 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarnings-22: A Practical Benchmark for Accents in the Wild
Mar 29, 2022
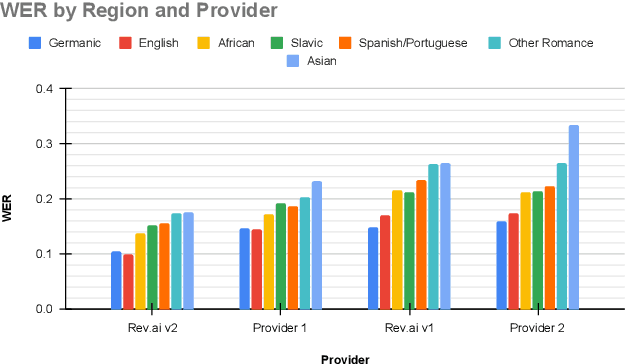
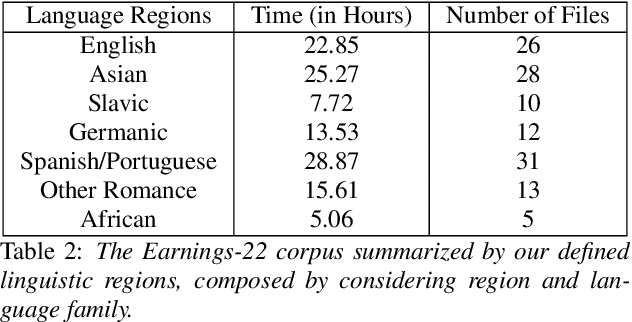

Modern automatic speech recognition (ASR) systems have achieved superhuman Word Error Rate (WER) on many common corpora despite lacking adequate performance on speech in the wild. Beyond that, there is a lack of real-world, accented corpora to properly benchmark academic and commercial models. To ensure this type of speech is represented in ASR benchmarking, we present Earnings-22, a 125 file, 119 hour corpus of English-language earnings calls gathered from global companies. We run a comparison across 4 commercial models showing the variation in performance when taking country of origin into consideration. Looking at hypothesis transcriptions, we explore errors common to all ASR systems tested. By examining Individual Word Error Rate (IWER), we find that key speech features impact model performance more for certain accents than others. Earnings-22 provides a free-to-use benchmark of real-world, accented audio to bridge academic and industrial research.
Earnings-21: A Practical Benchmark for ASR in the Wild
Apr 28, 2021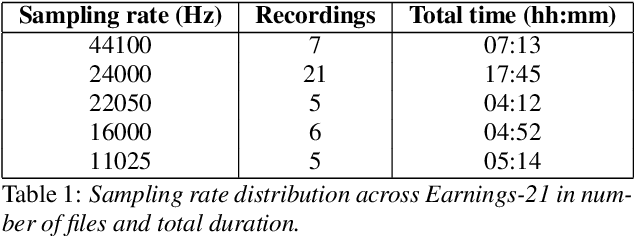
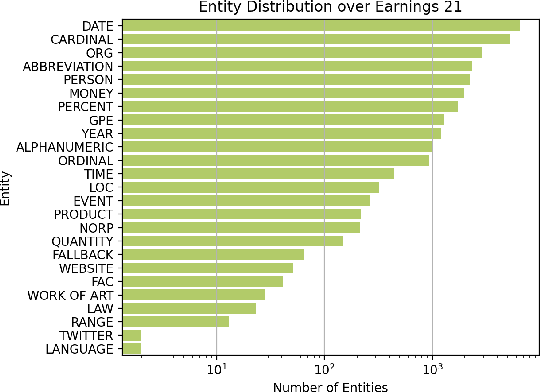
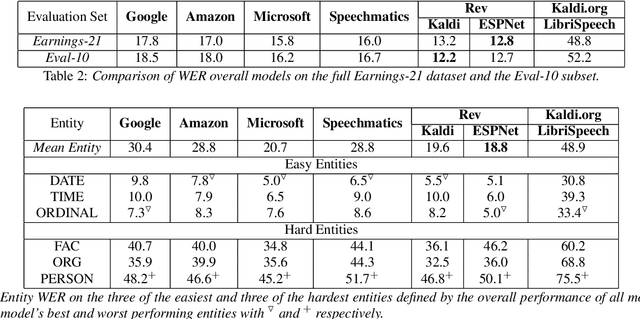
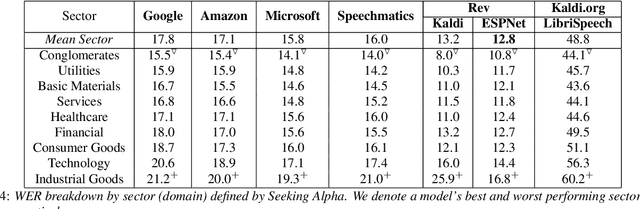
