 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024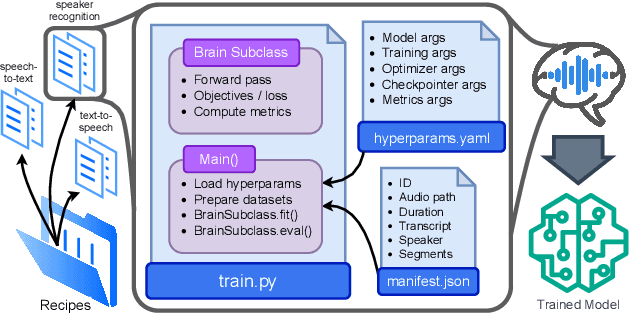

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021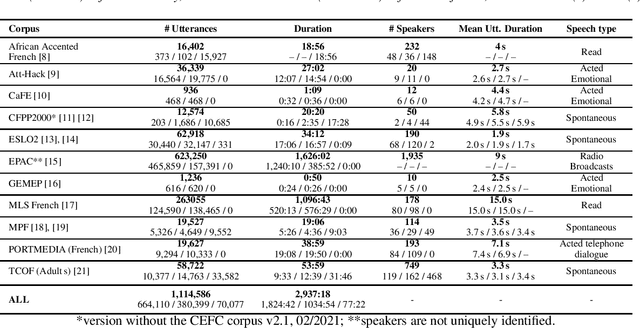
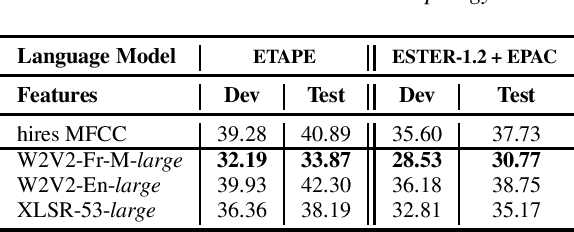
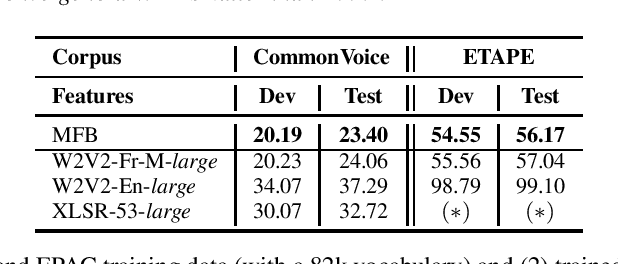
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
Exploring Gaussian mixture model framework for speaker adaptation of deep neural network acoustic models
Mar 15, 2020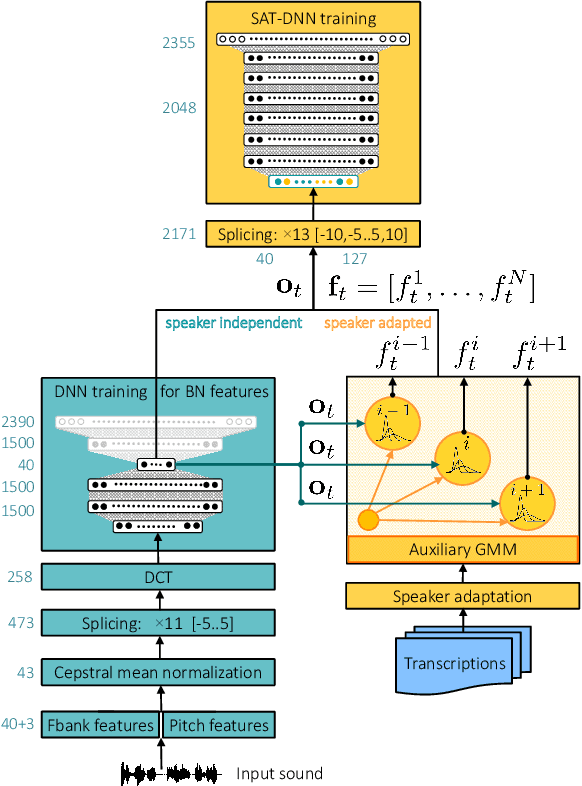
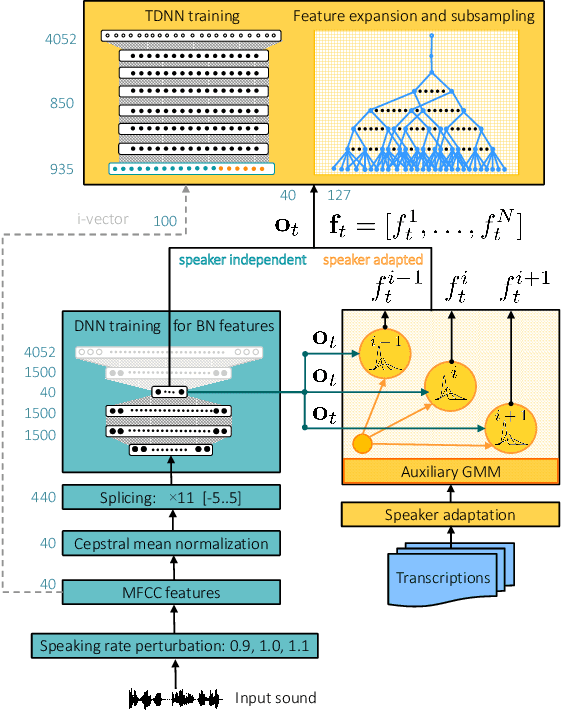
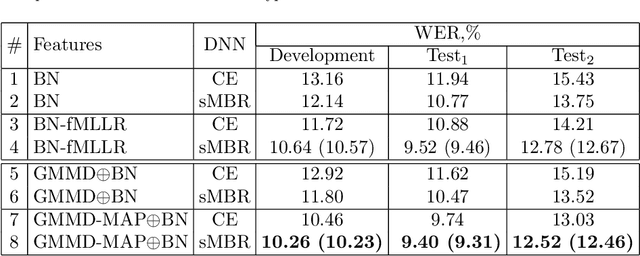
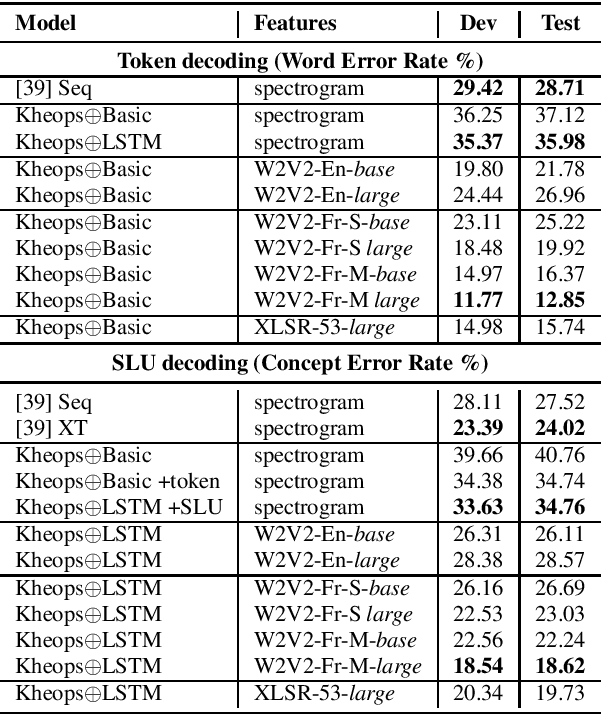
In this paper we investigate the GMM-derived (GMMD) features for adaptation of deep neural network (DNN) acoustic models. The adaptation of the DNN trained on GMMD features is done through the maximum a posteriori (MAP) adaptation of the auxiliary GMM model used for GMMD feature extraction. We explore fusion of the adapted GMMD features with conventional features, such as bottleneck and MFCC features, in two different neural network architectures: DNN and time-delay neural network (TDNN). We analyze and compare different types of adaptation techniques such as i-vectors and feature-space adaptation techniques based on maximum likelihood linear regression (fMLLR) with the proposed adaptation approach, and explore their complementarity using various types of fusion such as feature level, posterior level, lattice level and others in order to discover the best possible way of combination. Experimental results on the TED-LIUM corpus show that the proposed adaptation technique can be effectively integrated into DNN and TDNN setups at different levels and provide additional gain in recognition performance: up to 6% of relative word error rate reduction (WERR) over the strong feature-space adaptation techniques based on maximum likelihood linear regression (fMLLR) speaker adapted DNN baseline, and up to 18% of relative WERR in comparison with a speaker independent (SI) DNN baseline model, trained on conventional features. For TDNN models the proposed approach achieves up to 26% of relative WERR in comparison with a SI baseline, and up 13% in comparison with the model adapted by using i-vectors. The analysis of the adapted GMMD features from various points of view demonstrates their effectiveness at different levels.
