 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Neural Population Geometry Reveals the Role of Stochasticity in Robust Perception
Nov 12, 2021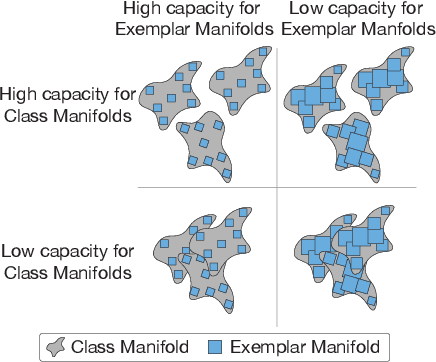
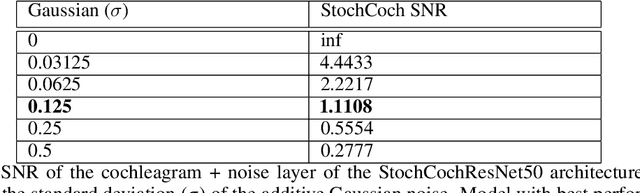
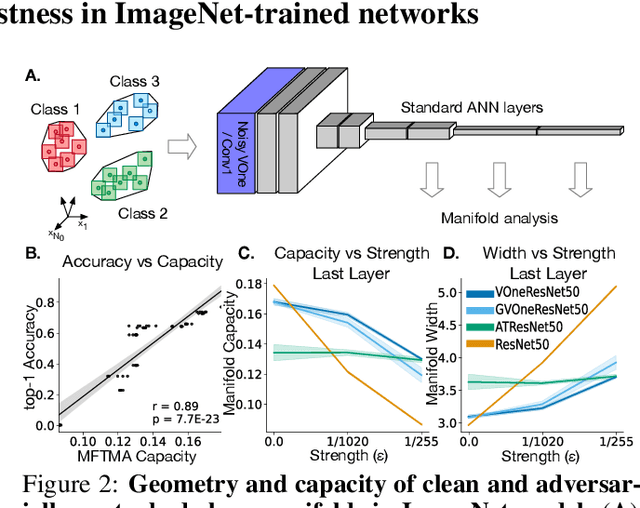

Adversarial examples are often cited by neuroscientists and machine learning researchers as an example of how computational models diverge from biological sensory systems. Recent work has proposed adding biologically-inspired components to visual neural networks as a way to improve their adversarial robustness. One surprisingly effective component for reducing adversarial vulnerability is response stochasticity, like that exhibited by biological neurons. Here, using recently developed geometrical techniques from computational neuroscience, we investigate how adversarial perturbations influence the internal representations of standard, adversarially trained, and biologically-inspired stochastic networks. We find distinct geometric signatures for each type of network, revealing different mechanisms for achieving robust representations. Next, we generalize these results to the auditory domain, showing that neural stochasticity also makes auditory models more robust to adversarial perturbations. Geometric analysis of the stochastic networks reveals overlap between representations of clean and adversarially perturbed stimuli, and quantitatively demonstrates that competing geometric effects of stochasticity mediate a tradeoff between adversarial and clean performance. Our results shed light on the strategies of robust perception utilized by adversarially trained and stochastic networks, and help explain how stochasticity may be beneficial to machine and biological computation.
Lightweight Adapter Tuning for Multilingual Speech Translation
Jun 02, 2021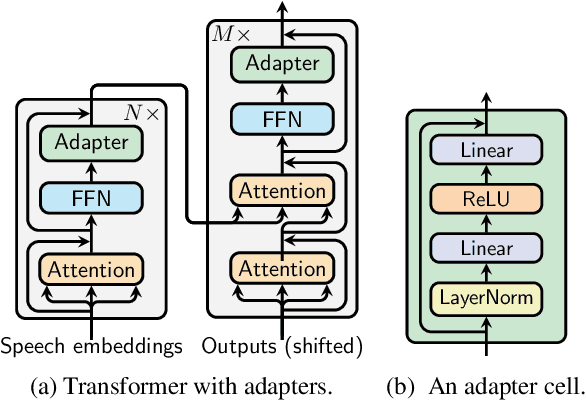

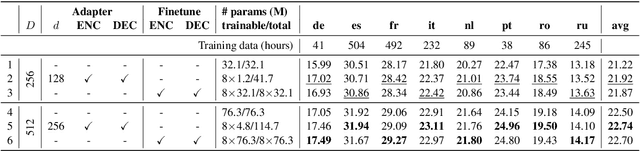
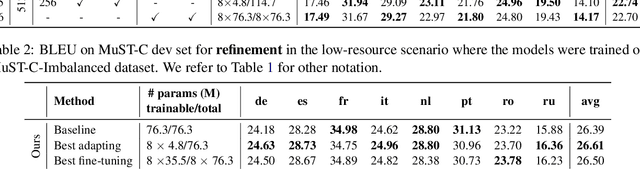
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pretrained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non-parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.
