 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Efficient Streaming LLM for Speech Recognition
Oct 02, 2024



Recent works have shown that prompting large language models with audio encodings can unlock speech recognition capabilities. However, existing techniques do not scale efficiently, especially while handling long form streaming audio inputs -- not only do they extrapolate poorly beyond the audio length seen during training, but they are also computationally inefficient due to the quadratic cost of attention. In this work, we introduce SpeechLLM-XL, a linear scaling decoder-only model for streaming speech recognition. We process audios in configurable chunks using limited attention window for reduced computation, and the text tokens for each audio chunk are generated auto-regressively until an EOS is predicted. During training, the transcript is segmented into chunks, using a CTC forced alignment estimated from encoder output. SpeechLLM-XL with 1.28 seconds chunk size achieves 2.7%/6.7% WER on LibriSpeech test clean/other, and it shows no quality degradation on long form utterances 10x longer than the training utterances.
M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses
Sep 17, 2024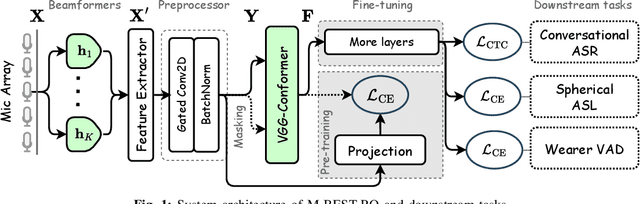

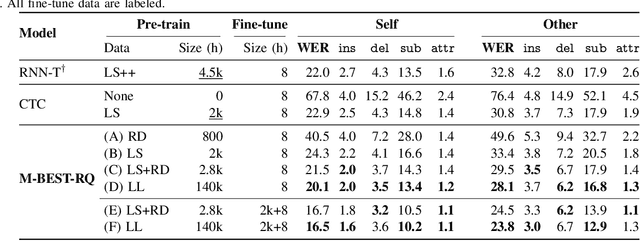
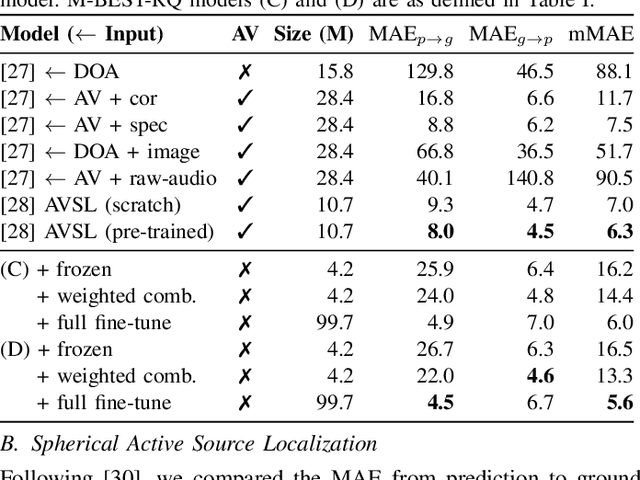
The growing popularity of multi-channel wearable devices, such as smart glasses, has led to a surge of applications such as targeted speech recognition and enhanced hearing. However, current approaches to solve these tasks use independently trained models, which may not benefit from large amounts of unlabeled data. In this paper, we propose M-BEST-RQ, the first multi-channel speech foundation model for smart glasses, which is designed to leverage large-scale self-supervised learning (SSL) in an array-geometry agnostic approach. While prior work on multi-channel speech SSL only evaluated on simulated settings, we curate a suite of real downstream tasks to evaluate our model, namely (i) conversational automatic speech recognition (ASR), (ii) spherical active source localization, and (iii) glasses wearer voice activity detection, which are sourced from the MMCSG and EasyCom datasets. We show that a general-purpose M-BEST-RQ encoder is able to match or surpass supervised models across all tasks. For the conversational ASR task in particular, using only 8 hours of labeled speech, our model outperforms a supervised ASR baseline that is trained on 2000 hours of labeled data, which demonstrates the effectiveness of our approach.
Faster Speech-LLaMA Inference with Multi-token Prediction
Sep 12, 2024



Large language models (LLMs) have become proficient at solving a wide variety of tasks, including those involving multi-modal inputs. In particular, instantiating an LLM (such as LLaMA) with a speech encoder and training it on paired data imparts speech recognition (ASR) abilities to the decoder-only model, hence called Speech-LLaMA. Nevertheless, due to the sequential nature of auto-regressive inference and the relatively large decoder, Speech-LLaMA models require relatively high inference time. In this work, we propose to speed up Speech-LLaMA inference by predicting multiple tokens in the same decoding step. We explore several model architectures that enable this, and investigate their performance using threshold-based and verification-based inference strategies. We also propose a prefix-based beam search decoding method that allows efficient minimum word error rate (MWER) training for such models. We evaluate our models on a variety of public benchmarks, where they reduce the number of decoder calls by ~3.2x while maintaining or improving WER performance.
Token-Weighted RNN-T for Learning from Flawed Data
Jun 26, 2024ASR models are commonly trained with the cross-entropy criterion to increase the probability of a target token sequence. While optimizing the probability of all tokens in the target sequence is sensible, one may want to de-emphasize tokens that reflect transcription errors. In this work, we propose a novel token-weighted RNN-T criterion that augments the RNN-T objective with token-specific weights. The new objective is used for mitigating accuracy loss from transcriptions errors in the training data, which naturally appear in two settings: pseudo-labeling and human annotation errors. Experiments results show that using our method for semi-supervised learning with pseudo-labels leads to a consistent accuracy improvement, up to 38% relative. We also analyze the accuracy degradation resulting from different levels of WER in the reference transcription, and show that token-weighted RNN-T is suitable for overcoming this degradation, recovering 64%-99% of the accuracy loss.
Towards Selection of Text-to-speech Data to Augment ASR Training
May 30, 2023



