 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses
Sep 17, 2024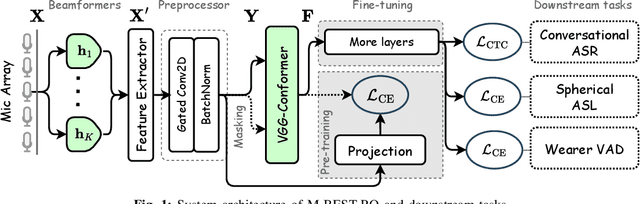

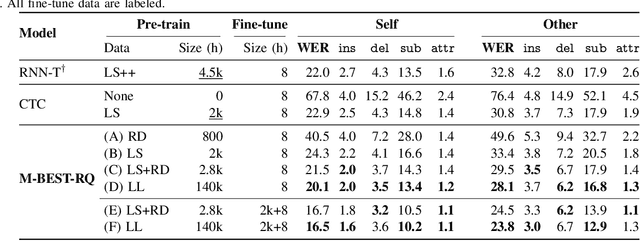
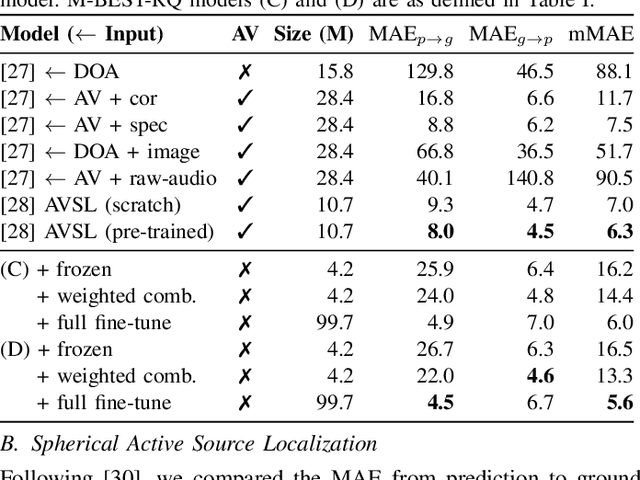
The growing popularity of multi-channel wearable devices, such as smart glasses, has led to a surge of applications such as targeted speech recognition and enhanced hearing. However, current approaches to solve these tasks use independently trained models, which may not benefit from large amounts of unlabeled data. In this paper, we propose M-BEST-RQ, the first multi-channel speech foundation model for smart glasses, which is designed to leverage large-scale self-supervised learning (SSL) in an array-geometry agnostic approach. While prior work on multi-channel speech SSL only evaluated on simulated settings, we curate a suite of real downstream tasks to evaluate our model, namely (i) conversational automatic speech recognition (ASR), (ii) spherical active source localization, and (iii) glasses wearer voice activity detection, which are sourced from the MMCSG and EasyCom datasets. We show that a general-purpose M-BEST-RQ encoder is able to match or surpass supervised models across all tasks. For the conversational ASR task in particular, using only 8 hours of labeled speech, our model outperforms a supervised ASR baseline that is trained on 2000 hours of labeled data, which demonstrates the effectiveness of our approach.
Faster Speech-LLaMA Inference with Multi-token Prediction
Sep 12, 2024



Large language models (LLMs) have become proficient at solving a wide variety of tasks, including those involving multi-modal inputs. In particular, instantiating an LLM (such as LLaMA) with a speech encoder and training it on paired data imparts speech recognition (ASR) abilities to the decoder-only model, hence called Speech-LLaMA. Nevertheless, due to the sequential nature of auto-regressive inference and the relatively large decoder, Speech-LLaMA models require relatively high inference time. In this work, we propose to speed up Speech-LLaMA inference by predicting multiple tokens in the same decoding step. We explore several model architectures that enable this, and investigate their performance using threshold-based and verification-based inference strategies. We also propose a prefix-based beam search decoding method that allows efficient minimum word error rate (MWER) training for such models. We evaluate our models on a variety of public benchmarks, where they reduce the number of decoder calls by ~3.2x while maintaining or improving WER performance.