LeBenchmark: A Reproducible Framework for Assessing Self-Supervised Representation Learning from Speech
Apr 23, 2021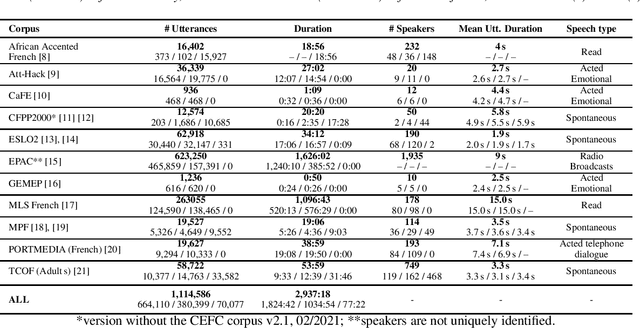
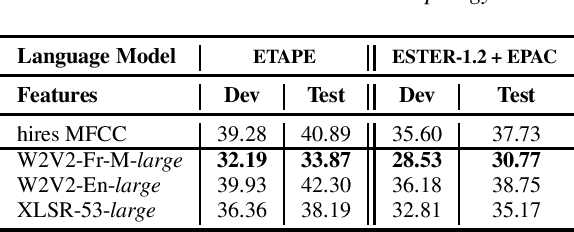
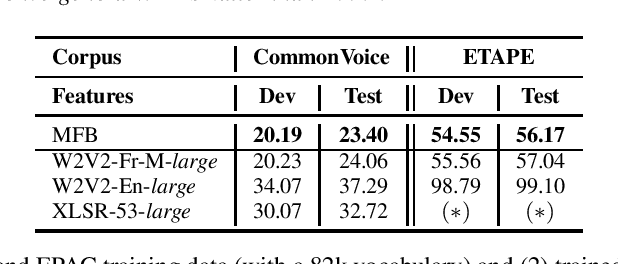
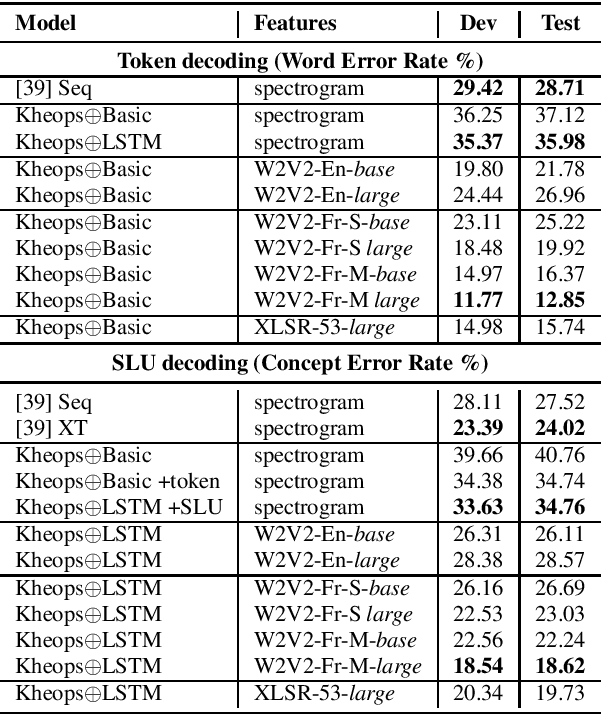
Self-Supervised Learning (SSL) using huge unlabeled data has been successfully explored for image and natural language processing. Recent works also investigated SSL from speech. They were notably successful to improve performance on downstream tasks such as automatic speech recognition (ASR). While these works suggest it is possible to reduce dependence on labeled data for building efficient speech systems, their evaluation was mostly made on ASR and using multiple and heterogeneous experimental settings (most of them for English). This renders difficult the objective comparison between SSL approaches and the evaluation of their impact on building speech systems. In this paper, we propose LeBenchmark: a reproducible framework for assessing SSL from speech. It not only includes ASR (high and low resource) tasks but also spoken language understanding, speech translation and emotion recognition. We also target speech technologies in a language different than English: French. SSL models of different sizes are trained from carefully sourced and documented datasets. Experiments show that SSL is beneficial for most but not all tasks which confirms the need for exhaustive and reliable benchmarks to evaluate its real impact. LeBenchmark is shared with the scientific community for reproducible research in SSL from speech.
