 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Speech Separation: an Evaluation Study for Streaming Applications
Paper and Code
May 31, 2022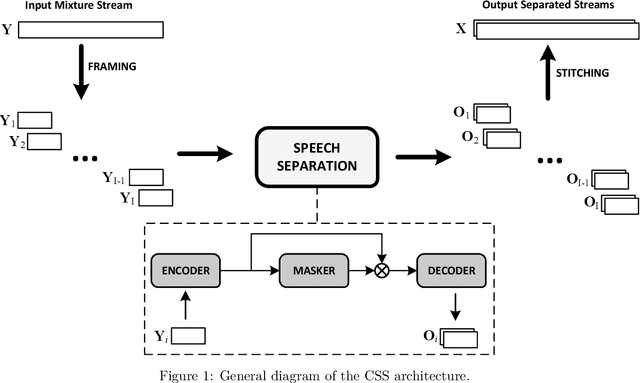
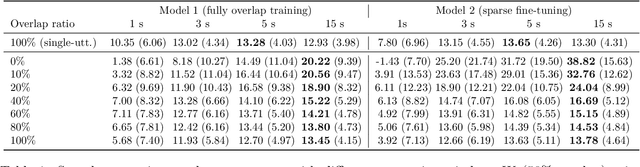
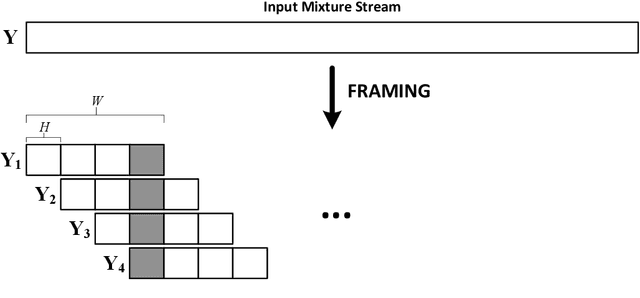
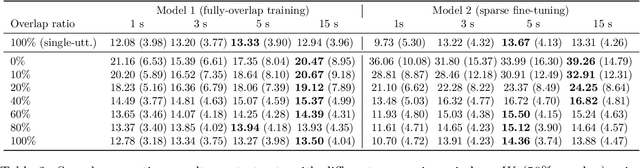
Continuous speech separation (CSS) is a recently proposed framework which aims at separating each speaker from an input mixture signal in a streaming fashion. Hereafter we perform an evaluation study on practical design considerations for a CSS system, addressing important aspects which have been neglected in recent works. In particular, we focus on the trade-off between separation performance, computational requirements and output latency showing how an offline separation algorithm can be used to perform CSS with a desired latency. We carry out an extensive analysis on the choice of CSS processing window size and hop size on sparsely overlapped data. We find out that the best trade-off between computational burden and performance is obtained for a window of 5 s.