Commonly used speech corpora inadequately challenge academic and commercial ASR systems. In particular, speech corpora lack metadata needed for detailed analysis and WER measurement. In response, we present Earnings-21, a 39-hour corpus of earnings calls containing entity-dense speech from nine different financial sectors. This corpus is intended to benchmark ASR systems in the wild with special attention towards named entity recognition. We benchmark four commercial ASR models, two internal models built with open-source tools, and an open-source LibriSpeech model and discuss their differences in performance on Earnings-21. Using our recently released fstalign tool, we provide a candid analysis of each model's recognition capabilities under different partitions. Our analysis finds that ASR accuracy for certain NER categories is poor, presenting a significant impediment to transcript comprehension and usage. Earnings-21 bridges academic and commercial ASR system evaluation and enables further research on entity modeling and WER on real world audio.
Accented Speech Recognition: A Survey
Apr 21, 2021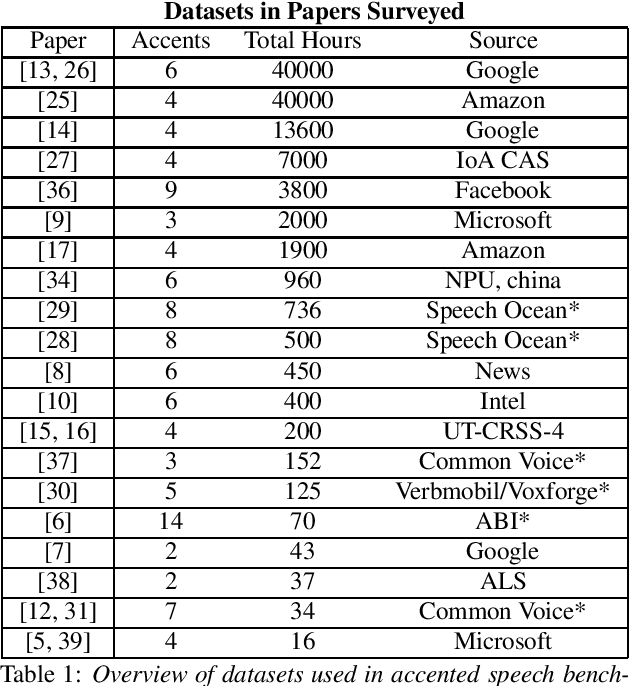
Automatic Speech Recognition (ASR) systems generalize poorly on accented speech. The phonetic and linguistic variability of accents present hard challenges for ASR systems today in both data collection and modeling strategies. The resulting bias in ASR performance across accents comes at a cost to both users and providers of ASR. We present a survey of current promising approaches to accented speech recognition and highlight the key challenges in the space. Approaches mostly focus on single model generalization and accent feature engineering. Among the challenges, lack of a standard benchmark makes research and comparison especially difficult.
