 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Corpus Training in SSL-Based Anti-Spoofing Models: Domain-Invariant Feature Extraction
Mar 19, 2026The performance of speech spoofing detection often varies across different training and evaluation corpora. Leveraging multiple corpora typically enhances robustness and performance in fields like speaker recognition and speech recognition. However, our spoofing detection experiments show that multi-corpus training does not consistently improve performance and may even degrade it. We hypothesize that dataset-specific biases impair generalization, leading to performance instability. To address this, we propose an Invariant Domain Feature Extraction (IDFE) framework, employing multi-task learning and a gradient reversal layer to minimize corpus-specific information in learned embeddings. The IDFE framework reduces the average equal error rate by 20% compared to the baseline, assessed across four varied datasets.
Text-Speech Language Models with Improved Cross-Modal Transfer by Aligning Abstraction Levels
Mar 08, 2025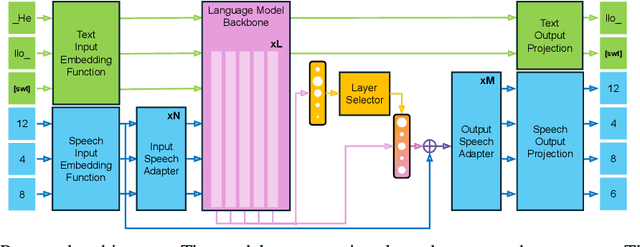
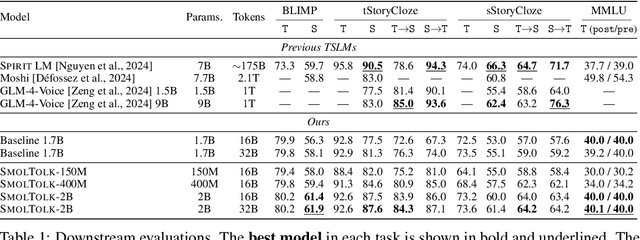
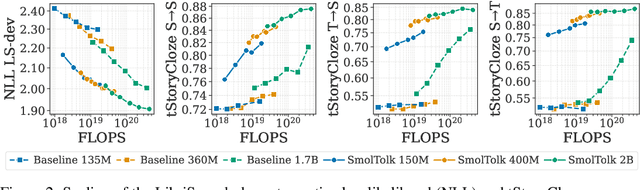
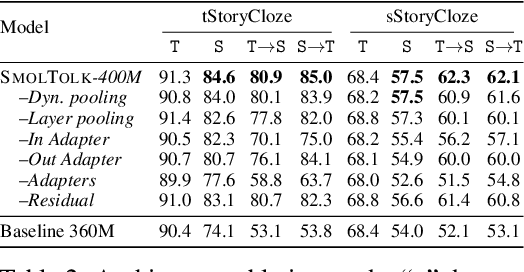
Text-Speech Language Models (TSLMs) -- language models trained to jointly process and generate text and speech -- aim to enable cross-modal knowledge transfer to overcome the scaling limitations of unimodal speech LMs. The predominant approach to TSLM training expands the vocabulary of a pre-trained text LM by appending new embeddings and linear projections for speech, followed by fine-tuning on speech data. We hypothesize that this method limits cross-modal transfer by neglecting feature compositionality, preventing text-learned functions from being fully leveraged at appropriate abstraction levels. To address this, we propose augmenting vocabulary expansion with modules that better align abstraction levels across layers. Our models, \textsc{SmolTolk}, rival or surpass state-of-the-art TSLMs trained with orders of magnitude more compute. Representation analyses and improved multimodal performance suggest our method enhances cross-modal transfer.
A Benchmark of French ASR Systems Based on Error Severity
Jan 18, 2025

Automatic Speech Recognition (ASR) transcription errors are commonly assessed using metrics that compare them with a reference transcription, such as Word Error Rate (WER), which measures spelling deviations from the reference, or semantic score-based metrics. However, these approaches often overlook what is understandable to humans when interpreting transcription errors. To address this limitation, a new evaluation is proposed that categorizes errors into four levels of severity, further divided into subtypes, based on objective linguistic criteria, contextual patterns, and the use of content words as the unit of analysis. This metric is applied to a benchmark of 10 state-of-the-art ASR systems on French language, encompassing both HMM-based and end-to-end models. Our findings reveal the strengths and weaknesses of each system, identifying those that provide the most comfortable reading experience for users.
