 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Frozen Large Language Models Can Perceive Paralinguistic Aspects of Speech
Oct 02, 2024



As speech becomes an increasingly common modality for interacting with large language models (LLMs), it is becoming desirable to develop systems where LLMs can take into account users' emotions or speaking styles when providing their responses. In this work, we study the potential of an LLM to understand these aspects of speech without fine-tuning its weights. To do this, we utilize an end-to-end system with a speech encoder; the encoder is trained to produce token embeddings such that the LLM's response to an expressive speech prompt is aligned with its response to a semantically matching text prompt where the speaker's emotion has also been specified. We find that this training framework allows the encoder to generate tokens that capture both semantic and paralinguistic information in speech and effectively convey it to the LLM, even when the LLM remains completely frozen. We also explore training on additional emotion and style-related response alignment tasks, finding that they further increase the amount of paralinguistic information explicitly captured in the speech tokens. Experiments demonstrate that our system is able to produce higher quality and more empathetic responses to expressive speech prompts compared to several baselines.
Efficient Streaming LLM for Speech Recognition
Oct 02, 2024



Recent works have shown that prompting large language models with audio encodings can unlock speech recognition capabilities. However, existing techniques do not scale efficiently, especially while handling long form streaming audio inputs -- not only do they extrapolate poorly beyond the audio length seen during training, but they are also computationally inefficient due to the quadratic cost of attention. In this work, we introduce SpeechLLM-XL, a linear scaling decoder-only model for streaming speech recognition. We process audios in configurable chunks using limited attention window for reduced computation, and the text tokens for each audio chunk are generated auto-regressively until an EOS is predicted. During training, the transcript is segmented into chunks, using a CTC forced alignment estimated from encoder output. SpeechLLM-XL with 1.28 seconds chunk size achieves 2.7%/6.7% WER on LibriSpeech test clean/other, and it shows no quality degradation on long form utterances 10x longer than the training utterances.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Speech ReaLLM -- Real-time Streaming Speech Recognition with Multimodal LLMs by Teaching the Flow of Time
Jun 13, 2024We introduce Speech ReaLLM, a new ASR architecture that marries "decoder-only" ASR with the RNN-T to make multimodal LLM architectures capable of real-time streaming. This is the first "decoder-only" ASR architecture designed to handle continuous audio without explicit end-pointing. Speech ReaLLM is a special case of the more general ReaLLM ("real-time LLM") approach, also introduced here for the first time. The idea is inspired by RNN-T: Instead of generating a response only at the end of a user prompt, generate after every input token received in real time (it is often empty). On Librispeech "test", an 80M Speech ReaLLM achieves WERs of 3.0% and 7.4% in real time (without an external LM or auxiliary loss). This is only slightly above a 3x larger Attention-Encoder-Decoder baseline. We also show that this way, an LLM architecture can learn to represent and reproduce the flow of time; and that a pre-trained 7B LLM can be fine-tuned to do reasonably well on this task.
Effective internal language model training and fusion for factorized transducer model
Apr 02, 2024


The internal language model (ILM) of the neural transducer has been widely studied. In most prior work, it is mainly used for estimating the ILM score and is subsequently subtracted during inference to facilitate improved integration with external language models. Recently, various of factorized transducer models have been proposed, which explicitly embrace a standalone internal language model for non-blank token prediction. However, even with the adoption of factorized transducer models, limited improvement has been observed compared to shallow fusion. In this paper, we propose a novel ILM training and decoding strategy for factorized transducer models, which effectively combines the blank, acoustic and ILM scores. Our experiments show a 17% relative improvement over the standard decoding method when utilizing a well-trained ILM and the proposed decoding strategy on LibriSpeech datasets. Furthermore, when compared to a strong RNN-T baseline enhanced with external LM fusion, the proposed model yields a 5.5% relative improvement on general-sets and an 8.9% WER reduction for rare words. The proposed model can achieve superior performance without relying on external language models, rendering it highly efficient for production use-cases. To further improve the performance, we propose a novel and memory-efficient ILM-fusion-aware minimum word error rate (MWER) training method which improves ILM integration significantly.
Towards General-Purpose Speech Abilities for Large Language Models Using Unpaired Data
Nov 12, 2023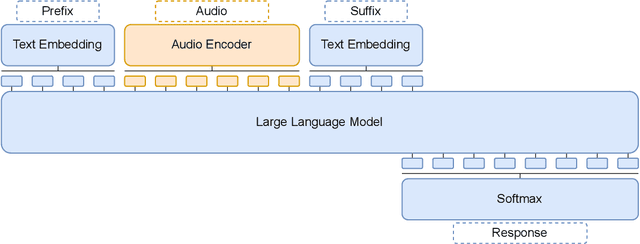

