 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Margin and Boundary: Are Your Distilled Datasets Truly Robust?
May 20, 2026Dataset distillation (DD) compresses a large training set into a small synthetic set for efficient training, but most DD methods optimize only clean accuracy and leave robustness uncontrolled. Recent robust DD methods improve robustness, yet they often suffer from a poor accuracy-robustness trade-off because they (i) treat all adversarially perturbed examples uniformly, despite robust risk being dominated by near-zero robust margins, and (ii) do not explicitly increase inter-class separation in the decision boundary where attacks concentrate. We present Contrastive Curriculum for Robust Dataset Distillation (C$^2$R), a framework that couples an attack-aware curriculum with a contrastive robustness objective. From a robust-margin perspective, we derive a perturbation score that approximates each sample's robust hinge, enabling a curriculum that prioritizes the smallest-margin adversaries that most directly drive robust error. In parallel, a class-balanced contrastive robustness loss enforces adversarial invariance while explicitly widening boundary separation across classes. Experiments on CIFAR-10/100, Tiny-ImageNet, and multiple ImageNet-1K subsets under six attacks show that C$^2$R achieves the best robust accuracy, outperforming prior robust DD by $2.8$% on average.
Fixed Anchors Are Not Enough: Dynamic Retrieval and Persistent Homology for Dataset Distillation
Feb 27, 2026Decoupled dataset distillation (DD) compresses large corpora into a few synthetic images by matching a frozen teacher's statistics. However, current residual-matching pipelines rely on static real patches, creating a fit-complexity gap and a pull-to-anchor effect that reduce intra-class diversity and hurt generalization. To address these issues, we introduce RETA -- a Retrieval and Topology Alignment framework for decoupled DD. First, Dynamic Retrieval Connection (DRC) selects a real patch from a prebuilt pool by minimizing a fit-complexity score in teacher feature space; the chosen patch is injected via a residual connection to tighten feature fit while controlling injected complexity. Second, Persistent Topology Alignment (PTA) regularizes synthesis with persistent homology: we build a mutual k-NN feature graph, compute persistence images of components and loops, and penalize topology discrepancies between real and synthetic sets, mitigating pull-to-anchor effect. Across CIFAR-100, Tiny-ImageNet, ImageNet-1K, and multiple ImageNet subsets, RETA consistently outperforms various baselines under comparable time and memory, especially reaching 64.3% top-1 accuracy on ImageNet-1K with ResNet-18 at 50 images per class, +3.1% over the best prior.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Transducer-Llama: Integrating LLMs into Streamable Transducer-based Speech Recognition
