 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Gender Stereotypes in Large Language Models via Social Determinants of Health
Mar 10, 2026Large Language Models (LLMs) excel in Natural Language Processing (NLP) tasks, but they often propagate biases embedded in their training data, which is potentially impactful in sensitive domains like healthcare. While existing benchmarks evaluate biases related to individual social determinants of health (SDoH) such as gender or ethnicity, they often overlook interactions between these factors and lack context-specific assessments. This study investigates bias in LLMs by probing the relationships between gender and other SDoH in French patient records. Through a series of experiments, we found that embedded stereotypes can be probed using SDoH input and that LLMs rely on embedded stereotypes to make gendered decisions, suggesting that evaluating interactions among SDoH factors could usefully complement existing approaches to assessing LLM performance and bias.
Summarization for Generative Relation Extraction in the Microbiome Domain
Jun 10, 2025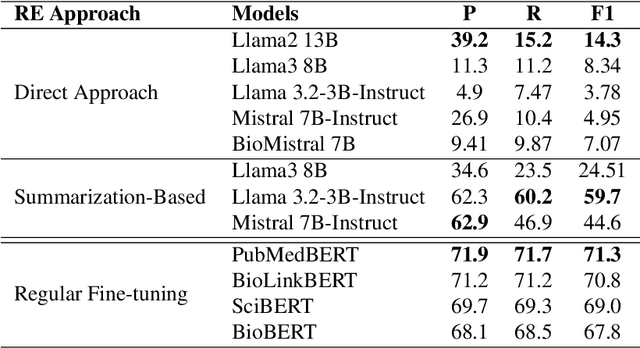
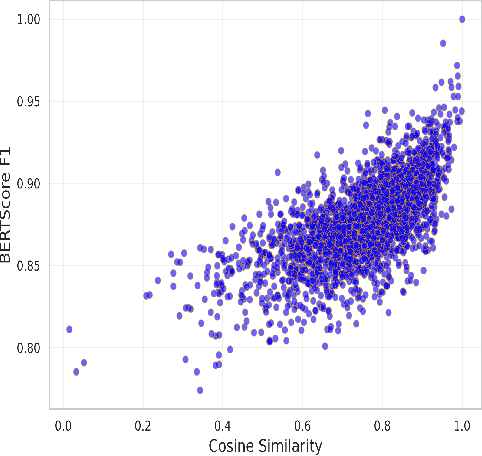
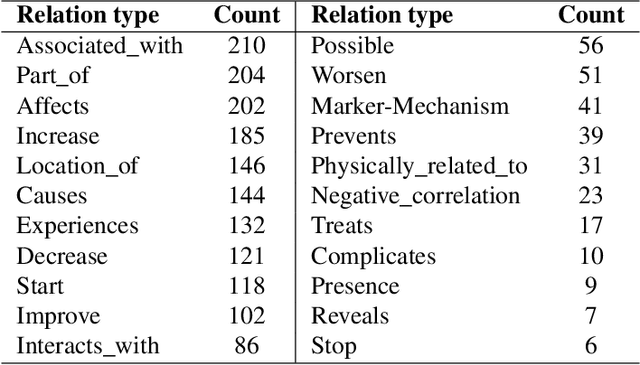
We explore a generative relation extraction (RE) pipeline tailored to the study of interactions in the intestinal microbiome, a complex and low-resource biomedical domain. Our method leverages summarization with large language models (LLMs) to refine context before extracting relations via instruction-tuned generation. Preliminary results on a dedicated corpus show that summarization improves generative RE performance by reducing noise and guiding the model. However, BERT-based RE approaches still outperform generative models. This ongoing work demonstrates the potential of generative methods to support the study of specialized domains in low-resources setting.
DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical Domain
Feb 20, 2024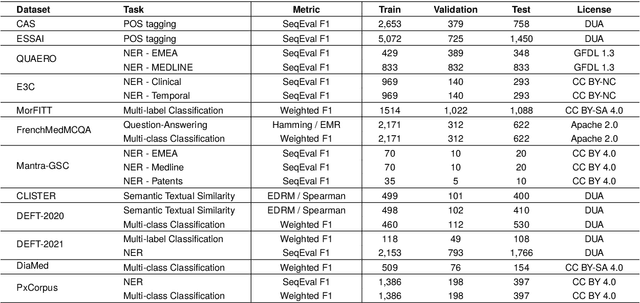
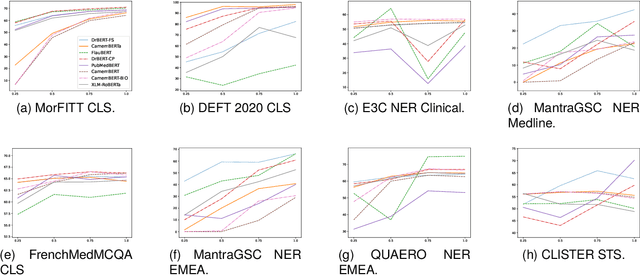
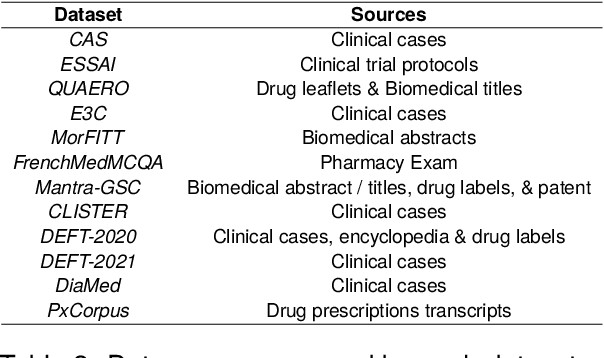
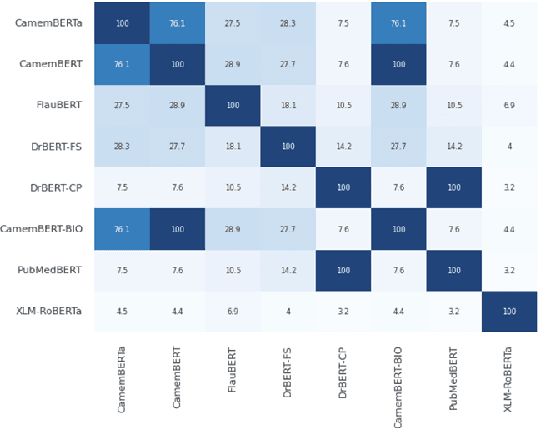
The biomedical domain has sparked a significant interest in the field of Natural Language Processing (NLP), which has seen substantial advancements with pre-trained language models (PLMs). However, comparing these models has proven challenging due to variations in evaluation protocols across different models. A fair solution is to aggregate diverse downstream tasks into a benchmark, allowing for the assessment of intrinsic PLMs qualities from various perspectives. Although still limited to few languages, this initiative has been undertaken in the biomedical field, notably English and Chinese. This limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. To bridge this research gap and account for the unique sensitivities of French, we present the first-ever publicly available French biomedical language understanding benchmark called DrBenchmark. It encompasses 20 diversified tasks, including named-entity recognition, part-of-speech tagging, question-answering, semantic textual similarity, and classification. We evaluate 8 state-of-the-art pre-trained masked language models (MLMs) on general and biomedical-specific data, as well as English specific MLMs to assess their cross-lingual capabilities. Our experiments reveal that no single model excels across all tasks, while generalist models are sometimes still competitive.
