 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-agnostic evaluation of ASR using multiple reference transcripts
Dec 10, 2024



Word error rate (WER) as a metric has a variety of limitations that have plagued the field of speech recognition. Evaluation datasets suffer from varying style, formality, and inherent ambiguity of the transcription task. In this work, we attempt to mitigate some of these differences by performing style-agnostic evaluation of ASR systems using multiple references transcribed under opposing style parameters. As a result, we find that existing WER reports are likely significantly over-estimating the number of contentful errors made by state-of-the-art ASR systems. In addition, we have found our multireference method to be a useful mechanism for comparing the quality of ASR models that differ in the stylistic makeup of their training data and target task.
Reverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
Quantification of stylistic differences in human- and ASR-produced transcripts of African American English
Sep 04, 2024



Common measures of accuracy used to assess the performance of automatic speech recognition (ASR) systems, as well as human transcribers, conflate multiple sources of error. Stylistic differences, such as verbatim vs non-verbatim, can play a significant role in ASR performance evaluation when differences exist between training and test datasets. The problem is compounded for speech from underrepresented varieties, where the speech to orthography mapping is not as standardized. We categorize the kinds of stylistic differences between 6 transcription versions, 4 human- and 2 ASR-produced, of 10 hours of African American English (AAE) speech. Focusing on verbatim features and AAE morphosyntactic features, we investigate the interactions of these categories with how well transcripts can be compared via word error rate (WER). The results, and overall analysis, help clarify how ASR outputs are a function of the decisions made by the training data's human transcribers.
Earnings-21: A Practical Benchmark for ASR in the Wild
Apr 28, 2021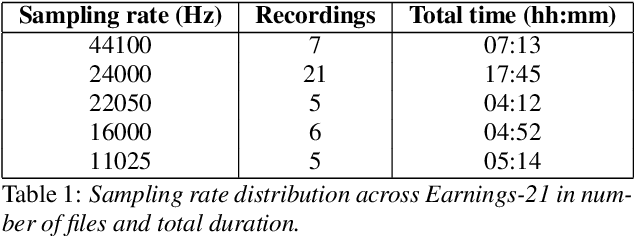
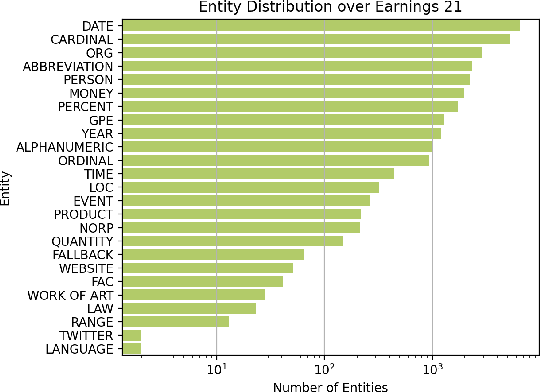
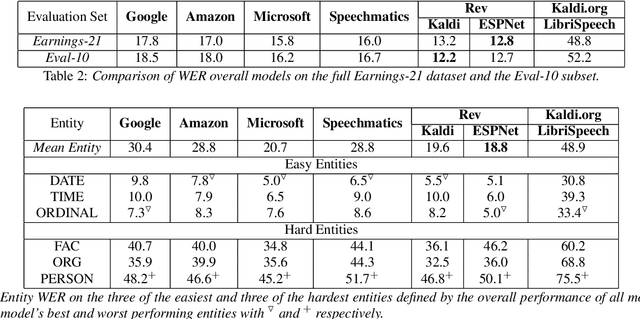
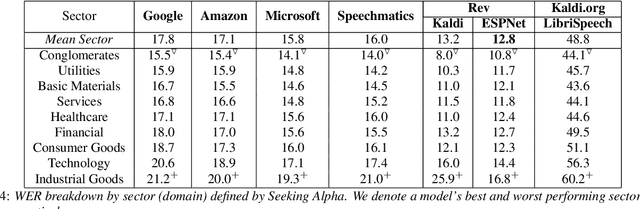
Commonly used speech corpora inadequately challenge academic and commercial ASR systems. In particular, speech corpora lack metadata needed for detailed analysis and WER measurement. In response, we present Earnings-21, a 39-hour corpus of earnings calls containing entity-dense speech from nine different financial sectors. This corpus is intended to benchmark ASR systems in the wild with special attention towards named entity recognition. We benchmark four commercial ASR models, two internal models built with open-source tools, and an open-source LibriSpeech model and discuss their differences in performance on Earnings-21. Using our recently released fstalign tool, we provide a candid analysis of each model's recognition capabilities under different partitions. Our analysis finds that ASR accuracy for certain NER categories is poor, presenting a significant impediment to transcript comprehension and usage. Earnings-21 bridges academic and commercial ASR system evaluation and enables further research on entity modeling and WER on real world audio.