Dec 21, 2024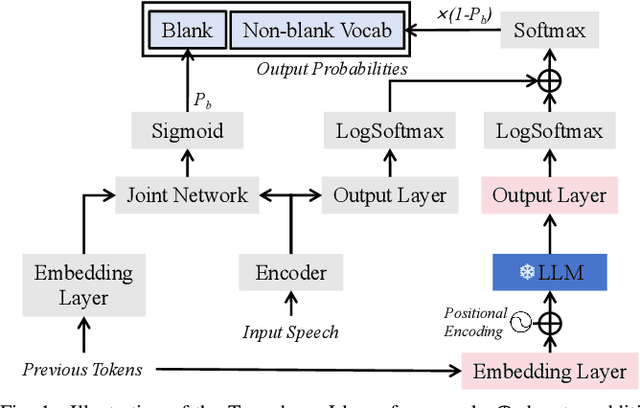
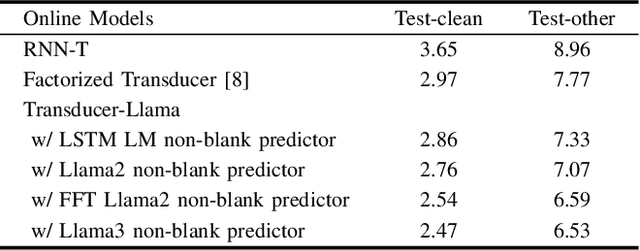
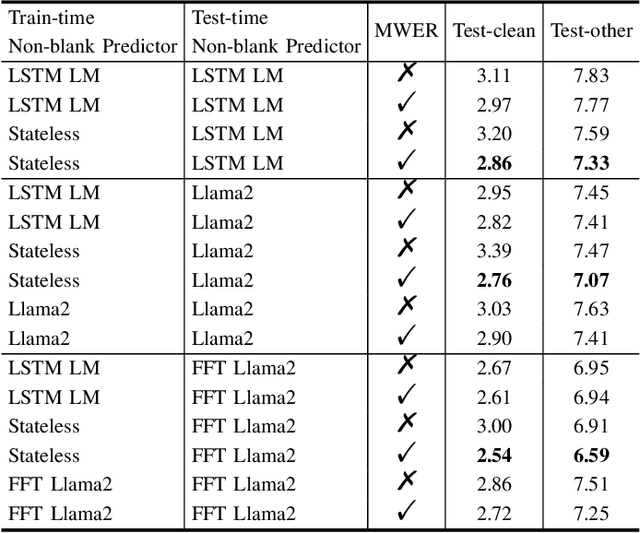
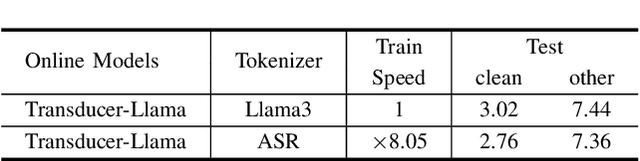
While large language models (LLMs) have been applied to automatic speech recognition (ASR), the task of making the model streamable remains a challenge. This paper proposes a novel model architecture, Transducer-Llama, that integrates LLMs into a Factorized Transducer (FT) model, naturally enabling streaming capabilities. Furthermore, given that the large vocabulary of LLMs can cause data sparsity issue and increased training costs for spoken language systems, this paper introduces an efficient vocabulary adaptation technique to align LLMs with speech system vocabularies. The results show that directly optimizing the FT model with a strong pre-trained LLM-based predictor using the RNN-T loss yields some but limited improvements over a smaller pre-trained LM predictor. Therefore, this paper proposes a weak-to-strong LM swap strategy, using a weak LM predictor during RNN-T loss training and then replacing it with a strong LLM. After LM replacement, the minimum word error rate (MWER) loss is employed to finetune the integration of the LLM predictor with the Transducer-Llama model. Experiments on the LibriSpeech and large-scale multi-lingual LibriSpeech corpora show that the proposed streaming Transducer-Llama approach gave a 17% relative WER reduction (WERR) over a strong FT baseline and a 32% WERR over an RNN-T baseline.
Effective Text Adaptation for LLM-based ASR through Soft Prompt Fine-Tuning
Dec 09, 2024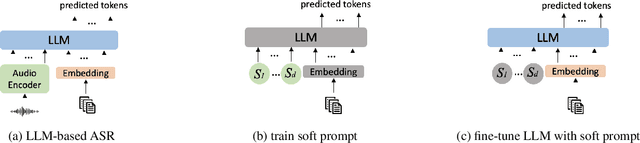
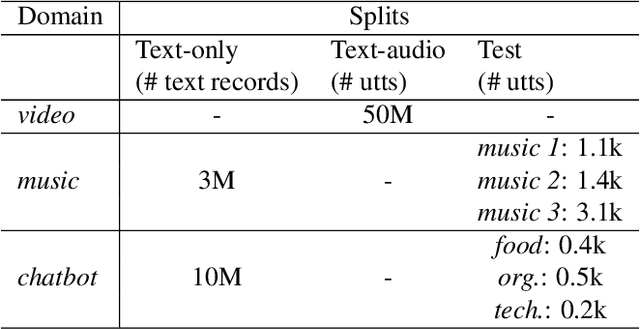
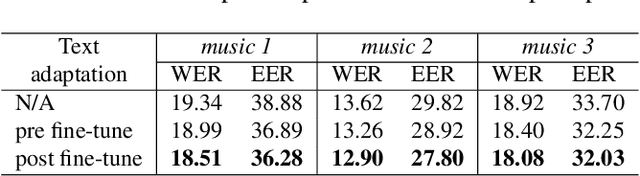
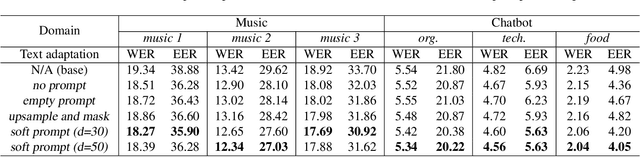
The advent of Large Language Models (LLM) has reformed the Automatic Speech Recognition (ASR). Prompting LLM with audio embeddings to generate transcriptions becomes the new state-of-the-art ASR. Despite LLMs being trained with an extensive amount of text corpora, high-quality domain-specific text data can still significantly enhance ASR performance on domain adaptation tasks. Although LLM-based ASR can naturally incorporate more text corpora by fine-tuning the LLM decoder, fine-tuning such ASR on text-only data without paired prompts may diminish the effectiveness of domain-specific knowledge. To mitigate this issue, we propose a two-step soft prompt fine-tuning strategy that enhances domain-specific text adaptation. Experimental results show that text adaptation with our proposed method achieved a relative up to 9% Word Error Rate (WER) reduction and up to 18% Entity Error Rate (EER) reduction on the target domain compared to the baseline ASR. Combining this with domain-specific Language Model (LM) fusion can further improve the EER by a relative 2-5%
Effective internal language model training and fusion for factorized transducer model
