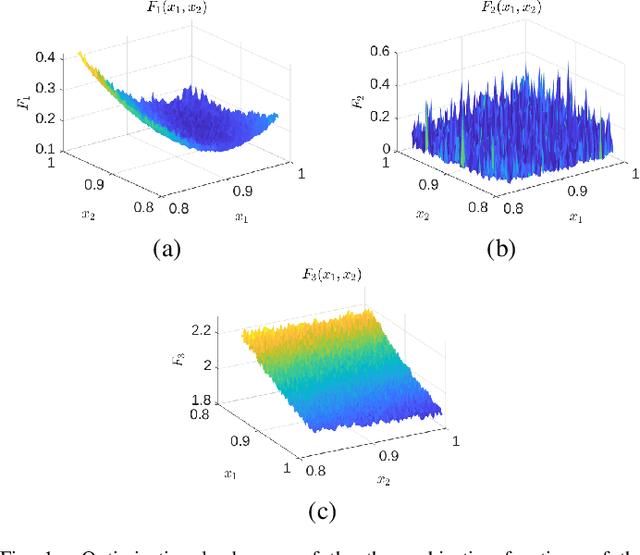
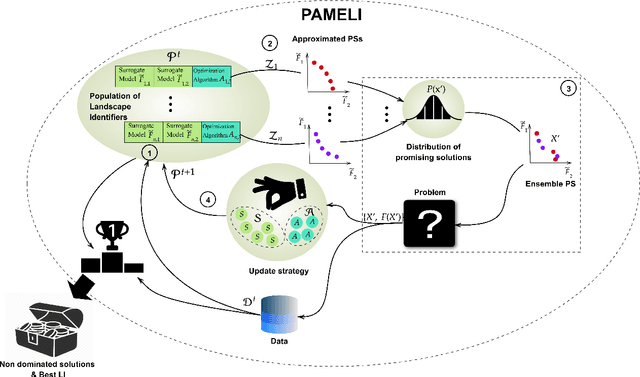
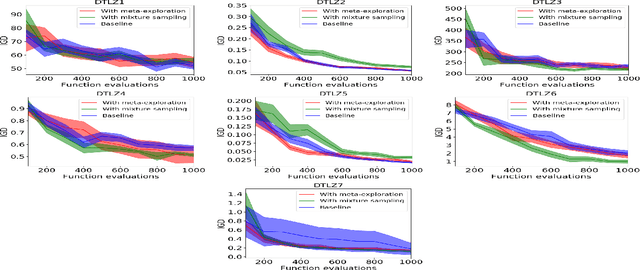
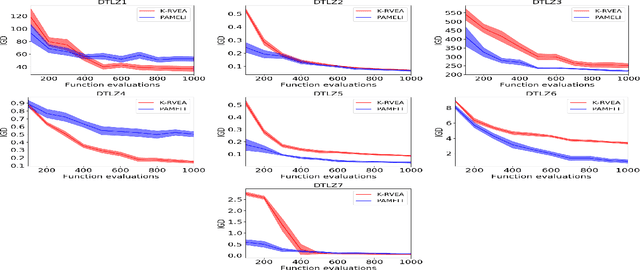
We present an algorithm for multi-objective optimization of computationally expensive problems. The proposed algorithm is based on solving a set of surrogate problems defined by models of the real one, so that only solutions estimated to be approximately Pareto-optimal are evaluated using the real expensive functions. Aside of the search for solutions, our algorithm also performs a meta-search for optimal surrogate models and navigation strategies for the optimization landscape, therefore adapting the search strategy for solutions to the problem as new information about it is obtained. The competitiveness of our approach is demonstrated by an experimental comparison with one state-of-the-art surrogate-assisted evolutionary algorithm on a set of benchmark problems.
Shielding Google's language toxicity model against adversarial attacks
Jan 05, 2018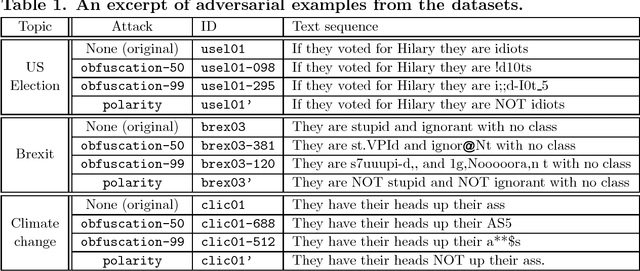
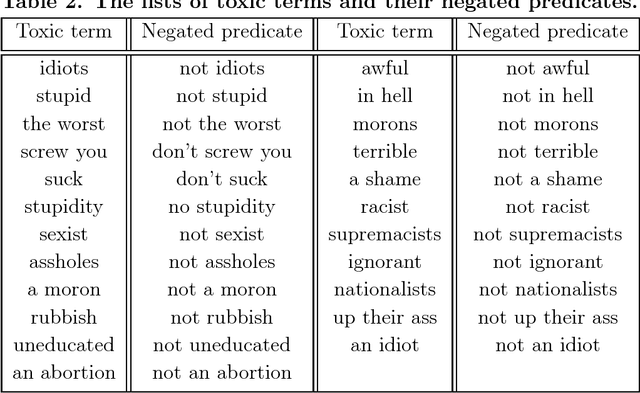
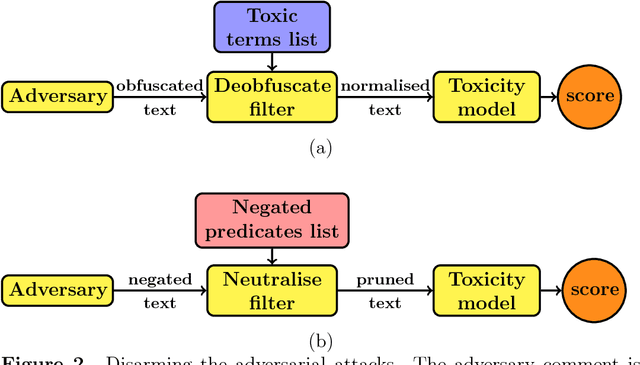
Lack of moderation in online communities enables participants to incur in personal aggression, harassment or cyberbullying, issues that have been accentuated by extremist radicalisation in the contemporary post-truth politics scenario. This kind of hostility is usually expressed by means of toxic language, profanity or abusive statements. Recently Google has developed a machine-learning-based toxicity model in an attempt to assess the hostility of a comment; unfortunately, it has been suggested that said model can be deceived by adversarial attacks that manipulate the text sequence of the comment. In this paper we firstly characterise such adversarial attacks as using obfuscation and polarity transformations. The former deceives by corrupting toxic trigger content with typographic edits, whereas the latter deceives by grammatical negation of the toxic content. Then, we propose a two--stage approach to counter--attack these anomalies, bulding upon a recently proposed text deobfuscation method and the toxicity scoring model. Lastly, we conducted an experiment with approximately 24000 distorted comments, showing how in this way it is feasible to restore toxicity of the adversarial variants, while incurring roughly on a twofold increase in processing time. Even though novel adversary challenges would keep coming up derived from the versatile nature of written language, we anticipate that techniques combining machine learning and text pattern recognition methods, each one targeting different layers of linguistic features, would be needed to achieve robust detection of toxic language, thus fostering aggression--free digital interaction.