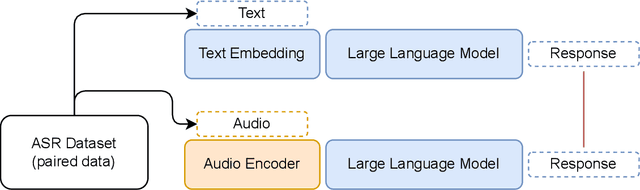
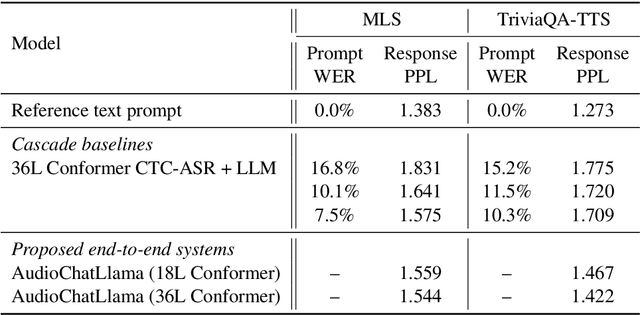
In this work, we extend the instruction-tuned Llama-2 model with end-to-end general-purpose speech processing and reasoning abilities while maintaining the wide range of LLM capabilities, without using any carefully curated paired data. The proposed model can utilize audio prompts as a replacement for text and sustain a conversation. Such a model also has extended cross-modal capabilities such as being able to perform speech question answering, speech translation, and audio summarization amongst many other closed and open-domain tasks. This is unlike prior approaches in speech, in which LLMs are extended to handle audio for a limited number of pre-designated tasks. Experiments show that our end-to-end approach is on par with or outperforms a cascaded system (speech recognizer + LLM) in terms of modeling the response to a prompt. Furthermore, unlike a cascade, our approach shows the ability to interchange text and audio modalities and utilize the prior context in a conversation to provide better results.
Dynamic ASR Pathways: An Adaptive Masking Approach Towards Efficient Pruning of A Multilingual ASR Model
Sep 22, 2023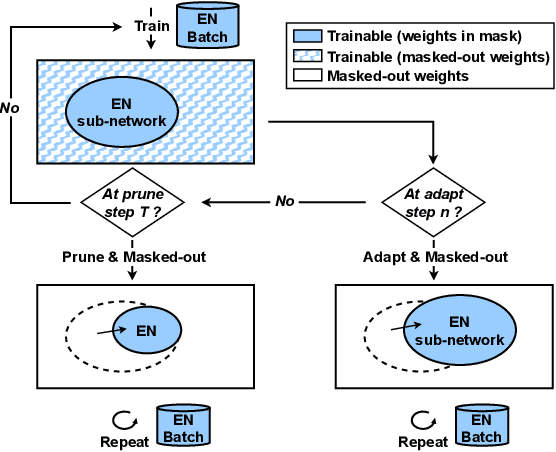



Neural network pruning offers an effective method for compressing a multilingual automatic speech recognition (ASR) model with minimal performance loss. However, it entails several rounds of pruning and re-training needed to be run for each language. In this work, we propose the use of an adaptive masking approach in two scenarios for pruning a multilingual ASR model efficiently, each resulting in sparse monolingual models or a sparse multilingual model (named as Dynamic ASR Pathways). Our approach dynamically adapts the sub-network, avoiding premature decisions about a fixed sub-network structure. We show that our approach outperforms existing pruning methods when targeting sparse monolingual models. Further, we illustrate that Dynamic ASR Pathways jointly discovers and trains better sub-networks (pathways) of a single multilingual model by adapting from different sub-network initializations, thereby reducing the need for language-specific pruning.
End-to-End Speech Recognition Contextualization with Large Language Models
Sep 19, 2023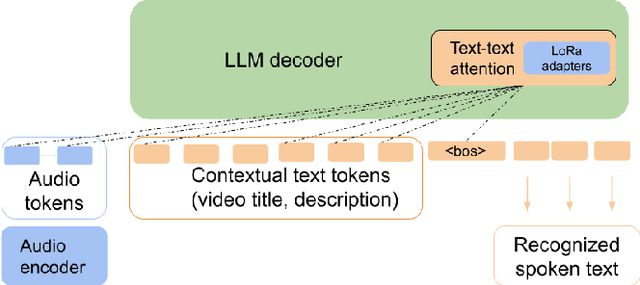

