 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShielding Google's language toxicity model against adversarial attacks
Paper and Code
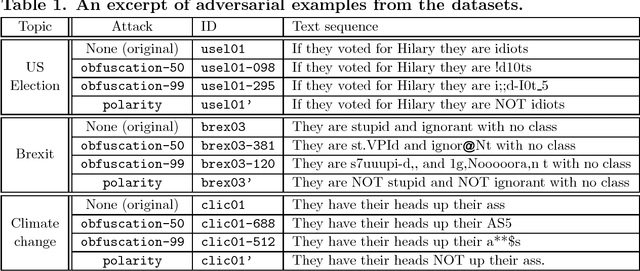
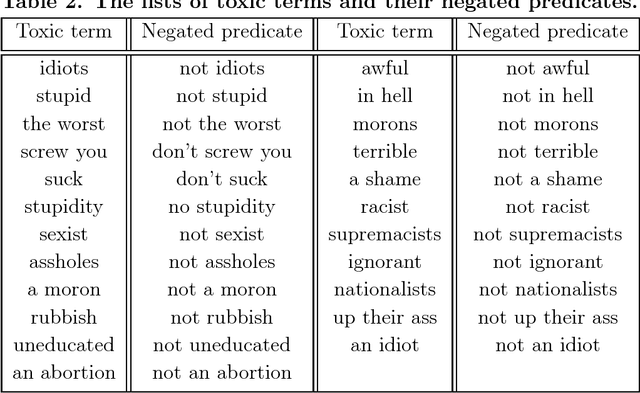
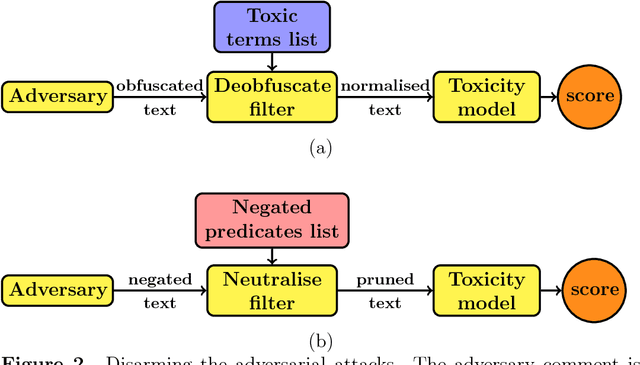
Lack of moderation in online communities enables participants to incur in personal aggression, harassment or cyberbullying, issues that have been accentuated by extremist radicalisation in the contemporary post-truth politics scenario. This kind of hostility is usually expressed by means of toxic language, profanity or abusive statements. Recently Google has developed a machine-learning-based toxicity model in an attempt to assess the hostility of a comment; unfortunately, it has been suggested that said model can be deceived by adversarial attacks that manipulate the text sequence of the comment. In this paper we firstly characterise such adversarial attacks as using obfuscation and polarity transformations. The former deceives by corrupting toxic trigger content with typographic edits, whereas the latter deceives by grammatical negation of the toxic content. Then, we propose a two--stage approach to counter--attack these anomalies, bulding upon a recently proposed text deobfuscation method and the toxicity scoring model. Lastly, we conducted an experiment with approximately 24000 distorted comments, showing how in this way it is feasible to restore toxicity of the adversarial variants, while incurring roughly on a twofold increase in processing time. Even though novel adversary challenges would keep coming up derived from the versatile nature of written language, we anticipate that techniques combining machine learning and text pattern recognition methods, each one targeting different layers of linguistic features, would be needed to achieve robust detection of toxic language, thus fostering aggression--free digital interaction.