 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovable Antenna-Enabled Integrated Sensing and Communication in Low-Altitude UAV Networks
May 18, 2026This paper investigates a multiple unmanned aerial vehicle (UAV)-assisted integrated sensing and communication (ISAC) system equipped with movable antenna (MA) arrays. To align with practical scenarios, we simulate the dynamic roaming of ground users and the three-dimensional deployment of UAVs in the airspace. We aim to maximize the total data rate by jointly optimizing key operational variables, including UAV trajectories, user association, antenna positions, and beamforming. This formulated problem is subject to constraints on transmission power and the sensing signal-to-noise ratio. To address the challenge of dynamically unknown state transitions due to user mobility, the original problem is decomposed into two steps and solved using different algorithms. First, we utilize the hierarchical density-based spatial clustering of applications with noise (HDBSCAN) algorithm to address the ground-to-air association problem, periodically updating clusters and re-associating during training. The clustering hotspots are used to suggest flight directions for the UAVs. Second, we develop the soft actor-critic algorithm to solve the joint optimization problem of UAV trajectories, antenna positions, and beamforming. Experimental results demonstrate that UAVs equipped with MA arrays outperform those with traditional fixed antenna arrays in ISAC systems, and the proposed optimization strategy effectively enhances communication rates while ensuring sensing performance.
VowelPrompt: Hearing Speech Emotions from Text via Vowel-level Prosodic Augmentation
Feb 06, 2026Emotion recognition in speech presents a complex multimodal challenge, requiring comprehension of both linguistic content and vocal expressivity, particularly prosodic features such as fundamental frequency, intensity, and temporal dynamics. Although large language models (LLMs) have shown promise in reasoning over textual transcriptions for emotion recognition, they typically neglect fine-grained prosodic information, limiting their effectiveness and interpretability. In this work, we propose VowelPrompt, a linguistically grounded framework that augments LLM-based emotion recognition with interpretable, fine-grained vowel-level prosodic cues. Drawing on phonetic evidence that vowels serve as primary carriers of affective prosody, VowelPrompt extracts pitch-, energy-, and duration-based descriptors from time-aligned vowel segments, and converts these features into natural language descriptions for better interpretability. Such a design enables LLMs to jointly reason over lexical semantics and fine-grained prosodic variation. Moreover, we adopt a two-stage adaptation procedure comprising supervised fine-tuning (SFT) followed by Reinforcement Learning with Verifiable Reward (RLVR), implemented via Group Relative Policy Optimization (GRPO), to enhance reasoning capability, enforce structured output adherence, and improve generalization across domains and speaker variations. Extensive evaluations across diverse benchmark datasets demonstrate that VowelPrompt consistently outperforms state-of-the-art emotion recognition methods under zero-shot, fine-tuned, cross-domain, and cross-linguistic conditions, while enabling the generation of interpretable explanations that are jointly grounded in contextual semantics and fine-grained prosodic structure.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
LLaMA based Punctuation Restoration With Forward Pass Only Decoding
Aug 09, 2024



This paper introduces two advancements in the field of Large Language Model Annotation with a focus on punctuation restoration tasks. Our first contribution is the application of LLaMA for punctuation restoration, which demonstrates superior performance compared to the established benchmark. Despite its impressive quality, LLaMA faces challenges regarding inference speed and hallucinations. To address this, our second contribution presents Forward Pass Only Decoding (FPOD), a novel decoding approach for annotation tasks. This innovative method results in a substantial 19.8x improvement in inference speed, effectively addressing a critical bottleneck and enhancing the practical utility of LLaMA for large-scale data annotation tasks without hallucinations. The combination of these contributions not only solidifies LLaMA as a powerful tool for punctuation restoration but also highlights FPOD as a crucial strategy for overcoming speed constraints.