Apr 02, 2024


The internal language model (ILM) of the neural transducer has been widely studied. In most prior work, it is mainly used for estimating the ILM score and is subsequently subtracted during inference to facilitate improved integration with external language models. Recently, various of factorized transducer models have been proposed, which explicitly embrace a standalone internal language model for non-blank token prediction. However, even with the adoption of factorized transducer models, limited improvement has been observed compared to shallow fusion. In this paper, we propose a novel ILM training and decoding strategy for factorized transducer models, which effectively combines the blank, acoustic and ILM scores. Our experiments show a 17% relative improvement over the standard decoding method when utilizing a well-trained ILM and the proposed decoding strategy on LibriSpeech datasets. Furthermore, when compared to a strong RNN-T baseline enhanced with external LM fusion, the proposed model yields a 5.5% relative improvement on general-sets and an 8.9% WER reduction for rare words. The proposed model can achieve superior performance without relying on external language models, rendering it highly efficient for production use-cases. To further improve the performance, we propose a novel and memory-efficient ILM-fusion-aware minimum word error rate (MWER) training method which improves ILM integration significantly.
Correction Focused Language Model Training for Speech Recognition
Oct 17, 2023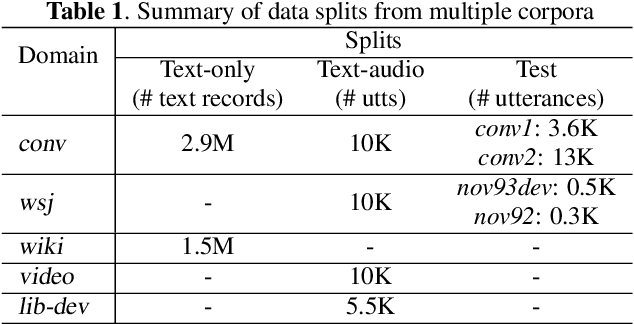

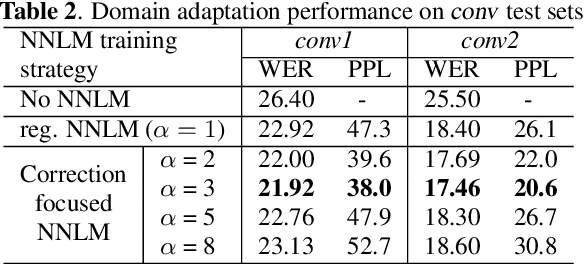
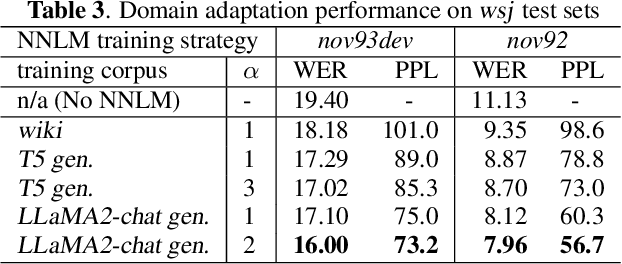
Language models (LMs) have been commonly adopted to boost the performance of automatic speech recognition (ASR) particularly in domain adaptation tasks. Conventional way of LM training treats all the words in corpora equally, resulting in suboptimal improvements in ASR performance. In this work, we introduce a novel correction focused LM training approach which aims to prioritize ASR fallible words. The word-level ASR fallibility score, representing the likelihood of ASR mis-recognition, is defined and shaped as a prior word distribution to guide the LM training. To enable correction focused training with text-only corpora, large language models (LLMs) are employed as fallibility score predictors and text generators through multi-task fine-tuning. Experimental results for domain adaptation tasks demonstrate the effectiveness of our proposed method. Compared with conventional LMs, correction focused training achieves up to relatively 5.5% word error rate (WER) reduction in sufficient text scenarios. In insufficient text scenarios, LM training with LLM-generated text achieves up to relatively 13% WER reduction, while correction focused training further obtains up to relatively 6% WER reduction.
