 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne model to rule them all ? Towards End-to-End Joint Speaker Diarization and Speech Recognition
Oct 02, 2023This paper presents a novel framework for joint speaker diarization (SD) and automatic speech recognition (ASR), named SLIDAR (sliding-window diarization-augmented recognition). SLIDAR can process arbitrary length inputs and can handle any number of speakers, effectively solving ``who spoke what, when'' concurrently. SLIDAR leverages a sliding window approach and consists of an end-to-end diarization-augmented speech transcription (E2E DAST) model which provides, locally, for each window: transcripts, diarization and speaker embeddings. The E2E DAST model is based on an encoder-decoder architecture and leverages recent techniques such as serialized output training and ``Whisper-style" prompting. The local outputs are then combined to get the final SD+ASR result by clustering the speaker embeddings to get global speaker identities. Experiments performed on monaural recordings from the AMI corpus confirm the effectiveness of the method in both close-talk and far-field speech scenarios.
An enhanced system for the detection and active cancellation of snoring signals
Jul 31, 2023Snoring is a common disorder that affects people's social and marital lives. The annoyance caused by snoring can be partially solved with active noise control systems. In this context, the present work aims at introducing an enhanced system based on the use of a convolutional recurrent neural network for snoring activity detection and a delayless subband approach for active snoring cancellation. Thanks to several experiments conducted using real snoring signals, this work shows that the active snoring cancellation system achieves better performance when the snoring activity detection stage is turned on, demonstrating the beneficial effect of a preliminary snoring detection stage in the perspective of snoring cancellation.
A Time-Frequency Generative Adversarial based method for Audio Packet Loss Concealment
Jul 28, 2023



Packet loss is a major cause of voice quality degradation in VoIP transmissions with serious impact on intelligibility and user experience. This paper describes a system based on a generative adversarial approach, which aims to repair the lost fragments during the transmission of audio streams. Inspired by the powerful image-to-image translation capability of Generative Adversarial Networks (GANs), we propose bin2bin, an improved pix2pix framework to achieve the translation task from magnitude spectrograms of audio frames with lost packets, to noncorrupted speech spectrograms. In order to better maintain the structural information after spectrogram translation, this paper introduces the combination of two STFT-based loss functions, mixed with the traditional GAN objective. Furthermore, we employ a modified PatchGAN structure as discriminator and we lower the concealment time by a proper initialization of the phase reconstruction algorithm. Experimental results show that the proposed method has obvious advantages when compared with the current state-of-the-art methods, as it can better handle both high packet loss rates and large gaps.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023



The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
An Experimental Review of Speaker Diarization methods with application to Two-Speaker Conversational Telephone Speech recordings
May 29, 2023We performed an experimental review of current diarization systems for the conversational telephone speech (CTS) domain. In detail, we considered a total of eight different algorithms belonging to clustering-based, end-to-end neural diarization (EEND), and speech separation guided diarization (SSGD) paradigms. We studied the inference-time computational requirements and diarization accuracy on four CTS datasets with different characteristics and languages. We found that, among all methods considered, EEND-vector clustering (EEND-VC) offers the best trade-off in terms of computing requirements and performance. More in general, EEND models have been found to be lighter and faster in inference compared to clustering-based methods. However, they also require a large amount of diarization-oriented annotated data. In particular EEND-VC performance in our experiments degraded when the dataset size was reduced, whereas self-attentive EEND (SA-EEND) was less affected. We also found that SA-EEND gives less consistent results among all the datasets compared to EEND-VC, with its performance degrading on long conversations with high speech sparsity. Clustering-based diarization systems, and in particular VBx, instead have more consistent performance compared to SA-EEND but are outperformed by EEND-VC. The gap with respect to this latter is reduced when overlap-aware clustering methods are considered. SSGD is the most computationally demanding method, but it could be convenient if speech recognition has to be performed. Its performance is close to SA-EEND but degrades significantly when the training and inference data characteristics are less matched.