Towards scalable efficient on-device ASR with transfer learning
Jul 23, 2024



Multilingual pretraining for transfer learning significantly boosts the robustness of low-resource monolingual ASR models. This study systematically investigates three main aspects: (a) the impact of transfer learning on model performance during initial training or fine-tuning, (b) the influence of transfer learning across dataset domains and languages, and (c) the effect on rare-word recognition compared to non-rare words. Our finding suggests that RNNT-loss pretraining, followed by monolingual fine-tuning with Minimum Word Error Rate (MinWER) loss, consistently reduces Word Error Rates (WER) across languages like Italian and French. WER Reductions (WERR) reach 36.2% and 42.8% compared to monolingual baselines for MLS and in-house datasets. Out-of-domain pretraining leads to 28% higher WERR than in-domain pretraining. Both rare and non-rare words benefit, with rare words showing greater improvements with out-of-domain pretraining, and non-rare words with in-domain pretraining.
SignDiff: Learning Diffusion Models for American Sign Language Production
Aug 30, 2023



The field of Sign Language Production (SLP) lacked a large-scale, pre-trained model based on deep learning for continuous American Sign Language (ASL) production in the past decade. This limitation hampers communication for all individuals with disabilities relying on ASL. To address this issue, we undertook the secondary development and utilization of How2Sign, one of the largest publicly available ASL datasets. Despite its significance, prior researchers in the field of sign language have not effectively employed this corpus due to the intricacies involved in American Sign Language Production (ASLP). To conduct large-scale ASLP, we propose SignDiff based on the latest work in related fields, which is a dual-condition diffusion pre-training model that can generate human sign language speakers from a skeleton pose. SignDiff has a novel Frame Reinforcement Network called FR-Net, similar to dense human pose estimation work, which enhances the correspondence between text lexical symbols and sign language dense pose frames reduce the occurrence of multiple fingers in the diffusion model. In addition, our ASLP method proposes two new improved modules and a new loss function to improve the accuracy and quality of sign language skeletal posture and enhance the ability of the model to train on large-scale data. We propose the first baseline for ASL production and report the scores of 17.19 and 12.85 on BLEU-4 on the How2Sign dev/test sets. We also evaluated our model on the previous mainstream dataset called PHOENIX14T, and the main experiments achieved the results of SOTA. In addition, our image quality far exceeds all previous results by 10 percentage points on the SSIM indicator. Finally, we conducted ablation studies and qualitative evaluations for discussion.