Building a Corpus for Biomedical Relation Extraction of Species Mentions
Jun 14, 2023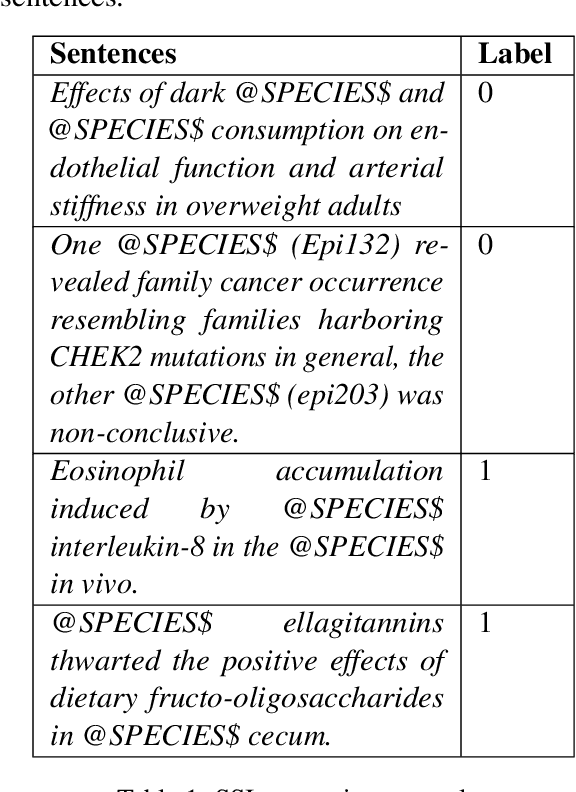
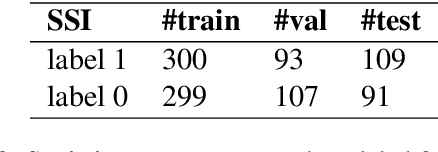
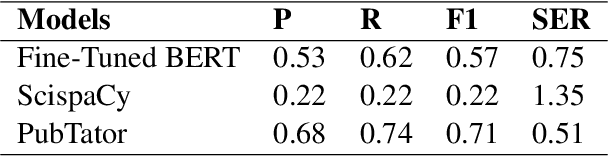
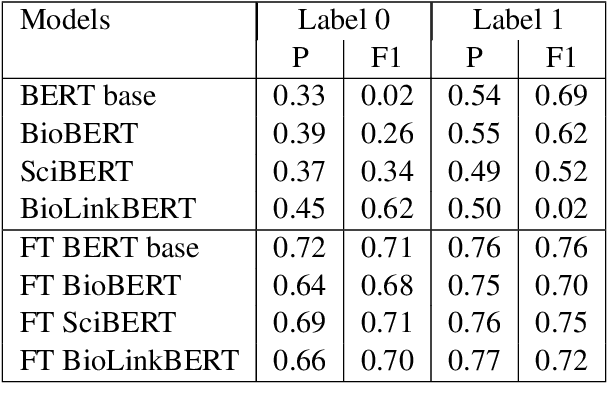
We present a manually annotated corpus, Species-Species Interaction, for extracting meaningful binary relations between species, in biomedical texts, at sentence level, with a focus on the gut microbiota. The corpus leverages PubTator to annotate species in full-text articles after evaluating different Named Entity Recognition species taggers. Our first results are promising for extracting relations between species using BERT and its biomedical variants.
Automatic segmentation of texts into units of meaning for reading assistance
Oct 11, 2019

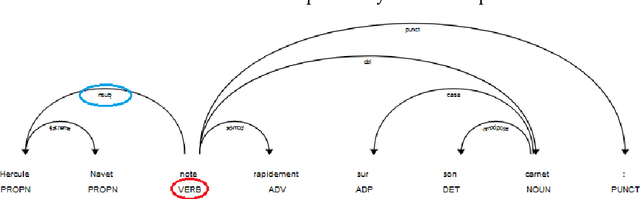
The emergence of the digital book is a major step forward in providing access to reading, and therefore often to the common culture and the labour market. By allowing the enrichment of texts with cognitive crutches, EPub 3 compatible accessibility formats such as FROG have proven their effectiveness in alleviating but also reducing dyslexic disorders. In this paper, we show how Artificial Intelligence and particularly Transfer Learning with Google BERT can automate the division into units of meaning, and thus facilitate the creation of enriched digital books at a moderate cost.