 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Speech Separation for Conversational Telephone Speaker Diarization
Paper and Code
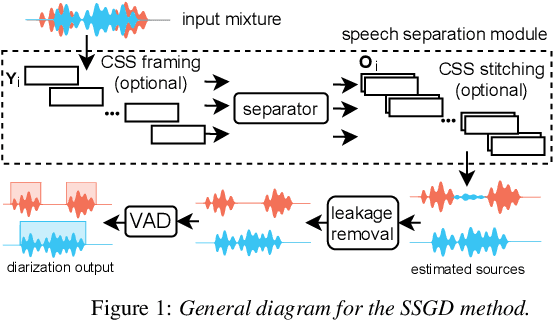
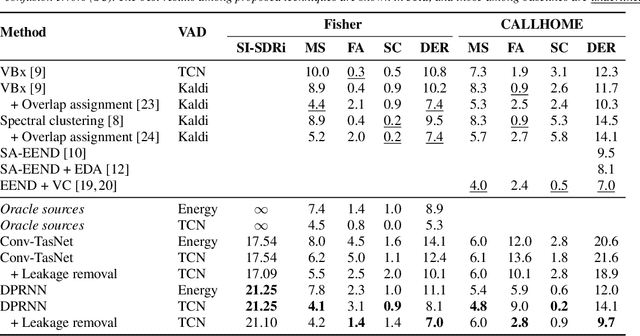

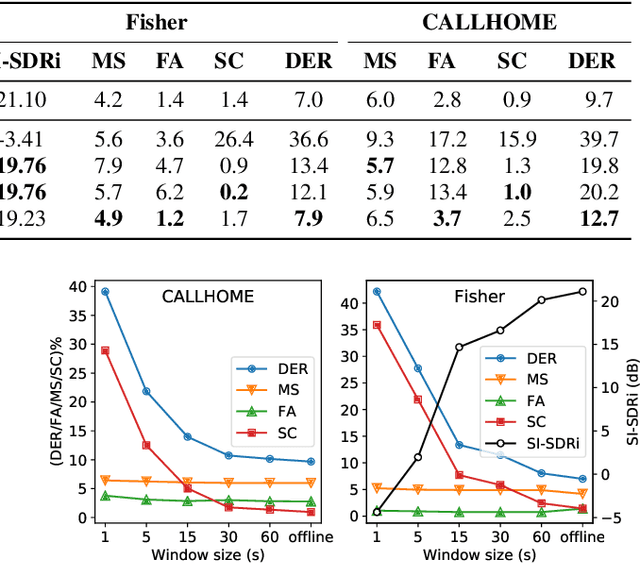
Speech separation and speaker diarization have strong similarities. In particular with respect to end-to-end neural diarization (EEND) methods. Separation aims at extracting each speaker from overlapped speech, while diarization identifies time boundaries of speech segments produced by the same speaker. In this paper, we carry out an analysis of the use of speech separation guided diarization (SSGD) where diarization is performed simply by separating the speakers signals and applying voice activity detection. In particular we compare two speech separation (SSep) models, both in offline and online settings. In the online setting we consider both the use of continuous source separation (CSS) and causal SSep models architectures. As an additional contribution, we show a simple post-processing algorithm which reduces significantly the false alarm errors of a SSGD pipeline. We perform our experiments on Fisher Corpus Part 1 and CALLHOME datasets evaluating both separation and diarization metrics. Notably, without fine-tuning, our SSGD DPRNN-based online model achieves 12.7% DER on CALLHOME, comparable with state-of-the-art EEND models despite having considerably lower latency, i.e., 50 ms vs 1 s.