Dual-decoder Transformer for Joint Automatic Speech Recognition and Multilingual Speech Translation
Nov 02, 2020
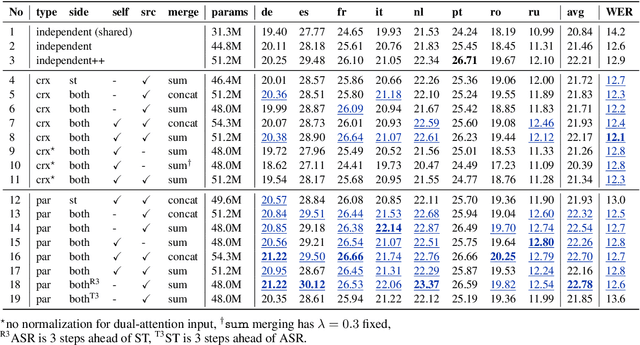
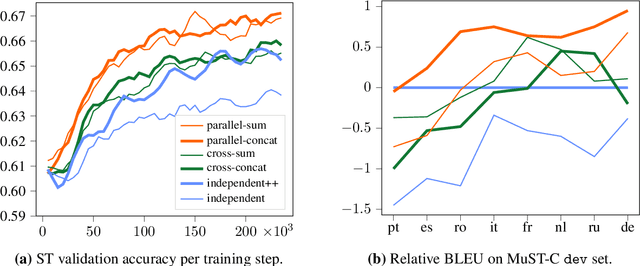
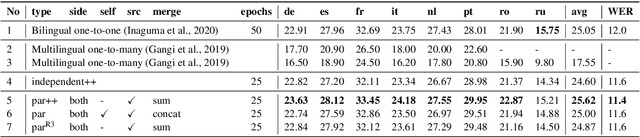
We introduce dual-decoder Transformer, a new model architecture that jointly performs automatic speech recognition (ASR) and multilingual speech translation (ST). Our models are based on the original Transformer architecture (Vaswani et al., 2017) but consist of two decoders, each responsible for one task (ASR or ST). Our major contribution lies in how these decoders interact with each other: one decoder can attend to different information sources from the other via a dual-attention mechanism. We propose two variants of these architectures corresponding to two different levels of dependencies between the decoders, called the parallel and cross dual-decoder Transformers, respectively. Extensive experiments on the MuST-C dataset show that our models outperform the previously-reported highest translation performance in the multilingual settings, and outperform as well bilingual one-to-one results. Furthermore, our parallel models demonstrate no trade-off between ASR and ST compared to the vanilla multi-task architecture. Our code and pre-trained models are available at https://github.com/formiel/speech-translation.