Dialogue history integration into end-to-end signal-to-concept spoken language understanding systems
Feb 14, 2020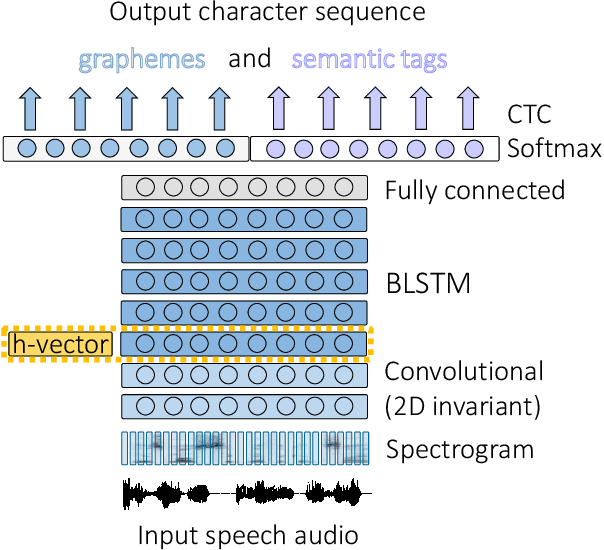
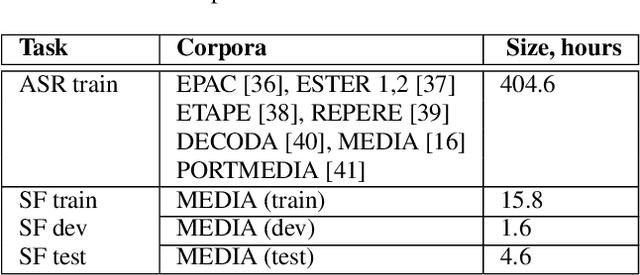


This work investigates the embeddings for representing dialog history in spoken language understanding (SLU) systems. We focus on the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. We proposed to integrate dialogue history into an end-to-end signal-to-concept SLU system. The dialog history is represented in the form of dialog history embedding vectors (so-called h-vectors) and is provided as an additional information to end-to-end SLU models in order to improve the system performance. Three following types of h-vectors are proposed and experimentally evaluated in this paper: (1) supervised-all embeddings predicting bag-of-concepts expected in the answer of the user from the last dialog system response; (2) supervised-freq embeddings focusing on predicting only a selected set of semantic concept (corresponding to the most frequent errors in our experiments); and (3) unsupervised embeddings. Experiments on the MEDIA corpus for the semantic slot filling task demonstrate that the proposed h-vectors improve the model performance.
ON-TRAC Consortium End-to-End Speech Translation Systems for the IWSLT 2019 Shared Task
Oct 30, 2019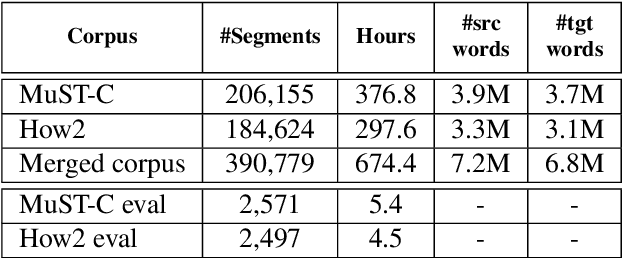
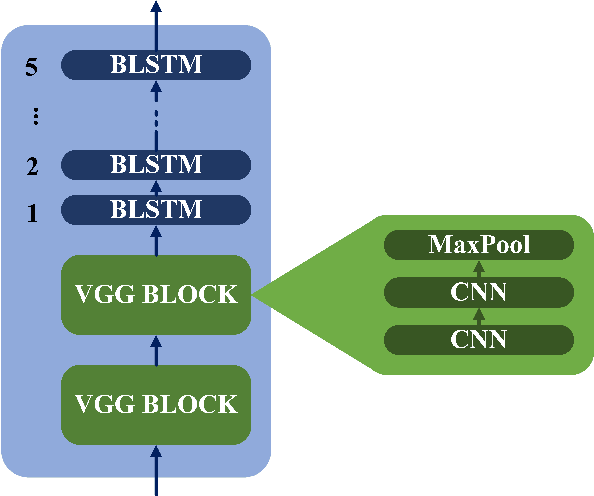
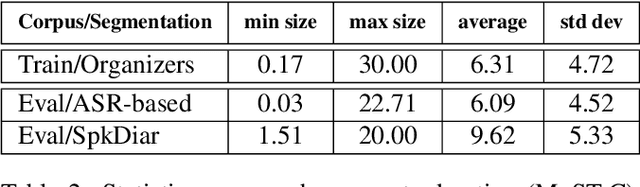
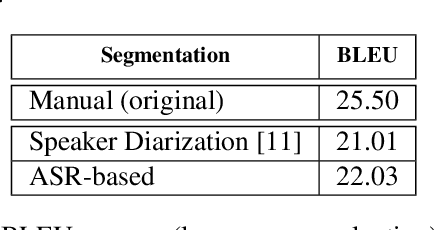
This paper describes the ON-TRAC Consortium translation systems developed for the end-to-end model task of IWSLT Evaluation 2019 for the English-to-Portuguese language pair. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). A single end-to-end model built as a neural encoder-decoder architecture with attention mechanism was used for two primary submissions corresponding to the two EN-PT evaluations sets: (1) TED (MuST-C) and (2) How2. In this paper, we notably investigate impact of pooling heterogeneous corpora for training, impact of target tokenization (characters or BPEs), impact of speech input segmentation and we also compare our best end-to-end model (BLEU of 26.91 on MuST-C and 43.82 on How2 validation sets) to a pipeline (ASR+MT) approach.
