 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
Bayesian HMM clustering of x-vector sequences in speaker diarization: theory, implementation and analysis on standard tasks
Dec 29, 2020
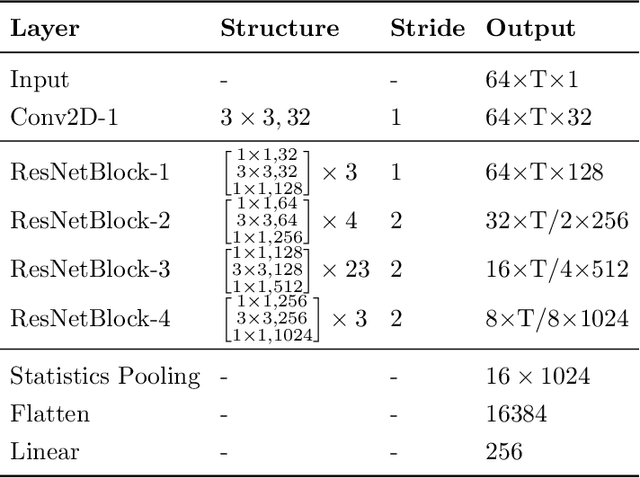

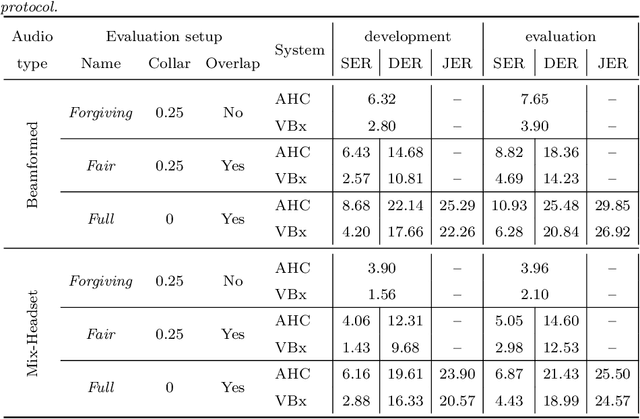
The recently proposed VBx diarization method uses a Bayesian hidden Markov model to find speaker clusters in a sequence of x-vectors. In this work we perform an extensive comparison of performance of the VBx diarization with other approaches in the literature and we show that VBx achieves superior performance on three of the most popular datasets for evaluating diarization: CALLHOME, AMI and DIHARDII datasets. Further, we present for the first time the derivation and update formulae for the VBx model, focusing on the efficiency and simplicity of this model as compared to the previous and more complex BHMM model working on frame-by-frame standard Cepstral features. Together with this publication, we release the recipe for training the x-vector extractors used in our experiments on both wide and narrowband data, and the VBx recipes that attain state-of-the-art performance on all three datasets. Besides, we point out the lack of a standardized evaluation protocol for AMI dataset and we propose a new protocol for both Beamformed and Mix-Headset audios based on the official AMI partitions and transcriptions.
BUT VOiCES 2019 System Description
Jul 13, 2019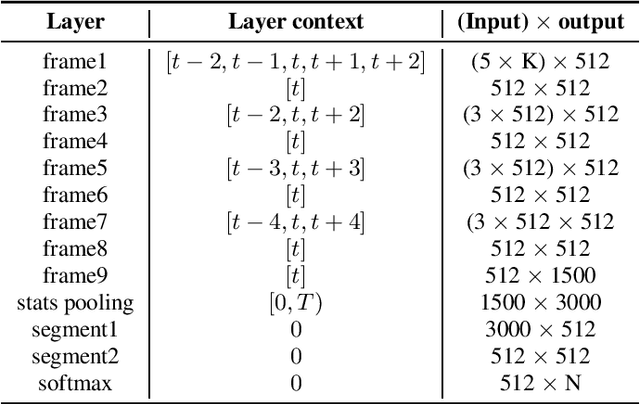
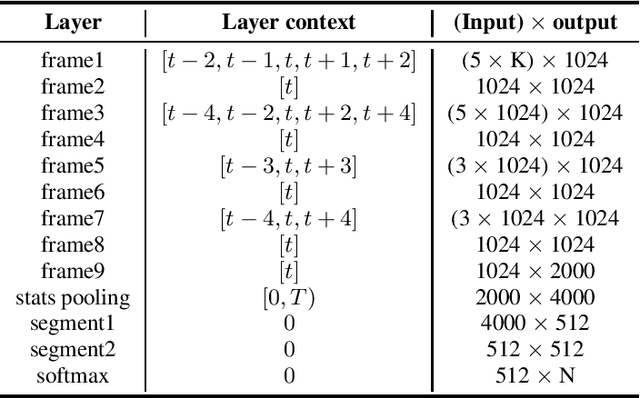
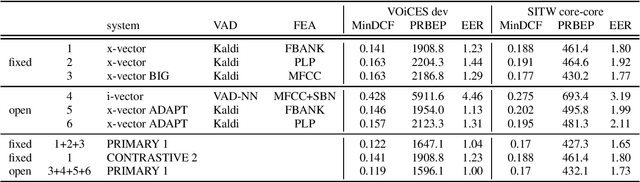
This is a description of our effort in VOiCES 2019 Speaker Recognition challenge. All systems in the fixed condition are based on the x-vector paradigm with different features and DNN topologies. The single best system reaches 1.2% EER and a fusion of 3 systems yields 1.0% EER, which is 15% relative improvement. The open condition allowed us to use external data which we did for the PLDA adaptation and achieved less than ~10% relative improvement. In the submission to open condition, we used 3 x-vector systems and also one i-vector based system.