* Accepted at COLING 2020 (Oral)
Emergence of Separable Manifolds in Deep Language Representations
Jun 06, 2020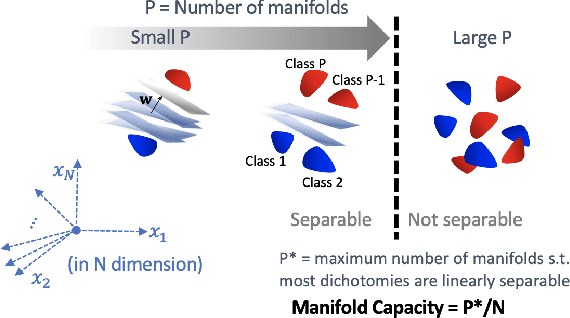
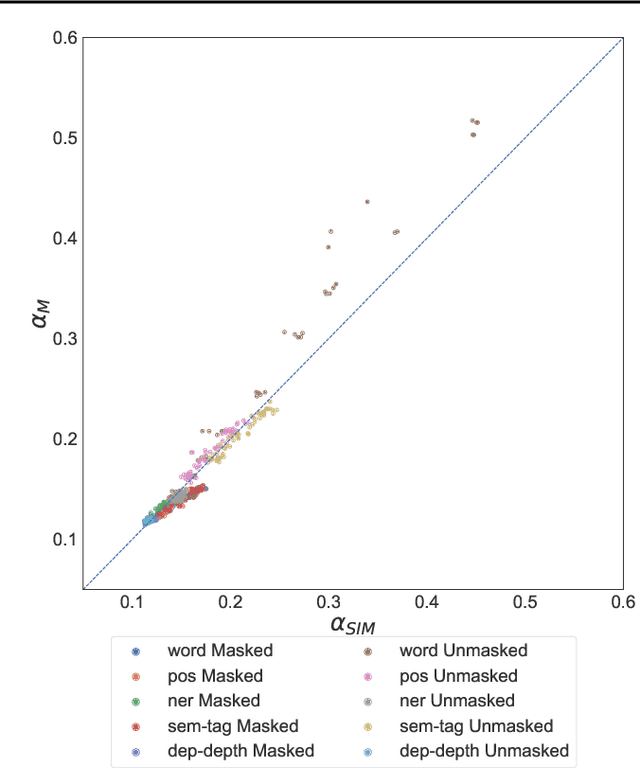
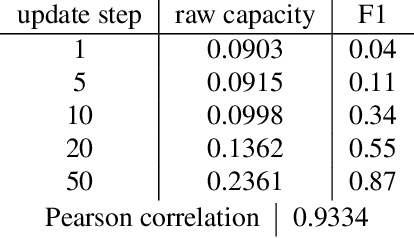
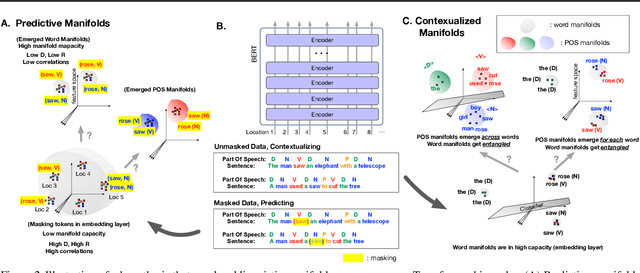
Artificial neural networks (ANNs) have shown much empirical success in solving perceptual tasks across various cognitive modalities. While they are only loosely inspired by the biological brain, recent studies report considerable similarities between representation extracted from task-optimized ANNs and neural populations in the brain. ANNs have subsequently become a popular model class to infer computational principles underlying complex cognitive functions, and in turn they have also emerged as a natural testbed for applying methods originally developed to probe information in neural populations. In this work, we utilize mean-field theoretic manifold analysis, a recent technique from computational neuroscience, to analyze the high dimensional geometry of language representations from large-scale contextual embedding models. We explore representations from different model families (BERT, RoBERTa, GPT-2, etc. ) and find evidence for emergence of linguistic manifold across layer depth (e.g., manifolds for part-of-speech and combinatory categorical grammar tags). We further observe that different encoding schemes used to obtain the representations lead to differences in whether these linguistic manifolds emerge in earlier or later layers of the network. In addition, we find that the emergence of linear separability in these manifolds is driven by a combined reduction of manifolds radius, dimensionality and inter-manifold correlations.