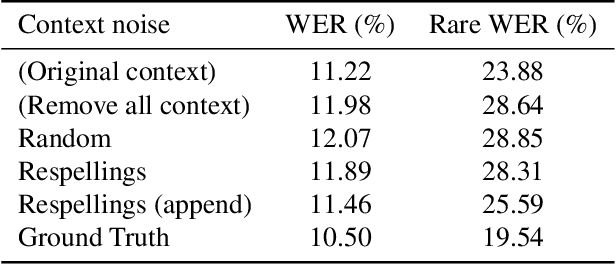

In recent years, Large Language Models (LLMs) have garnered significant attention from the research community due to their exceptional performance and generalization capabilities. In this paper, we introduce a novel method for contextualizing speech recognition models incorporating LLMs. Our approach casts speech recognition as a mixed-modal language modeling task based on a pretrained LLM. We provide audio features, along with optional text tokens for context, to train the system to complete transcriptions in a decoder-only fashion. As a result, the system is implicitly incentivized to learn how to leverage unstructured contextual information during training. Our empirical results demonstrate a significant improvement in performance, with a 6% WER reduction when additional textual context is provided. Moreover, we find that our method performs competitively and improve by 7.5% WER overall and 17% WER on rare words against a baseline contextualized RNN-T system that has been trained on more than twenty five times larger speech dataset. Overall, we demonstrate that by only adding a handful number of trainable parameters via adapters, we can unlock contextualized speech recognition capability for the pretrained LLM while keeping the same text-only input functionality.
TODM: Train Once Deploy Many Efficient Supernet-Based RNN-T Compression For On-device ASR Models
Sep 05, 2023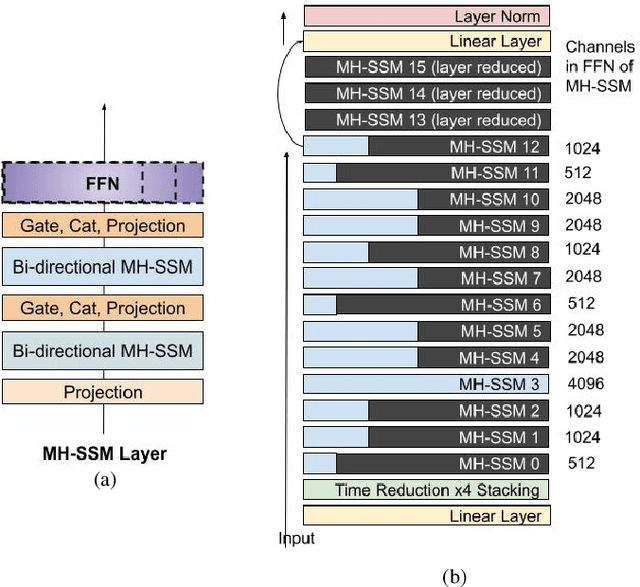
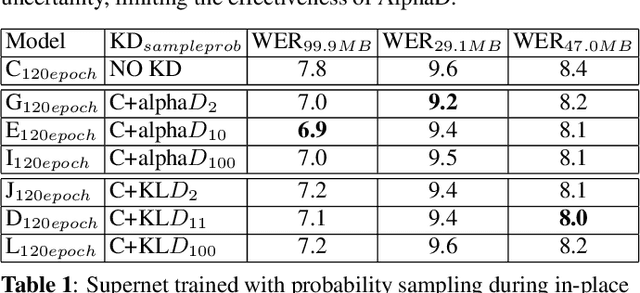
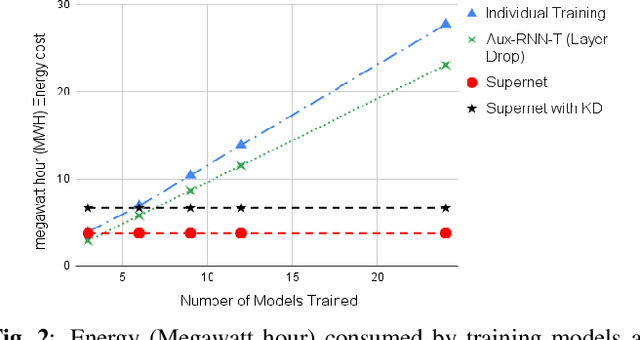
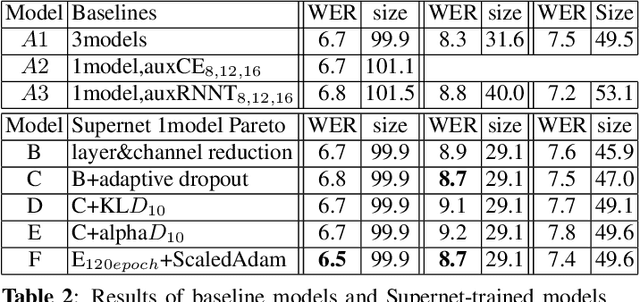
Automatic Speech Recognition (ASR) models need to be optimized for specific hardware before they can be deployed on devices. This can be done by tuning the model's hyperparameters or exploring variations in its architecture. Re-training and re-validating models after making these changes can be a resource-intensive task. This paper presents TODM (Train Once Deploy Many), a new approach to efficiently train many sizes of hardware-friendly on-device ASR models with comparable GPU-hours to that of a single training job. TODM leverages insights from prior work on Supernet, where Recurrent Neural Network Transducer (RNN-T) models share weights within a Supernet. It reduces layer sizes and widths of the Supernet to obtain subnetworks, making them smaller models suitable for all hardware types. We introduce a novel combination of three techniques to improve the outcomes of the TODM Supernet: adaptive dropouts, an in-place Alpha-divergence knowledge distillation, and the use of ScaledAdam optimizer. We validate our approach by comparing Supernet-trained versus individually tuned Multi-Head State Space Model (MH-SSM) RNN-T using LibriSpeech. Results demonstrate that our TODM Supernet either matches or surpasses the performance of manually tuned models by up to a relative of 3% better in word error rate (WER), while efficiently keeping the cost of training many models at a small constant.