Emergence of Separable Manifolds in Deep Language Representations
Jun 06, 2020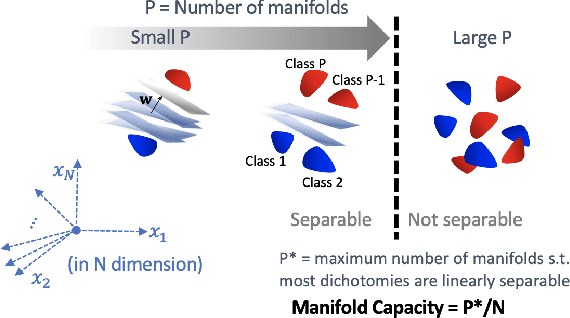
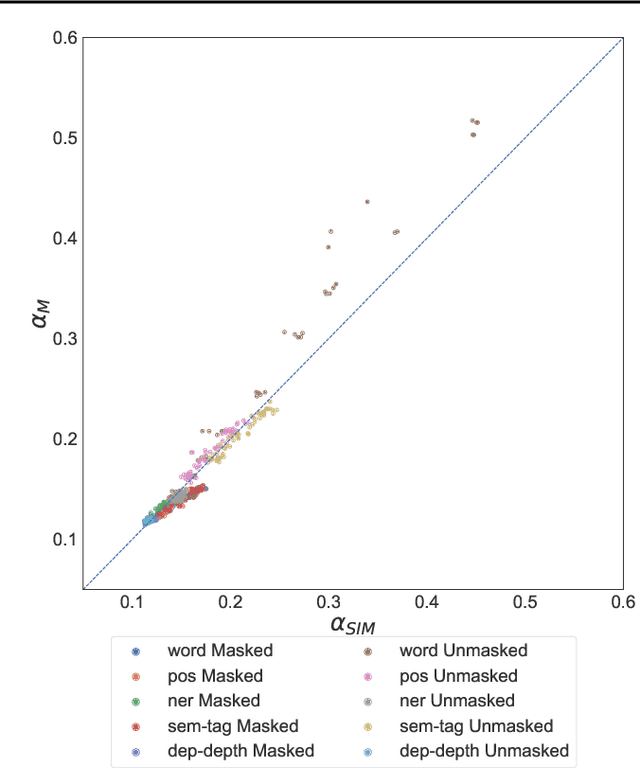
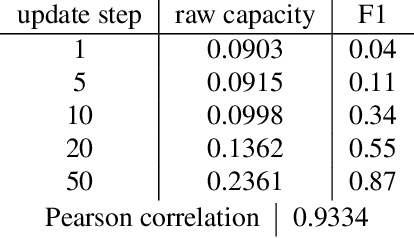
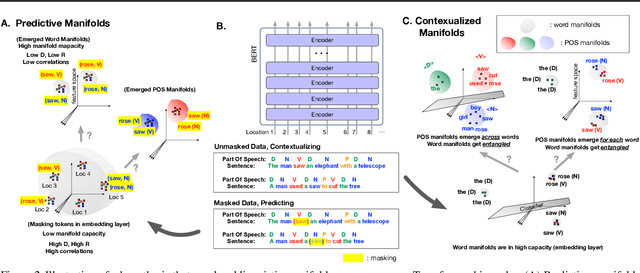
Artificial neural networks (ANNs) have shown much empirical success in solving perceptual tasks across various cognitive modalities. While they are only loosely inspired by the biological brain, recent studies report considerable similarities between representation extracted from task-optimized ANNs and neural populations in the brain. ANNs have subsequently become a popular model class to infer computational principles underlying complex cognitive functions, and in turn they have also emerged as a natural testbed for applying methods originally developed to probe information in neural populations. In this work, we utilize mean-field theoretic manifold analysis, a recent technique from computational neuroscience, to analyze the high dimensional geometry of language representations from large-scale contextual embedding models. We explore representations from different model families (BERT, RoBERTa, GPT-2, etc. ) and find evidence for emergence of linguistic manifold across layer depth (e.g., manifolds for part-of-speech and combinatory categorical grammar tags). We further observe that different encoding schemes used to obtain the representations lead to differences in whether these linguistic manifolds emerge in earlier or later layers of the network. In addition, we find that the emergence of linear separability in these manifolds is driven by a combined reduction of manifolds radius, dimensionality and inter-manifold correlations.