Listening to Multi-talker Conversations: Modular and End-to-end Perspectives
Feb 14, 2024Since the first speech recognition systems were built more than 30 years ago, improvement in voice technology has enabled applications such as smart assistants and automated customer support. However, conversation intelligence of the future requires recognizing free-flowing multi-party conversations, which is a crucial and challenging component that still remains unsolved. In this dissertation, we focus on this problem of speaker-attributed multi-talker speech recognition, and propose two perspectives which result from its probabilistic formulation. In the modular perspective, we build a pipeline of sub-tasks involving speaker diarization, target speaker extraction, and speech recognition. Our first contribution is a method to perform overlap-aware diarization by reformulating spectral clustering as a constrained optimization problem. We also describe an algorithm to ensemble diarization outputs, either to combine overlap-aware systems or to perform multi-channel diarization by late fusion. Once speaker segments are identified, we robustly extract single-speaker utterances from the mixture using a GPU-accelerated implementation of guided source separation, which allows us to use an off-the-shelf ASR system to obtain speaker-attributed transcripts. Since the modular approach suffers from error propagation, we propose an alternate "end-to-end" perspective on the problem. For this, we describe the Streaming Unmixing and Recognition Transducer (SURT). We show how to train SURT models efficiently by carefully designing the network architecture, objective functions, and mixture simulation techniques. Finally, we add an auxiliary speaker branch to enable joint prediction of speaker labels synchronized with the speech tokens. We demonstrate that training on synthetic mixtures and adapting with real data helps these models transfer well for streaming transcription of real meeting sessions.
On Speaker Attribution with SURT
Jan 28, 2024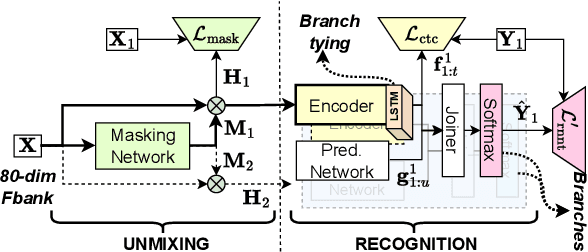
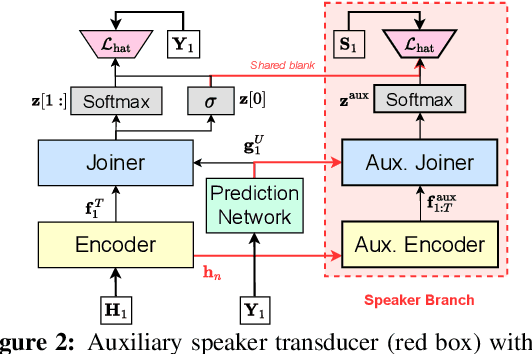

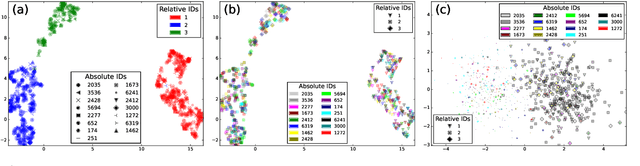
The Streaming Unmixing and Recognition Transducer (SURT) has recently become a popular framework for continuous, streaming, multi-talker speech recognition (ASR). With advances in architecture, objectives, and mixture simulation methods, it was demonstrated that SURT can be an efficient streaming method for speaker-agnostic transcription of real meetings. In this work, we push this framework further by proposing methods to perform speaker-attributed transcription with SURT, for both short mixtures and long recordings. We achieve this by adding an auxiliary speaker branch to SURT, and synchronizing its label prediction with ASR token prediction through HAT-style blank factorization. In order to ensure consistency in relative speaker labels across different utterance groups in a recording, we propose "speaker prefixing" -- appending each chunk with high-confidence frames of speakers identified in previous chunks, to establish the relative order. We perform extensive ablation experiments on synthetic LibriSpeech mixtures to validate our design choices, and demonstrate the efficacy of our final model on the AMI corpus.