MSP-Podcast SER Challenge 2024: L'antenne du Ventoux Multimodal Self-Supervised Learning for Speech Emotion Recognition
Jul 08, 2024



In this work, we detail our submission to the 2024 edition of the MSP-Podcast Speech Emotion Recognition (SER) Challenge. This challenge is divided into two distinct tasks: Categorical Emotion Recognition and Emotional Attribute Prediction. We concentrated our efforts on Task 1, which involves the categorical classification of eight emotional states using data from the MSP-Podcast dataset. Our approach employs an ensemble of models, each trained independently and then fused at the score level using a Support Vector Machine (SVM) classifier. The models were trained using various strategies, including Self-Supervised Learning (SSL) fine-tuning across different modalities: speech alone, text alone, and a combined speech and text approach. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. This joint training methodology aims to enhance the system's ability to accurately classify emotional states. Thus, the system obtained F1-macro of 0.35\% on development set.
Zero-Shot End-To-End Spoken Question Answering In Medical Domain
Jun 09, 2024In the rapidly evolving landscape of spoken question-answering (SQA), the integration of large language models (LLMs) has emerged as a transformative development. Conventional approaches often entail the use of separate models for question audio transcription and answer selection, resulting in significant resource utilization and error accumulation. To tackle these challenges, we explore the effectiveness of end-to-end (E2E) methodologies for SQA in the medical domain. Our study introduces a novel zero-shot SQA approach, compared to traditional cascade systems. Through a comprehensive evaluation conducted on a new open benchmark of 8 medical tasks and 48 hours of synthetic audio, we demonstrate that our approach requires up to 14.7 times fewer resources than a combined 1.3B parameters LLM with a 1.55B parameters ASR model while improving average accuracy by 0.5\%. These findings underscore the potential of E2E methodologies for SQA in resource-constrained contexts.
* Accepted to INTERSPEECH 2024
Asymmetric and trial-dependent modeling: the contribution of LIA to SdSV Challenge Task 2
Mar 28, 2024
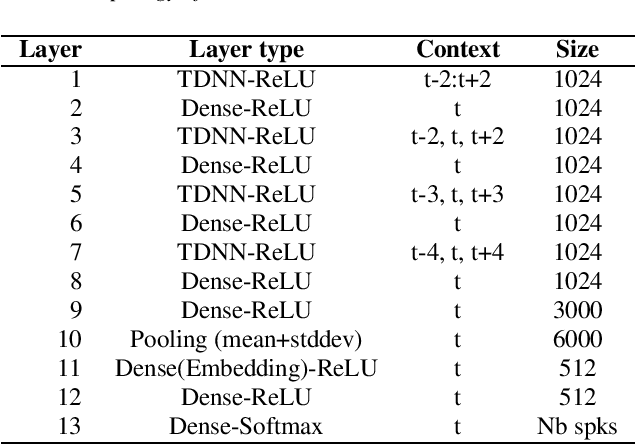

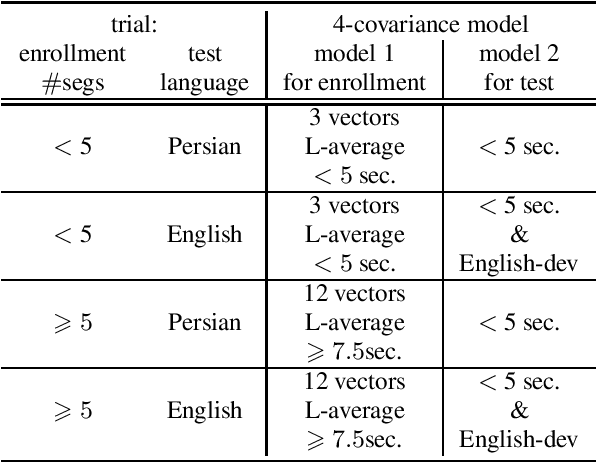
The SdSv challenge Task 2 provided an opportunity to assess efficiency and robustness of modern text-independent speaker verification systems. But it also made it possible to test new approaches, capable of taking into account the main issues of this challenge (duration, language, ...). This paper describes the contributions of our laboratory to the speaker recognition field. These contributions highlight two other challenges in addition to short-duration and language: the mismatch between enrollment and test data and the one between subsets of the evaluation trial dataset. The proposed approaches experimentally show their relevance and efficiency on the SdSv evaluation, and could be of interest in many real-life applications.