This paper presents a method for selecting appropriate synthetic speech samples from a given large text-to-speech (TTS) dataset as supplementary training data for an automatic speech recognition (ASR) model. We trained a neural network, which can be optimised using cross-entropy loss or Arcface loss, to measure the similarity of a synthetic data to real speech. We found that incorporating synthetic samples with considerable dissimilarity to real speech, owing in part to lexical differences, into ASR training is crucial for boosting recognition performance. Experimental results on Librispeech test sets indicate that, in order to maintain the same speech recognition accuracy as when using all TTS data, our proposed solution can reduce the size of the TTS data down below its $30\,\%$, which is superior to several baseline methods.
Text Generation with Speech Synthesis for ASR Data Augmentation
May 22, 2023
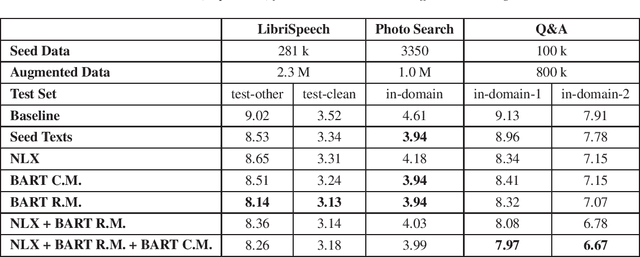
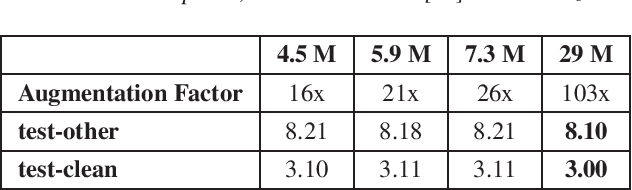
Aiming at reducing the reliance on expensive human annotations, data synthesis for Automatic Speech Recognition (ASR) has remained an active area of research. While prior work mainly focuses on synthetic speech generation for ASR data augmentation, its combination with text generation methods is considerably less explored. In this work, we explore text augmentation for ASR using large-scale pre-trained neural networks, and systematically compare those to traditional text augmentation methods. The generated synthetic texts are then converted to synthetic speech using a text-to-speech (TTS) system and added to the ASR training data. In experiments conducted on three datasets, we find that neural models achieve 9%-15% relative WER improvement and outperform traditional methods. We conclude that text augmentation, particularly through modern neural approaches, is a viable tool for improving the accuracy of ASR systems.
A Token-Wise Beam Search Algorithm for RNN-T
Feb 28, 2023



Standard Recurrent Neural Network Transducers (RNN-T) decoding algorithms for speech recognition are iterating over the time axis, such that one time step is decoded before moving on to the next time step. Those algorithms result in a large number of calls to the joint network, that were shown in previous work to be an important factor that reduces decoding speed. We present a decoding beam search algorithm that batches the joint network calls across a segment of time steps, which results in 40%-70% decoding speedups, consistently across all models and settings experimented with. In addition, aggregating emission probabilities over a segment may be seen as a better approximation to finding the most likely model output, causing our algorithm to improve oracle word error rate by up to 10% relative as the segment size increases, and to slightly improve general word error rate.
Improving Fast-slow Encoder based Transducer with Streaming Deliberation
Dec 15, 2022This paper introduces a fast-slow encoder based transducer with streaming deliberation for end-to-end automatic speech recognition. We aim to improve the recognition accuracy of the fast-slow encoder based transducer while keeping its latency low by integrating a streaming deliberation model. Specifically, the deliberation model leverages partial hypotheses from the streaming fast encoder and implicitly learns to correct recognition errors. We modify the parallel beam search algorithm for fast-slow encoder based transducer to be efficient and compatible with the deliberation model. In addition, the deliberation model is designed to process streaming data. To further improve the deliberation performance, a simple text augmentation approach is explored. We also compare LSTM and Conformer models for encoding partial hypotheses. Experiments on Librispeech and in-house data show relative WER reductions (WERRs) from 3% to 5% with a slight increase in model size and negligible extra token emission latency compared with fast-slow encoder based transducer. Compared with vanilla neural transducers, the proposed deliberation model together with fast-slow encoder based transducer obtains relative 10-11% WERRs on Librispeech and around relative 6% WERR on in-house data with smaller emission delays.