 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgro-STAY : Collecte de données et analyse des informations en agriculture alternative issues de YouTube
Dec 13, 2024To address the current crises (climatic, social, economic), the self-sufficiency -- a set of practices that combine energy sobriety, self-production of food and energy, and self-construction - arouses an increasing interest. The CNRS STAY project (Savoirs Techniques pour l'Auto-suffisance, sur YouTube) explores this topic by analyzing techniques shared on YouTube. We present Agro-STAY, a platform designed for the collection, processing, and visualization of data from YouTube videos and their comments. We use Natural Language Processing (NLP) techniques and language models, which enable a fine-grained analysis of alternative agricultural practice described online. -- Face aux crises actuelles (climatiques, sociales, \'economiques), l'auto-suffisance -- ensemble de pratiques combinant sobri\'et\'e \'energ\'etique, autoproduction alimentaire et \'energ\'etique et autoconstruction - suscite un int\'er\^et croissant. Le projet CNRS STAY (Savoirs Techniques pour l'Auto-suffisance, sur YouTube) s'inscrit dans ce domaine en analysant les savoirs techniques diffus\'es sur YouTube. Nous pr\'esentons Agro-STAY, une plateforme d\'edi\'ee \`a la collecte, au traitement et \`a la visualisation de donn\'ees issues de vid\'eos YouTube et de leurs commentaires. En mobilisant des techniques de traitement automatique des langues (TAL) et des mod\`eles de langues, ce travail permet une analyse fine des pratiques agricoles alternatives d\'ecrites en ligne.
DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical Domain
Feb 20, 2024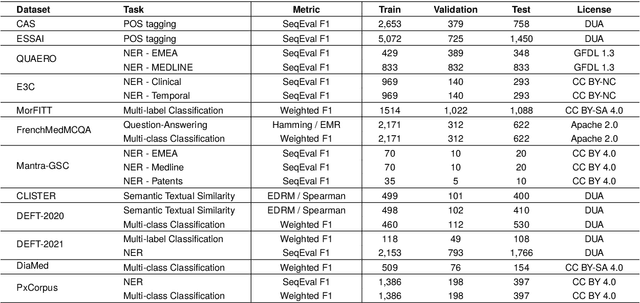
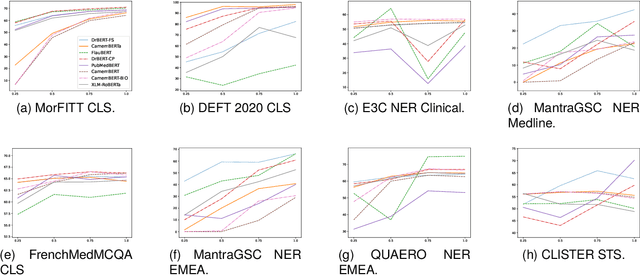
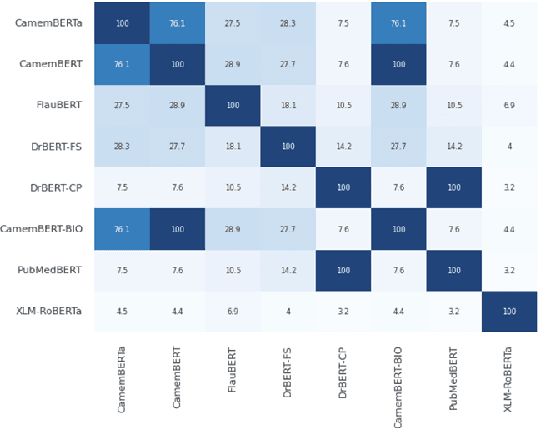
The biomedical domain has sparked a significant interest in the field of Natural Language Processing (NLP), which has seen substantial advancements with pre-trained language models (PLMs). However, comparing these models has proven challenging due to variations in evaluation protocols across different models. A fair solution is to aggregate diverse downstream tasks into a benchmark, allowing for the assessment of intrinsic PLMs qualities from various perspectives. Although still limited to few languages, this initiative has been undertaken in the biomedical field, notably English and Chinese. This limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. To bridge this research gap and account for the unique sensitivities of French, we present the first-ever publicly available French biomedical language understanding benchmark called DrBenchmark. It encompasses 20 diversified tasks, including named-entity recognition, part-of-speech tagging, question-answering, semantic textual similarity, and classification. We evaluate 8 state-of-the-art pre-trained masked language models (MLMs) on general and biomedical-specific data, as well as English specific MLMs to assess their cross-lingual capabilities. Our experiments reveal that no single model excels across all tasks, while generalist models are sometimes still competitive.