 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Clinical Text Enough? A Multimodal Study on Mortality Prediction in Heart Failure Patients
Apr 02, 2026Accurate short-term mortality prediction in heart failure (HF) remains challenging, particularly when relying on structured electronic health record (EHR) data alone. We evaluate transformer-based models on a French HF cohort, comparing text-only, structured-only, multimodal, and LLM-based approaches. Our results show that enriching clinical text with entity-level representations improves prediction over CLS embeddings alone, and that supervised multimodal fusion of text and structured variables achieves the best overall performance. In contrast, large language models perform inconsistently across modalities and decoding strategies, with text-only prompts outperforming structured or multimodal inputs. These findings highlight that entity-aware multimodal transformers offer the most reliable solution for short-term HF outcome prediction, while current LLM prompting remains limited for clinical decision support.
Investigating Gender Stereotypes in Large Language Models via Social Determinants of Health
Mar 10, 2026Large Language Models (LLMs) excel in Natural Language Processing (NLP) tasks, but they often propagate biases embedded in their training data, which is potentially impactful in sensitive domains like healthcare. While existing benchmarks evaluate biases related to individual social determinants of health (SDoH) such as gender or ethnicity, they often overlook interactions between these factors and lack context-specific assessments. This study investigates bias in LLMs by probing the relationships between gender and other SDoH in French patient records. Through a series of experiments, we found that embedded stereotypes can be probed using SDoH input and that LLMs rely on embedded stereotypes to make gendered decisions, suggesting that evaluating interactions among SDoH factors could usefully complement existing approaches to assessing LLM performance and bias.
Adaptation of Biomedical and Clinical Pretrained Models to French Long Documents: A Comparative Study
Feb 26, 2024



Recently, pretrained language models based on BERT have been introduced for the French biomedical domain. Although these models have achieved state-of-the-art results on biomedical and clinical NLP tasks, they are constrained by a limited input sequence length of 512 tokens, which poses challenges when applied to clinical notes. In this paper, we present a comparative study of three adaptation strategies for long-sequence models, leveraging the Longformer architecture. We conducted evaluations of these models on 16 downstream tasks spanning both biomedical and clinical domains. Our findings reveal that further pre-training an English clinical model with French biomedical texts can outperform both converting a French biomedical BERT to the Longformer architecture and pre-training a French biomedical Longformer from scratch. The results underscore that long-sequence French biomedical models improve performance across most downstream tasks regardless of sequence length, but BERT based models remain the most efficient for named entity recognition tasks.
DrBenchmark: A Large Language Understanding Evaluation Benchmark for French Biomedical Domain
Feb 20, 2024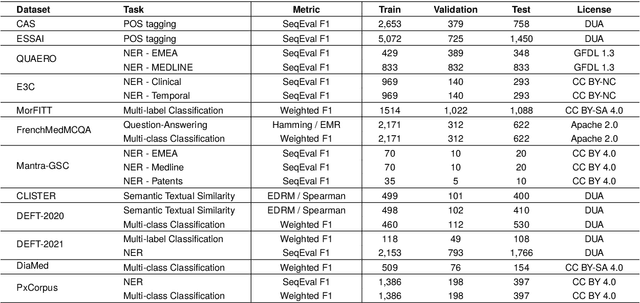
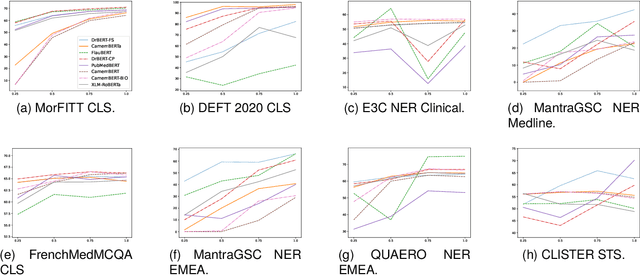
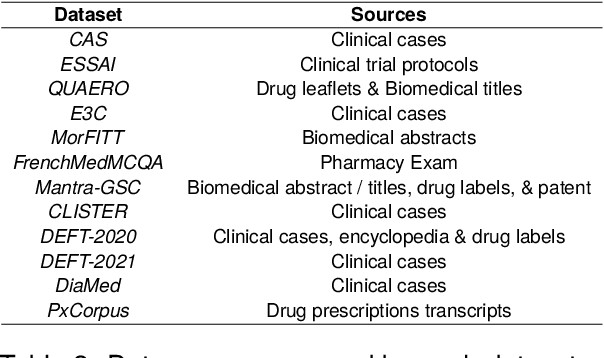
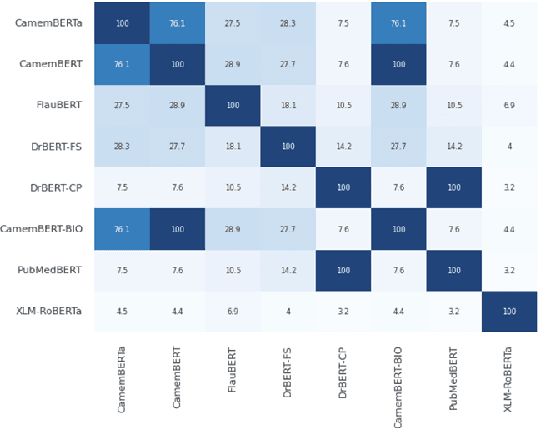
The biomedical domain has sparked a significant interest in the field of Natural Language Processing (NLP), which has seen substantial advancements with pre-trained language models (PLMs). However, comparing these models has proven challenging due to variations in evaluation protocols across different models. A fair solution is to aggregate diverse downstream tasks into a benchmark, allowing for the assessment of intrinsic PLMs qualities from various perspectives. Although still limited to few languages, this initiative has been undertaken in the biomedical field, notably English and Chinese. This limitation hampers the evaluation of the latest French biomedical models, as they are either assessed on a minimal number of tasks with non-standardized protocols or evaluated using general downstream tasks. To bridge this research gap and account for the unique sensitivities of French, we present the first-ever publicly available French biomedical language understanding benchmark called DrBenchmark. It encompasses 20 diversified tasks, including named-entity recognition, part-of-speech tagging, question-answering, semantic textual similarity, and classification. We evaluate 8 state-of-the-art pre-trained masked language models (MLMs) on general and biomedical-specific data, as well as English specific MLMs to assess their cross-lingual capabilities. Our experiments reveal that no single model excels across all tasks, while generalist models are sometimes still competitive.
BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Feb 15, 2024



Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges. In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
FrenchMedMCQA: A French Multiple-Choice Question Answering Dataset for Medical domain
Apr 09, 2023


This paper introduces FrenchMedMCQA, the first publicly available Multiple-Choice Question Answering (MCQA) dataset in French for medical domain. It is composed of 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers. Each instance of the dataset contains an identifier, a question, five possible answers and their manual correction(s). We also propose first baseline models to automatically process this MCQA task in order to report on the current performances and to highlight the difficulty of the task. A detailed analysis of the results showed that it is necessary to have representations adapted to the medical domain or to the MCQA task: in our case, English specialized models yielded better results than generic French ones, even though FrenchMedMCQA is in French. Corpus, models and tools are available online.
DrBERT: A Robust Pre-trained Model in French for Biomedical and Clinical domains
Apr 03, 2023In recent years, pre-trained language models (PLMs) achieve the best performance on a wide range of natural language processing (NLP) tasks. While the first models were trained on general domain data, specialized ones have emerged to more effectively treat specific domains. In this paper, we propose an original study of PLMs in the medical domain on French language. We compare, for the first time, the performance of PLMs trained on both public data from the web and private data from healthcare establishments. We also evaluate different learning strategies on a set of biomedical tasks. In particular, we show that we can take advantage of already existing biomedical PLMs in a foreign language by further pre-train it on our targeted data. Finally, we release the first specialized PLMs for the biomedical field in French, called DrBERT, as well as the largest corpus of medical data under free license on which these models are trained.
Recent Advances in End-to-End Spoken Language Understanding
Sep 29, 2019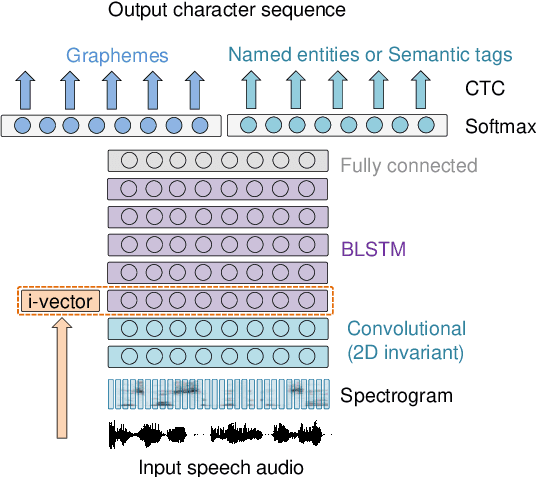
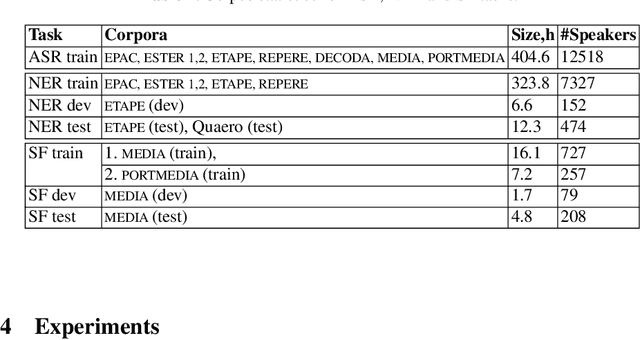