Recovering from Privacy-Preserving Masking with Large Language Models
Sep 23, 2023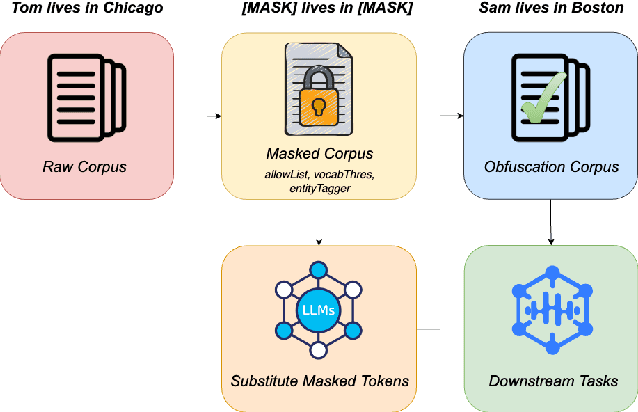
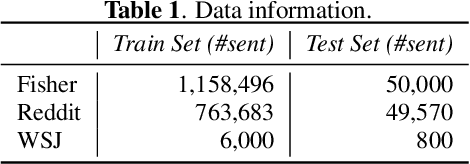
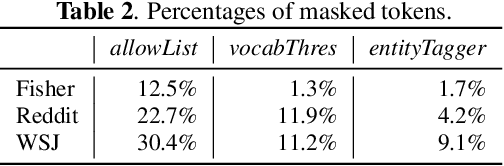
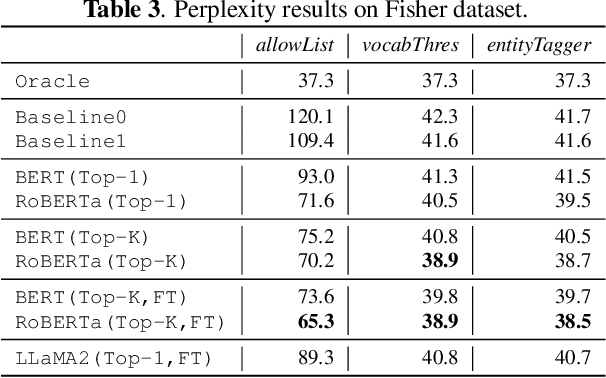
Model adaptation is crucial to handle the discrepancy between proxy training data and actual users data received. To effectively perform adaptation, textual data of users is typically stored on servers or their local devices, where downstream natural language processing (NLP) models can be directly trained using such in-domain data. However, this might raise privacy and security concerns due to the extra risks of exposing user information to adversaries. Replacing identifying information in textual data with a generic marker has been recently explored. In this work, we leverage large language models (LLMs) to suggest substitutes of masked tokens and have their effectiveness evaluated on downstream language modeling tasks. Specifically, we propose multiple pre-trained and fine-tuned LLM-based approaches and perform empirical studies on various datasets for the comparison of these methods. Experimental results show that models trained on the obfuscation corpora are able to achieve comparable performance with the ones trained on the original data without privacy-preserving token masking.
Contextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023



This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Adaptive Multi-Corpora Language Model Training for Speech Recognition
Nov 09, 2022Neural network language model (NNLM) plays an essential role in automatic speech recognition (ASR) systems, especially in adaptation tasks when text-only data is available. In practice, an NNLM is typically trained on a combination of data sampled from multiple corpora. Thus, the data sampling strategy is important to the adaptation performance. Most existing works focus on designing static sampling strategies. However, each corpus may show varying impacts at different NNLM training stages. In this paper, we introduce a novel adaptive multi-corpora training algorithm that dynamically learns and adjusts the sampling probability of each corpus along the training process. The algorithm is robust to corpora sizes and domain relevance. Compared with static sampling strategy baselines, the proposed approach yields remarkable improvement by achieving up to relative 7% and 9% word error rate (WER) reductions on in-domain and out-of-domain adaptation tasks, respectively.