End-to-End Integration of Speech Separation and Voice Activity Detection for Low-Latency Diarization of Telephone Conversations
Mar 21, 2023Recent works show that speech separation guided diarization (SSGD) is an increasingly promising direction, mainly thanks to the recent progress in speech separation. It performs diarization by first separating the speakers and then applying voice activity detection (VAD) on each separated stream. In this work we conduct an in-depth study of SSGD in the conversational telephone speech (CTS) domain, focusing mainly on low-latency streaming diarization applications. We consider three state-of-the-art speech separation (SSep) algorithms and study their performance both in online and offline scenarios, considering non-causal and causal implementations as well as continuous SSep (CSS) windowed inference. We compare different SSGD algorithms on two widely used CTS datasets: CALLHOME and Fisher Corpus (Part 1 and 2) and evaluate both separation and diarization performance. To improve performance, a novel, causal and computationally efficient leakage removal algorithm is proposed, which significantly decreases false alarms. We also explore, for the first time, fully end-to-end SSGD integration between SSep and VAD modules. Crucially, this enables fine-tuning on real-world data for which oracle speakers sources are not available. In particular, our best model achieves 8.8% DER on CALLHOME, which outperforms the current state-of-the-art end-to-end neural diarization model, despite being trained on an order of magnitude less data and having significantly lower latency, i.e., 0.1 vs. 1 seconds. Finally, we also show that the separated signals can be readily used also for automatic speech recognition, reaching performance close to using oracle sources in some configurations.
Conversational Speech Separation: an Evaluation Study for Streaming Applications
May 31, 2022
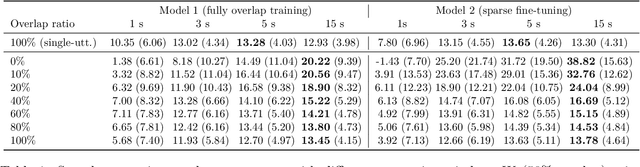
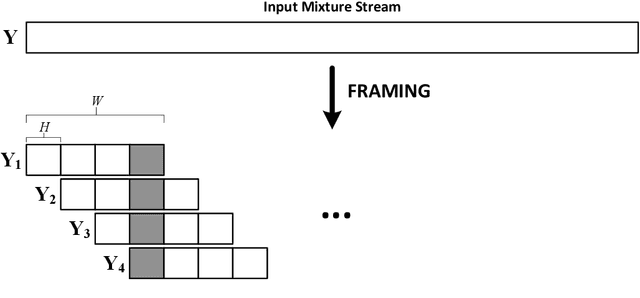
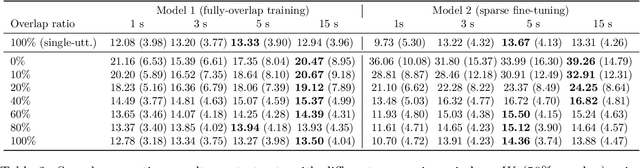
Continuous speech separation (CSS) is a recently proposed framework which aims at separating each speaker from an input mixture signal in a streaming fashion. Hereafter we perform an evaluation study on practical design considerations for a CSS system, addressing important aspects which have been neglected in recent works. In particular, we focus on the trade-off between separation performance, computational requirements and output latency showing how an offline separation algorithm can be used to perform CSS with a desired latency. We carry out an extensive analysis on the choice of CSS processing window size and hop size on sparsely overlapped data. We find out that the best trade-off between computational burden and performance is obtained for a window of 5 s.