Updated Corpora and Benchmarks for Long-Form Speech Recognition
Sep 26, 2023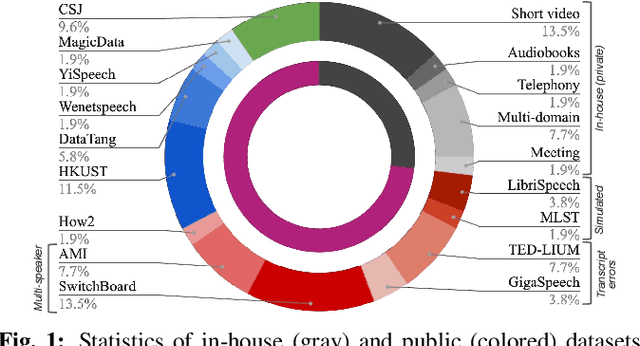
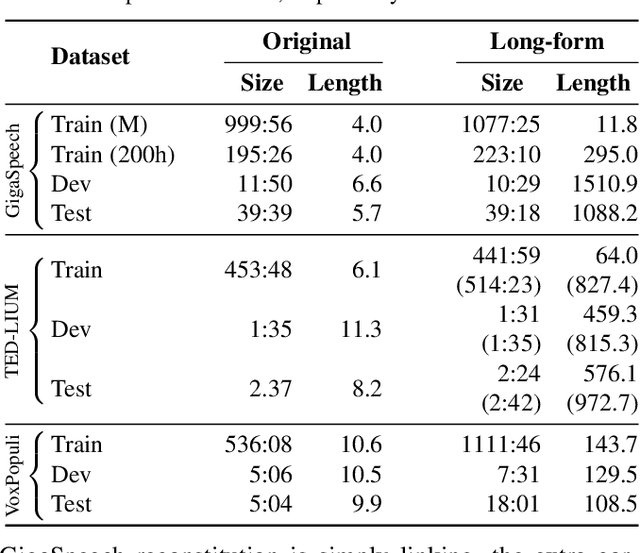

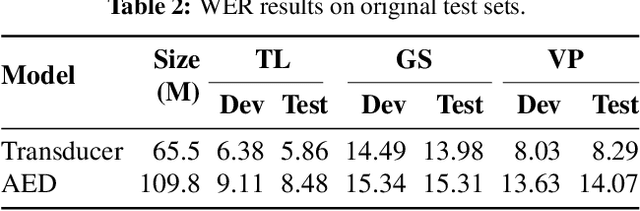
The vast majority of ASR research uses corpora in which both the training and test data have been pre-segmented into utterances. In most real-word ASR use-cases, however, test audio is not segmented, leading to a mismatch between inference-time conditions and models trained on segmented utterances. In this paper, we re-release three standard ASR corpora - TED-LIUM 3, Gigapeech, and VoxPopuli-en - with updated transcription and alignments to enable their use for long-form ASR research. We use these reconstituted corpora to study the train-test mismatch problem for transducers and attention-based encoder-decoders (AEDs), confirming that AEDs are more susceptible to this issue. Finally, we benchmark a simple long-form training for these models, showing its efficacy for model robustness under this domain shift.
Learning from Flawed Data: Weakly Supervised Automatic Speech Recognition
Sep 26, 2023



Training automatic speech recognition (ASR) systems requires large amounts of well-curated paired data. However, human annotators usually perform "non-verbatim" transcription, which can result in poorly trained models. In this paper, we propose Omni-temporal Classification (OTC), a novel training criterion that explicitly incorporates label uncertainties originating from such weak supervision. This allows the model to effectively learn speech-text alignments while accommodating errors present in the training transcripts. OTC extends the conventional CTC objective for imperfect transcripts by leveraging weighted finite state transducers. Through experiments conducted on the LibriSpeech and LibriVox datasets, we demonstrate that training ASR models with OTC avoids performance degradation even with transcripts containing up to 70% errors, a scenario where CTC models fail completely. Our implementation is available at https://github.com/k2-fsa/icefall.
