 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing BERT Encoding to Tackle the Mad-lib Attack in SMS Spam Detection
Paper and Code
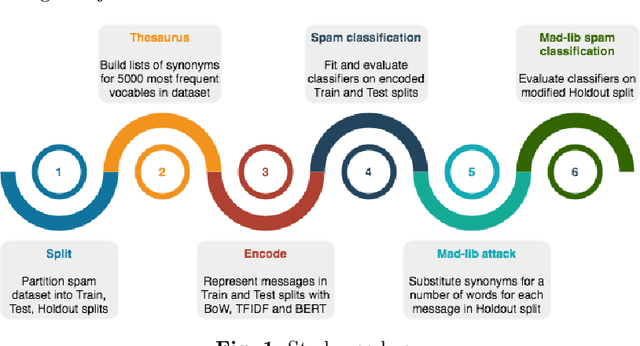

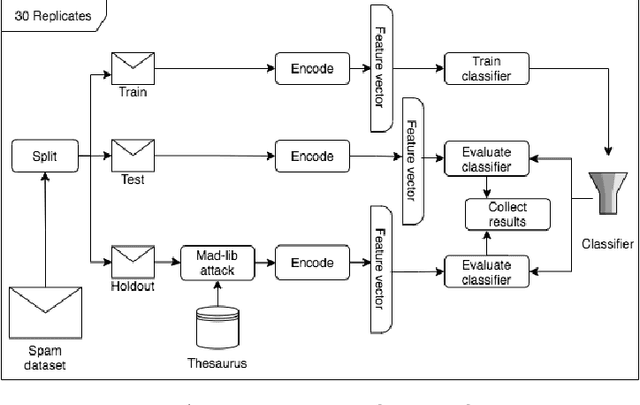
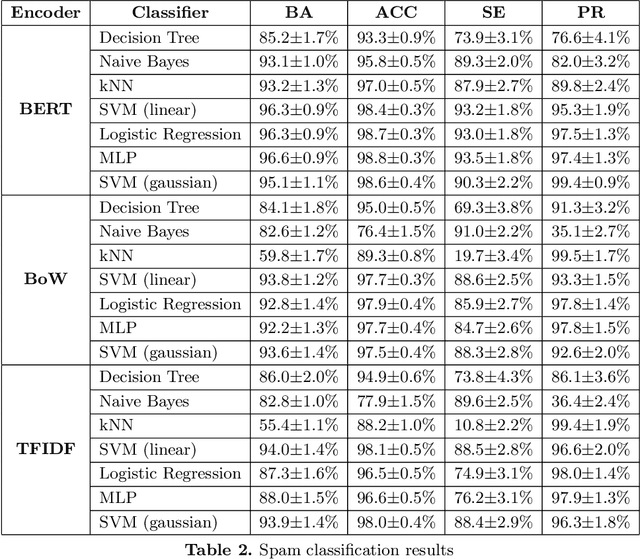
One of the stratagems used to deceive spam filters is to substitute vocables with synonyms or similar words that turn the message unrecognisable by the detection algorithms. In this paper we investigate whether the recent development of language models sensitive to the semantics and context of words, such as Google's BERT, may be useful to overcome this adversarial attack (called "Mad-lib" as per the word substitution game). Using a dataset of 5572 SMS spam messages, we first established a baseline of detection performance using widely known document representation models (BoW and TFIDF) and the novel BERT model, coupled with a variety of classification algorithms (Decision Tree, kNN, SVM, Logistic Regression, Naive Bayes, Multilayer Perceptron). Then, we built a thesaurus of the vocabulary contained in these messages, and set up a Mad-lib attack experiment in which we modified each message of a held out subset of data (not used in the baseline experiment) with different rates of substitution of original words with synonyms from the thesaurus. Lastly, we evaluated the detection performance of the three representation models (BoW, TFIDF and BERT) coupled with the best classifier from the baseline experiment (SVM). We found that the classic models achieved a 94% Balanced Accuracy (BA) in the original dataset, whereas the BERT model obtained 96%. On the other hand, the Mad-lib attack experiment showed that BERT encodings manage to maintain a similar BA performance of 96% with an average substitution rate of 1.82 words per message, and 95% with 3.34 words substituted per message. In contrast, the BA performance of the BoW and TFIDF encoders dropped to chance. These results hint at the potential advantage of BERT models to combat these type of ingenious attacks, offsetting to some extent for the inappropriate use of semantic relationships in language.