 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-agnostic evaluation of ASR using multiple reference transcripts
Dec 10, 2024



Word error rate (WER) as a metric has a variety of limitations that have plagued the field of speech recognition. Evaluation datasets suffer from varying style, formality, and inherent ambiguity of the transcription task. In this work, we attempt to mitigate some of these differences by performing style-agnostic evaluation of ASR systems using multiple references transcribed under opposing style parameters. As a result, we find that existing WER reports are likely significantly over-estimating the number of contentful errors made by state-of-the-art ASR systems. In addition, we have found our multireference method to be a useful mechanism for comparing the quality of ASR models that differ in the stylistic makeup of their training data and target task.
Reverb: Open-Source ASR and Diarization from Rev
Oct 04, 2024

Today, we are open-sourcing our core speech recognition and diarization models for non-commercial use. We are releasing both a full production pipeline for developers as well as pared-down research models for experimentation. Rev hopes that these releases will spur research and innovation in the fast-moving domain of voice technology. The speech recognition models released today outperform all existing open source speech recognition models across a variety of long-form speech recognition domains.
Quantification of stylistic differences in human- and ASR-produced transcripts of African American English
Sep 04, 2024



Common measures of accuracy used to assess the performance of automatic speech recognition (ASR) systems, as well as human transcribers, conflate multiple sources of error. Stylistic differences, such as verbatim vs non-verbatim, can play a significant role in ASR performance evaluation when differences exist between training and test datasets. The problem is compounded for speech from underrepresented varieties, where the speech to orthography mapping is not as standardized. We categorize the kinds of stylistic differences between 6 transcription versions, 4 human- and 2 ASR-produced, of 10 hours of African American English (AAE) speech. Focusing on verbatim features and AAE morphosyntactic features, we investigate the interactions of these categories with how well transcripts can be compared via word error rate (WER). The results, and overall analysis, help clarify how ASR outputs are a function of the decisions made by the training data's human transcribers.
Updated Corpora and Benchmarks for Long-Form Speech Recognition
Sep 26, 2023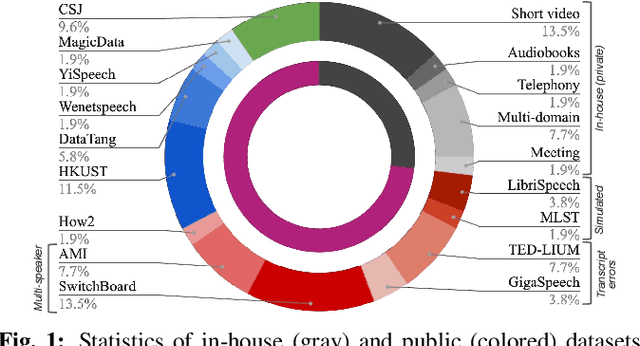
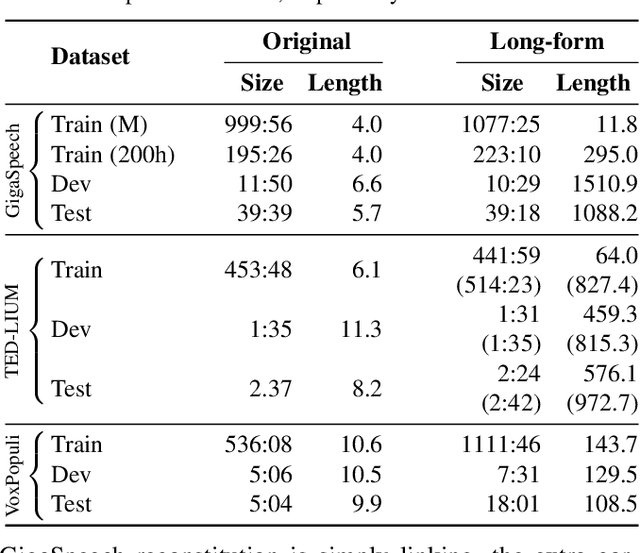

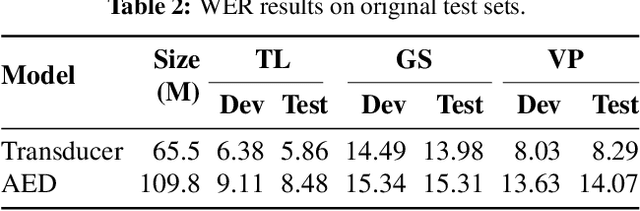
The vast majority of ASR research uses corpora in which both the training and test data have been pre-segmented into utterances. In most real-word ASR use-cases, however, test audio is not segmented, leading to a mismatch between inference-time conditions and models trained on segmented utterances. In this paper, we re-release three standard ASR corpora - TED-LIUM 3, Gigapeech, and VoxPopuli-en - with updated transcription and alignments to enable their use for long-form ASR research. We use these reconstituted corpora to study the train-test mismatch problem for transducers and attention-based encoder-decoders (AEDs), confirming that AEDs are more susceptible to this issue. Finally, we benchmark a simple long-form training for these models, showing its efficacy for model robustness under this domain shift.