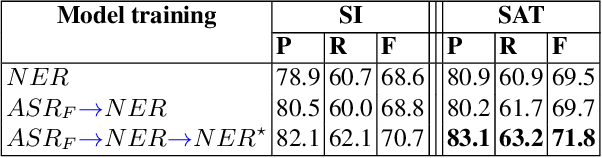
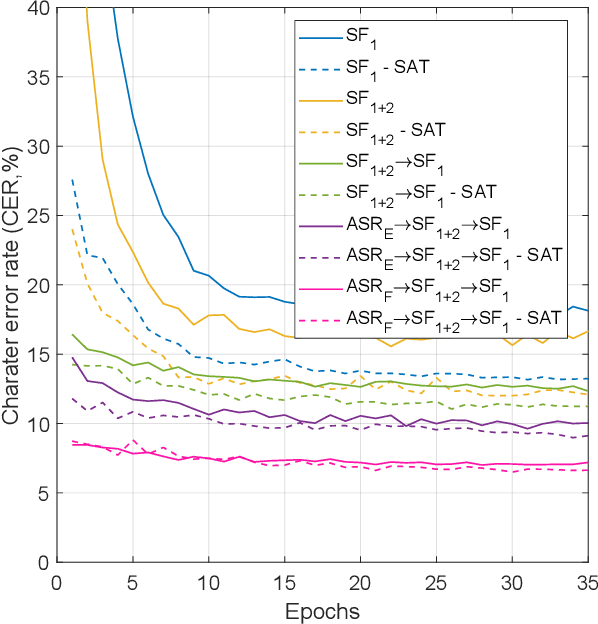
This work investigates spoken language understanding (SLU) systems in the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. Two SLU tasks are considered: named entity recognition (NER) and semantic slot filling (SF). For these tasks, in order to improve the model performance, we explore various techniques including speaker adaptation, a modification of the connectionist temporal classification (CTC) training criterion, and sequential pretraining.
Deep Retrieval-Based Dialogue Systems: A Short Review
Jul 30, 2019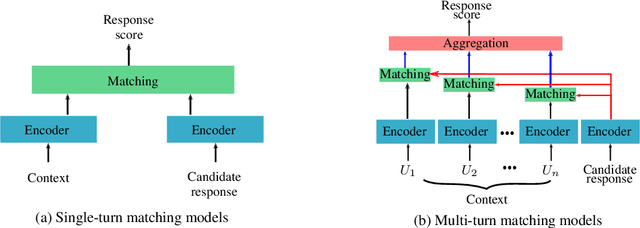
Building dialogue systems that naturally converse with humans is being an attractive and an active research domain. Multiple systems are being designed everyday and several datasets are being available. For this reason, it is being hard to keep an up-to-date state-of-the-art. In this work, we present the latest and most relevant retrieval-based dialogue systems and the available datasets used to build and evaluate them. We discuss their limitations and provide insights and guidelines for future work.
Curriculum-based transfer learning for an effective end-to-end spoken language understanding and domain portability
Jun 18, 2019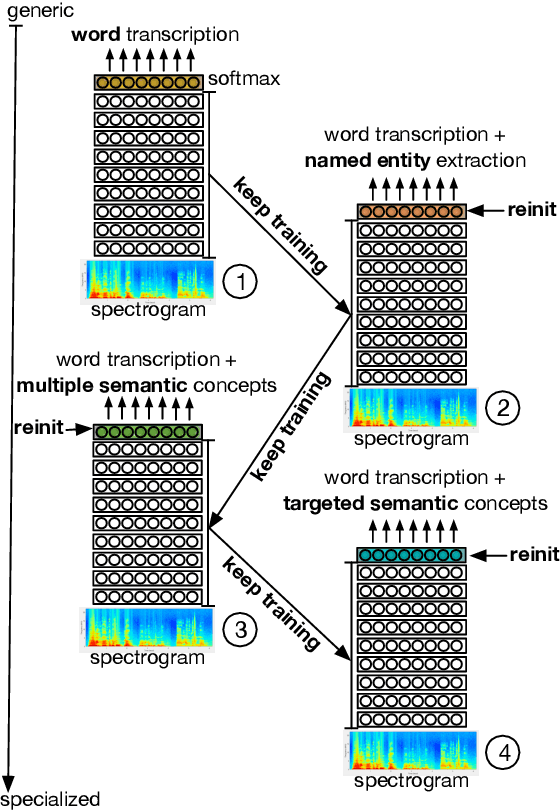

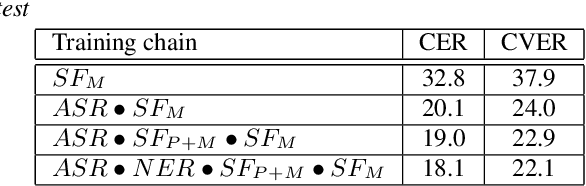

We present an end-to-end approach to extract semantic concepts directly from the speech audio signal. To overcome the lack of data available for this spoken language understanding approach, we investigate the use of a transfer learning strategy based on the principles of curriculum learning. This approach allows us to exploit out-of-domain data that can help to prepare a fully neural architecture. Experiments are carried out on the French MEDIA and PORTMEDIA corpora and show that this end-to-end SLU approach reaches the best results ever published on this task. We compare our approach to a classical pipeline approach that uses ASR, POS tagging, lemmatizer, chunker... and other NLP tools that aim to enrich ASR outputs that feed an SLU text to concepts system. Last, we explore the promising capacity of our end-to-end SLU approach to address the problem of domain portability.