Accented Speech Recognition: A Survey
Apr 21, 2021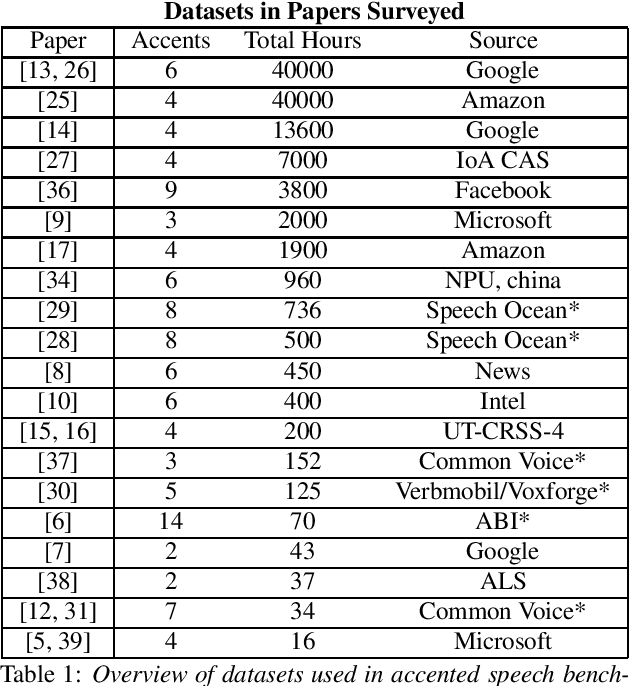
Automatic Speech Recognition (ASR) systems generalize poorly on accented speech. The phonetic and linguistic variability of accents present hard challenges for ASR systems today in both data collection and modeling strategies. The resulting bias in ASR performance across accents comes at a cost to both users and providers of ASR. We present a survey of current promising approaches to accented speech recognition and highlight the key challenges in the space. Approaches mostly focus on single model generalization and accent feature engineering. Among the challenges, lack of a standard benchmark makes research and comparison especially difficult.
On the Capability of Neural Networks to Generalize to Unseen Category-Pose Combinations
Jul 15, 2020
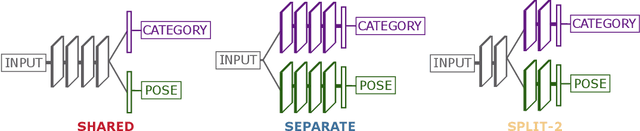
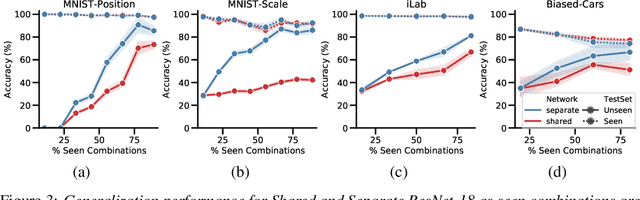
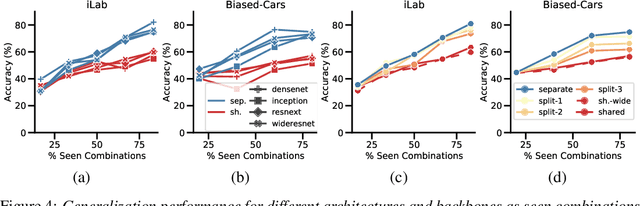
Recognizing an object's category and pose lies at the heart of visual understanding. Recent works suggest that deep neural networks (DNNs) often fail to generalize to category-pose combinations not seen during training. However, it is unclear when and how such generalization may be possible. Does the number of combinations seen during training impact generalization? Is it better to learn category and pose in separate networks, or in a single shared network? Furthermore, what are the neural mechanisms that drive the network's generalization? In this paper, we answer these questions by analyzing state-of-the-art DNNs trained to recognize both object category and pose (position, scale, and 3D viewpoint) with quantitative control over the number of category-pose combinations seen during training. We also investigate the emergence of two types of specialized neurons that can explain generalization to unseen combinations---neurons selective to category and invariant to pose, and vice versa. We perform experiments on MNIST extended with position or scale, the iLab dataset with vehicles at different viewpoints, and a challenging new dataset for car model recognition and viewpoint estimation that we introduce in this paper, the Biased-Cars dataset. Our results demonstrate that as the number of combinations seen during training increases, networks generalize better to unseen category-pose combinations, facilitated by an increase in the selectivity and invariance of individual neurons. We find that learning category and pose in separate networks compared to a shared one leads to an increase in such selectivity and invariance, as separate networks are not forced to preserve information about both category and pose. This enables separate networks to significantly outperform shared ones at predicting unseen category-pose combinations.