Training dynamic models using early exits for automatic speech recognition on resource-constrained devices
Sep 18, 2023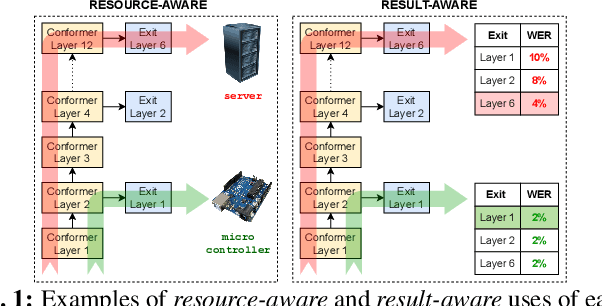
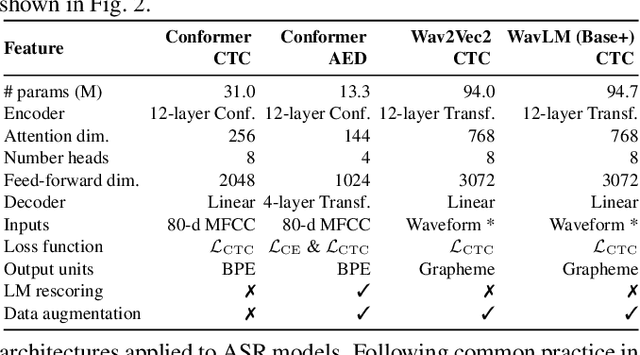
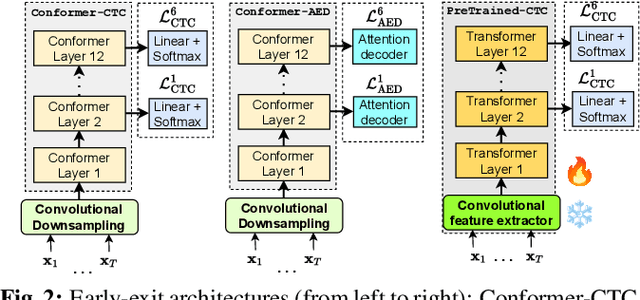
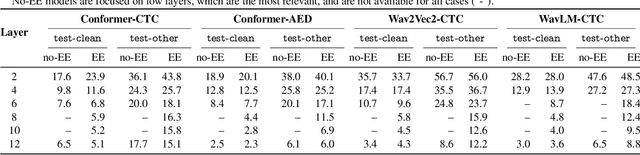
The possibility of dynamically modifying the computational load of neural models at inference time is crucial for on-device processing, where computational power is limited and time-varying. Established approaches for neural model compression exist, but they provide architecturally static models. In this paper, we investigate the use of early-exit architectures, that rely on intermediate exit branches, applied to large-vocabulary speech recognition. This allows for the development of dynamic models that adjust their computational cost to the available resources and recognition performance. Unlike previous works, besides using pre-trained backbones we also train the model from scratch with an early-exit architecture. Experiments on public datasets show that early-exit architectures from scratch not only preserve performance levels when using fewer encoder layers, but also improve task accuracy as compared to using single-exit models or using pre-trained models. Additionally, we investigate an exit selection strategy based on posterior probabilities as an alternative to frame-based entropy.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023



The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
SURT 2.0: Advances in Transducer-based Multi-talker Speech Recognition
Jun 18, 2023The Streaming Unmixing and Recognition Transducer (SURT) model was proposed recently as an end-to-end approach for continuous, streaming, multi-talker speech recognition (ASR). Despite impressive results on multi-turn meetings, SURT has notable limitations: (i) it suffers from leakage and omission related errors; (ii) it is computationally expensive, due to which it has not seen adoption in academia; and (iii) it has only been evaluated on synthetic mixtures. In this work, we propose several modifications to the original SURT which are carefully designed to fix the above limitations. In particular, we (i) change the unmixing module to a mask estimator that uses dual-path modeling, (ii) use a streaming zipformer encoder and a stateless decoder for the transducer, (iii) perform mixture simulation using force-aligned subsegments, (iv) pre-train the transducer on single-speaker data, (v) use auxiliary objectives in the form of masking loss and encoder CTC loss, and (vi) perform domain adaptation for far-field recognition. We show that our modifications allow SURT 2.0 to outperform its predecessor in terms of multi-talker ASR results, while being efficient enough to train with academic resources. We conduct our evaluations on 3 publicly available meeting benchmarks -- LibriCSS, AMI, and ICSI, where our best model achieves WERs of 16.9%, 44.6% and 32.2%, respectively, on far-field unsegmented recordings. We release training recipes and pre-trained models: https://sites.google.com/view/surt2.