FlauBERT: Unsupervised Language Model Pre-training for French
Jan 09, 2020
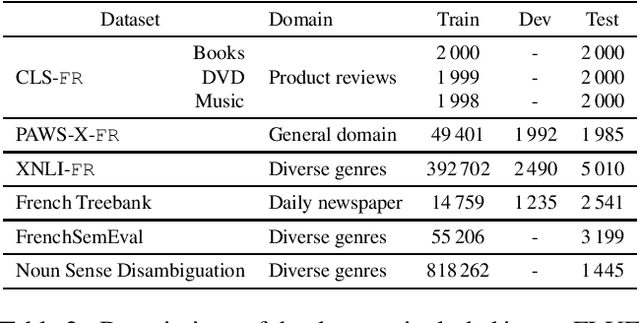
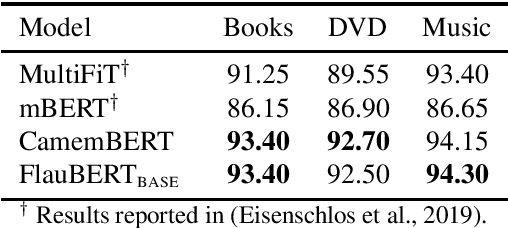

Language models have become a key step to achieve state-of-the art results in many different Natural Language Processing (NLP) tasks. Leveraging the huge amount of unlabeled texts nowadays available, they provide an efficient way to pre-train continuous word representations that can be fine-tuned for a downstream task, along with their contextualization at the sentence level. This has been widely demonstrated for English using contextualized representations (Dai and Le, 2015; Peters et al., 2018; Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019; Yang et al., 2019b). In this paper, we introduce and share FlauBERT, a model learned on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) Jean Zay supercomputer. We apply our French language models to diverse NLP tasks (text classification, paraphrasing, natural language inference, parsing, word sense disambiguation) and show that most of the time they outperform other pre-training approaches. Different versions of FlauBERT as well as a unified evaluation protocol for the downstream tasks, called FLUE (French Language Understanding Evaluation), are shared to the research community for further reproducible experiments in French NLP.
The LIG system for the English-Czech Text Translation Task of IWSLT 2019
Nov 07, 2019
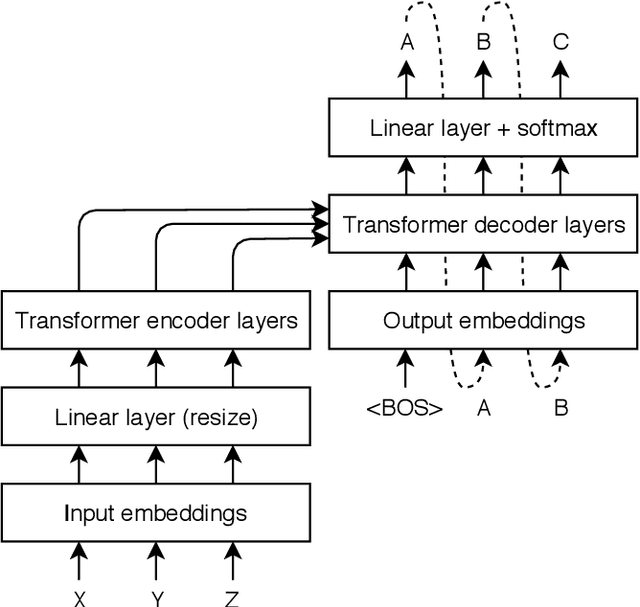
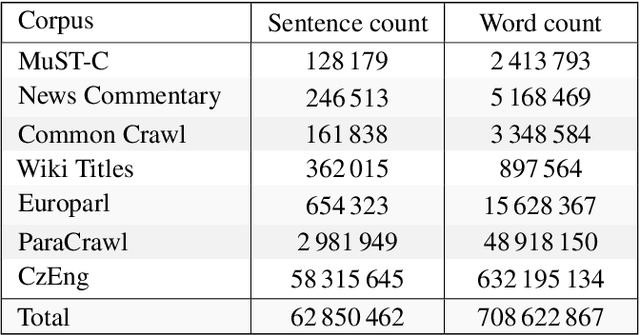

In this paper, we present our submission for the English to Czech Text Translation Task of IWSLT 2019. Our system aims to study how pre-trained language models, used as input embeddings, can improve a specialized machine translation system trained on few data. Therefore, we implemented a Transformer-based encoder-decoder neural system which is able to use the output of a pre-trained language model as input embeddings, and we compared its performance under three configurations: 1) without any pre-trained language model (constrained), 2) using a language model trained on the monolingual parts of the allowed English-Czech data (constrained), and 3) using a language model trained on a large quantity of external monolingual data (unconstrained). We used BERT as external pre-trained language model (configuration 3), and BERT architecture for training our own language model (configuration 2). Regarding the training data, we trained our MT system on a small quantity of parallel text: one set only consists of the provided MuST-C corpus, and the other set consists of the MuST-C corpus and the News Commentary corpus from WMT. We observed that using the external pre-trained BERT improves the scores of our system by +0.8 to +1.5 of BLEU on our development set, and +0.97 to +1.94 of BLEU on the test set. However, using our own language model trained only on the allowed parallel data seems to improve the machine translation performances only when the system is trained on the smallest dataset.