Leveraging Speech Separation for Conversational Telephone Speaker Diarization
Apr 05, 2022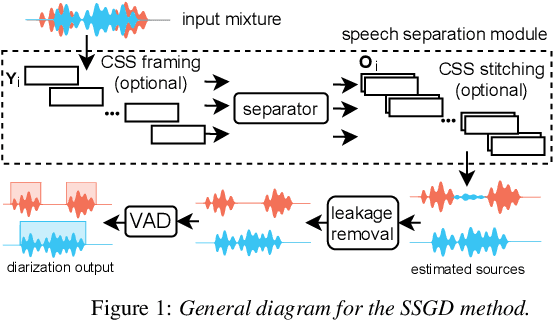
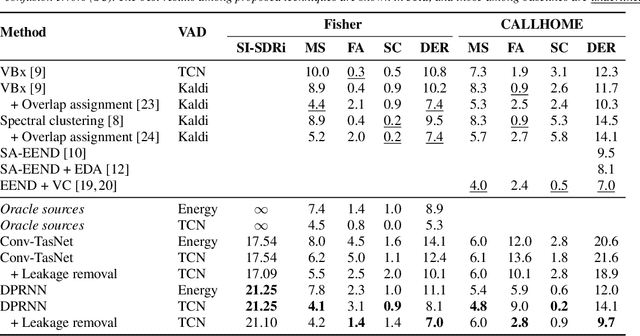

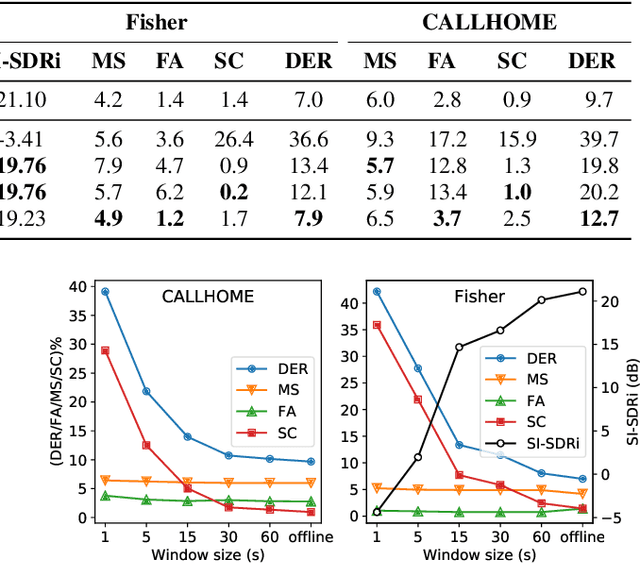
Speech separation and speaker diarization have strong similarities. In particular with respect to end-to-end neural diarization (EEND) methods. Separation aims at extracting each speaker from overlapped speech, while diarization identifies time boundaries of speech segments produced by the same speaker. In this paper, we carry out an analysis of the use of speech separation guided diarization (SSGD) where diarization is performed simply by separating the speakers signals and applying voice activity detection. In particular we compare two speech separation (SSep) models, both in offline and online settings. In the online setting we consider both the use of continuous source separation (CSS) and causal SSep models architectures. As an additional contribution, we show a simple post-processing algorithm which reduces significantly the false alarm errors of a SSGD pipeline. We perform our experiments on Fisher Corpus Part 1 and CALLHOME datasets evaluating both separation and diarization metrics. Notably, without fine-tuning, our SSGD DPRNN-based online model achieves 12.7% DER on CALLHOME, comparable with state-of-the-art EEND models despite having considerably lower latency, i.e., 50 ms vs 1 s.
Learning Filterbanks for End-to-End Acoustic Beamforming
Nov 08, 2021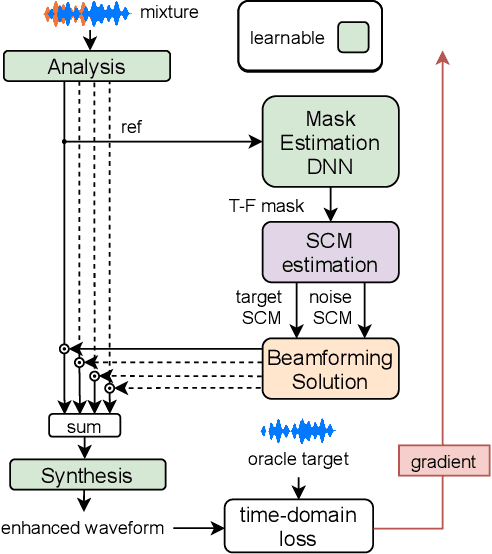
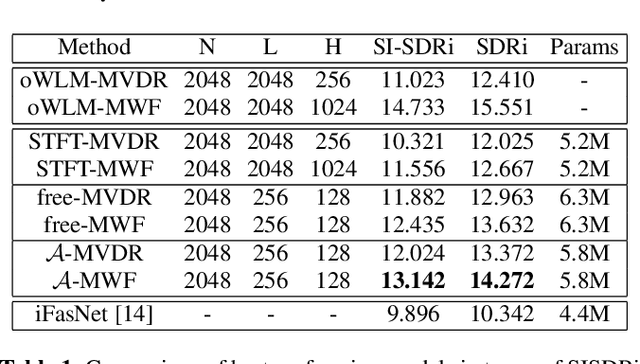
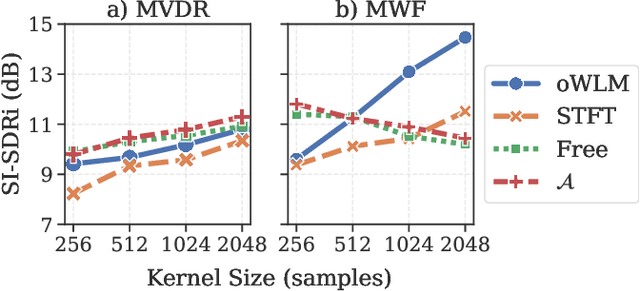
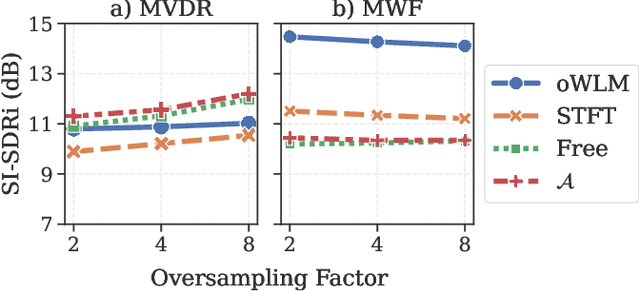
Recent work on monaural source separation has shown that performance can be increased by using fully learned filterbanks with short windows. On the other hand it is widely known that, for conventional beamforming techniques, performance increases with long analysis windows. This applies also to most hybrid neural beamforming methods which rely on a deep neural network (DNN) to estimate the spatial covariance matrices. In this work we try to bridge the gap between these two worlds and explore fully end-to-end hybrid neural beamforming in which, instead of using the Short-Time-Fourier Transform, also the analysis and synthesis filterbanks are learnt jointly with the DNN. In detail, we explore two different types of learned filterbanks: fully learned and analytic. We perform a detailed analysis using the recent Clarity Challenge data and show that by using learnt filterbanks is possible to surpass oracle-mask based beamforming for short windows.