Probing the Information Encoded in Neural-based Acoustic Models of Automatic Speech Recognition Systems
Feb 29, 2024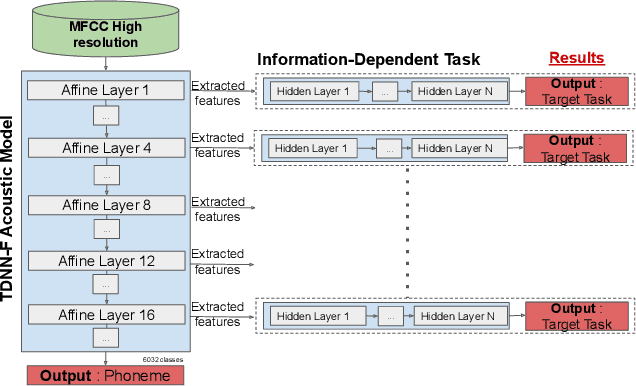
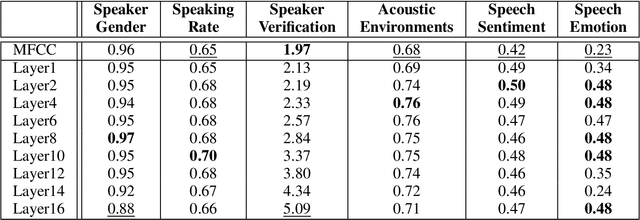
Deep learning architectures have made significant progress in terms of performance in many research areas. The automatic speech recognition (ASR) field has thus benefited from these scientific and technological advances, particularly for acoustic modeling, now integrating deep neural network architectures. However, these performance gains have translated into increased complexity regarding the information learned and conveyed through these black-box architectures. Following many researches in neural networks interpretability, we propose in this article a protocol that aims to determine which and where information is located in an ASR acoustic model (AM). To do so, we propose to evaluate AM performance on a determined set of tasks using intermediate representations (here, at different layer levels). Regarding the performance variation and targeted tasks, we can emit hypothesis about which information is enhanced or perturbed at different architecture steps. Experiments are performed on both speaker verification, acoustic environment classification, gender classification, tempo-distortion detection systems and speech sentiment/emotion identification. Analysis showed that neural-based AMs hold heterogeneous information that seems surprisingly uncorrelated with phoneme recognition, such as emotion, sentiment or speaker identity. The low-level hidden layers globally appears useful for the structuring of information while the upper ones would tend to delete useless information for phoneme recognition.
How Important Is Tokenization in French Medical Masked Language Models?
Feb 22, 2024Subword tokenization has become the prevailing standard in the field of natural language processing (NLP) over recent years, primarily due to the widespread utilization of pre-trained language models. This shift began with Byte-Pair Encoding (BPE) and was later followed by the adoption of SentencePiece and WordPiece. While subword tokenization consistently outperforms character and word-level tokenization, the precise factors contributing to its success remain unclear. Key aspects such as the optimal segmentation granularity for diverse tasks and languages, the influence of data sources on tokenizers, and the role of morphological information in Indo-European languages remain insufficiently explored. This is particularly pertinent for biomedical terminology, characterized by specific rules governing morpheme combinations. Despite the agglutinative nature of biomedical terminology, existing language models do not explicitly incorporate this knowledge, leading to inconsistent tokenization strategies for common terms. In this paper, we seek to delve into the complexities of subword tokenization in French biomedical domain across a variety of NLP tasks and pinpoint areas where further enhancements can be made. We analyze classical tokenization algorithms, including BPE and SentencePiece, and introduce an original tokenization strategy that integrates morpheme-enriched word segmentation into existing tokenization methods.
DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical Domain
Feb 20, 2024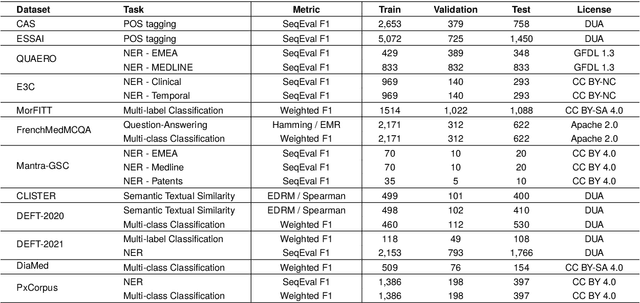
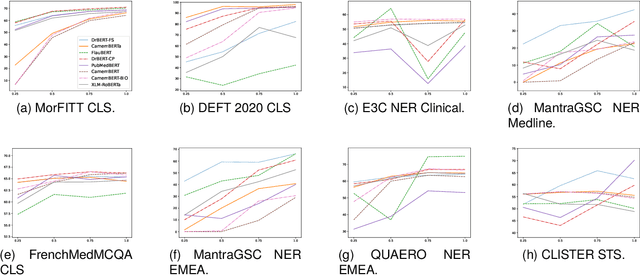
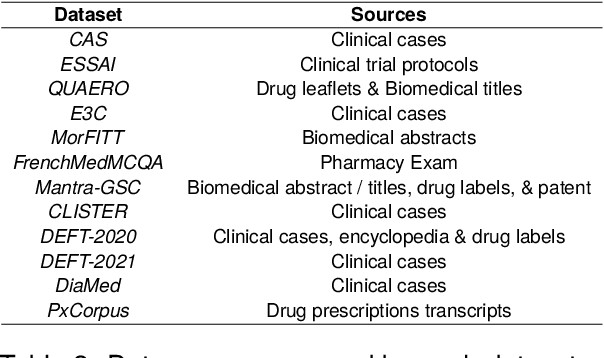
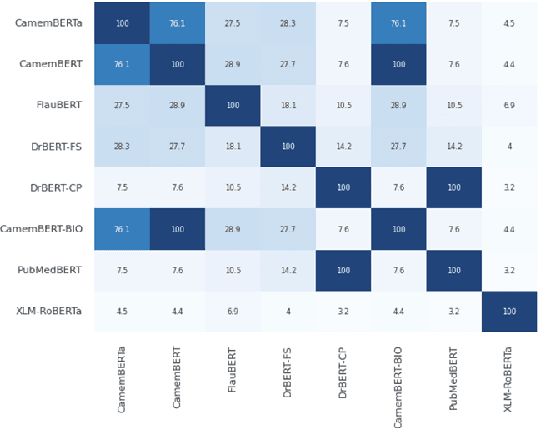
The biomedical domain has sparked a significant interest in the field of Natural Language Processing (NLP), which has seen substantial advancements with pre-trained language models (PLMs). However, comparing these models has proven challenging due to variations in evaluation protocols across different models. A fair solution is to aggregate diverse downstream tasks into a benchmark, allowing for the assessment of intrinsic PLMs qualities from various perspectives. Although still limited to few languages, this initiative has been undertaken in the biomedical field, notably English and Chinese. This limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. To bridge this research gap and account for the unique sensitivities of French, we present the first-ever publicly available French biomedical language understanding benchmark called DrBenchmark. It encompasses 20 diversified tasks, including named-entity recognition, part-of-speech tagging, question-answering, semantic textual similarity, and classification. We evaluate 8 state-of-the-art pre-trained masked language models (MLMs) on general and biomedical-specific data, as well as English specific MLMs to assess their cross-lingual capabilities. Our experiments reveal that no single model excels across all tasks, while generalist models are sometimes still competitive.
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Feb 15, 2024



Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges. In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.