Recent Advances in End-to-End Spoken Language Understanding
Sep 29, 2019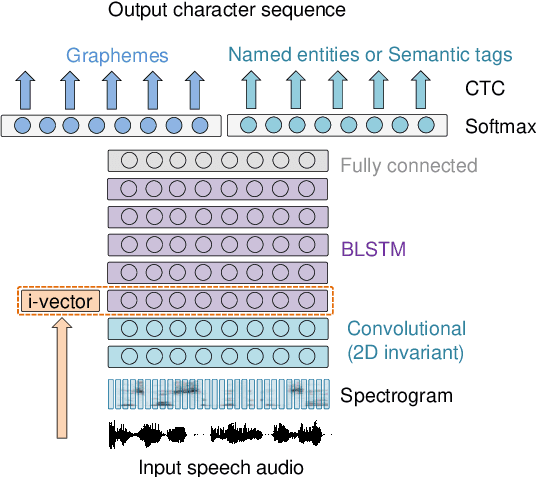
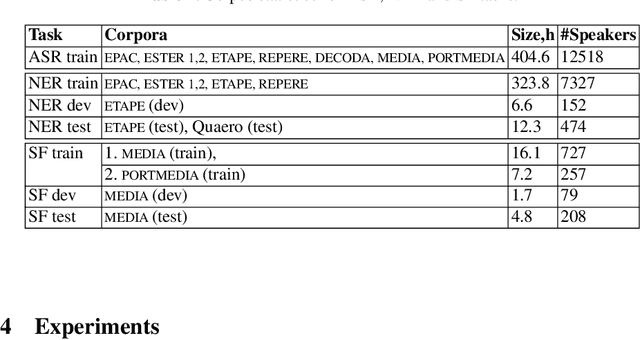
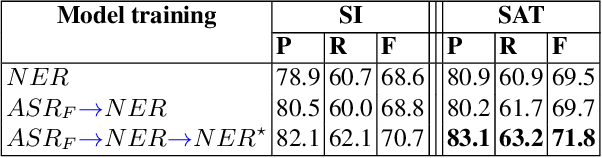
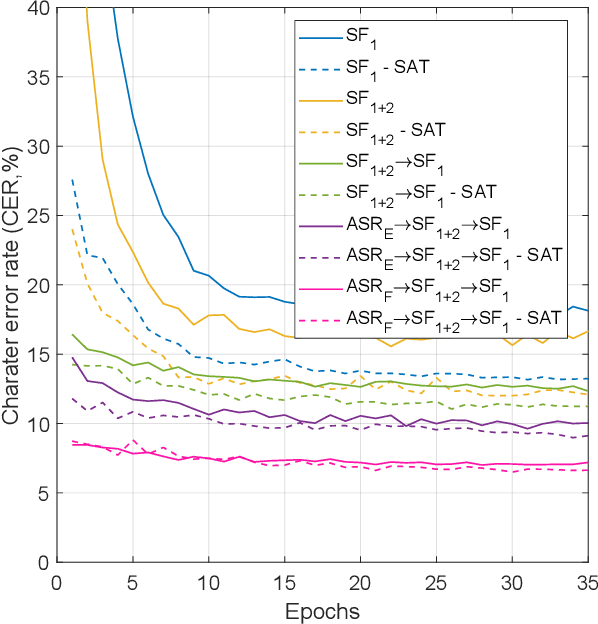
This work investigates spoken language understanding (SLU) systems in the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. Two SLU tasks are considered: named entity recognition (NER) and semantic slot filling (SF). For these tasks, in order to improve the model performance, we explore various techniques including speaker adaptation, a modification of the connectionist temporal classification (CTC) training criterion, and sequential pretraining.