Deep Optimization of Parametric IIR Filters for Audio Equalization
Oct 05, 2021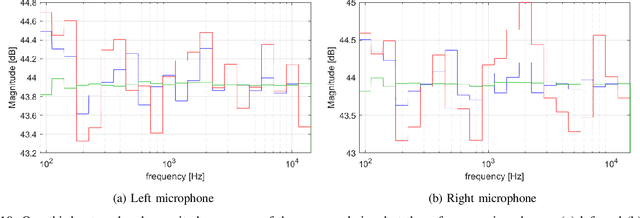
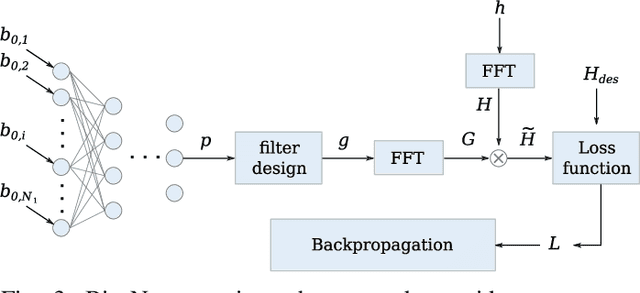
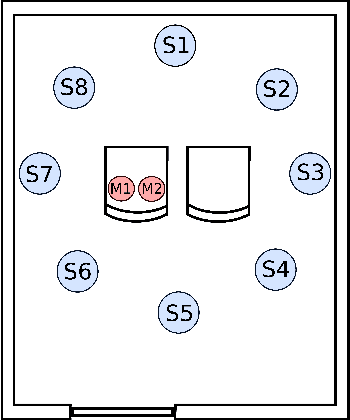
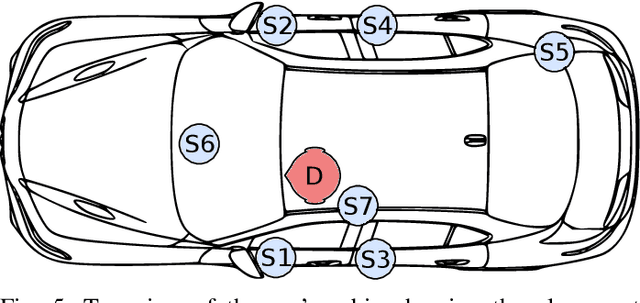
This paper describes a novel Deep Learning method for the design of IIR parametric filters for automatic audio equalization. A simple and effective neural architecture, named BiasNet, is proposed to determine the IIR equalizer parameters. An output denormalization technique is used to obtain accurate tuning of the IIR filters center frequency, quality factor and gain. All layers involved in the proposed method are shown to be differentiable, allowing backpropagation to optimize the network weights and achieve, after a number of training iterations, the optimal output. The parameters are optimized with respect to a loss function based on a spectral distance between the measured and desired magnitude response, and a regularization term used to achieve a spatialization of the acoustc scene. Two scenarios with different characteristics were considered for the experimental evaluation: a room and a car cabin. The performance of the proposed method improves over the baseline techniques and achieves an almost flat band. Moreover IIR filters provide a consistently lower computational cost during runtime with respect to FIR filters.