Language Agnostic Data-Driven Inverse Text Normalization
Jan 24, 2023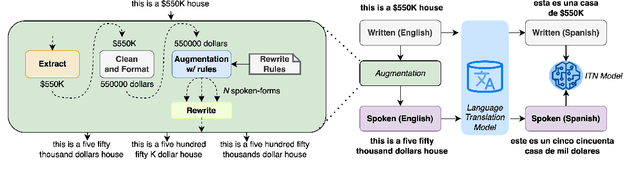
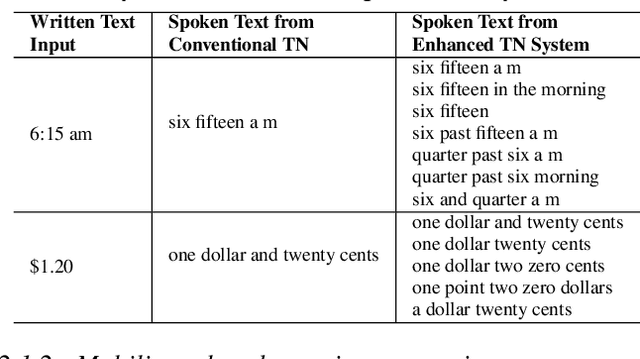
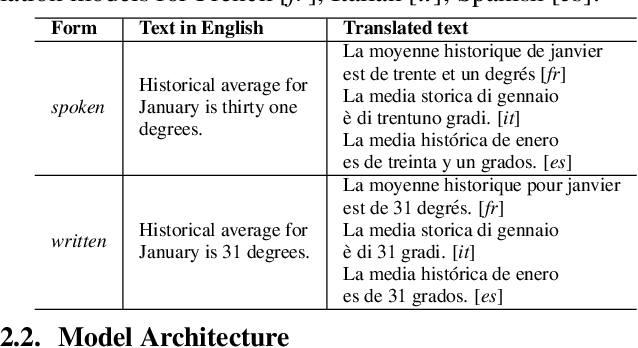
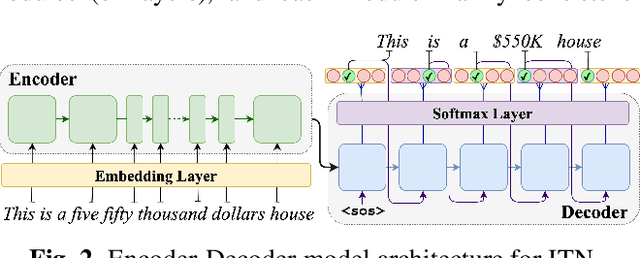
With the emergence of automatic speech recognition (ASR) models, converting the spoken form text (from ASR) to the written form is in urgent need. This inverse text normalization (ITN) problem attracts the attention of researchers from various fields. Recently, several works show that data-driven ITN methods can output high-quality written form text. Due to the scarcity of labeled spoken-written datasets, the studies on non-English data-driven ITN are quite limited. In this work, we propose a language-agnostic data-driven ITN framework to fill this gap. Specifically, we leverage the data augmentation in conjunction with neural machine translated data for low resource languages. Moreover, we design an evaluation method for language agnostic ITN model when only English data is available. Our empirical evaluation shows this language agnostic modeling approach is effective for low resource languages while preserving the performance for high resource languages.
Adaptive Multi-Corpora Language Model Training for Speech Recognition
Nov 09, 2022Neural network language model (NNLM) plays an essential role in automatic speech recognition (ASR) systems, especially in adaptation tasks when text-only data is available. In practice, an NNLM is typically trained on a combination of data sampled from multiple corpora. Thus, the data sampling strategy is important to the adaptation performance. Most existing works focus on designing static sampling strategies. However, each corpus may show varying impacts at different NNLM training stages. In this paper, we introduce a novel adaptive multi-corpora training algorithm that dynamically learns and adjusts the sampling probability of each corpus along the training process. The algorithm is robust to corpora sizes and domain relevance. Compared with static sampling strategy baselines, the proposed approach yields remarkable improvement by achieving up to relative 7% and 9% word error rate (WER) reductions on in-domain and out-of-domain adaptation tasks, respectively.
Mitigating Unintended Memorization in Language Models via Alternating Teaching
Oct 13, 2022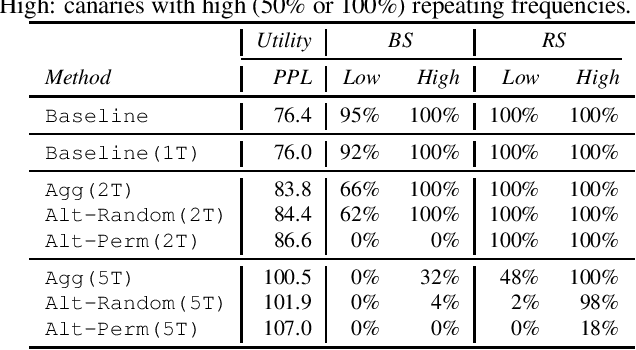
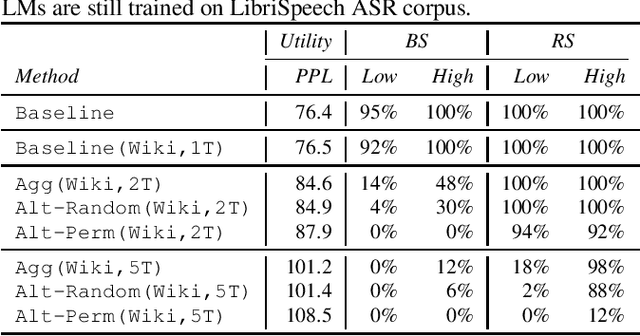
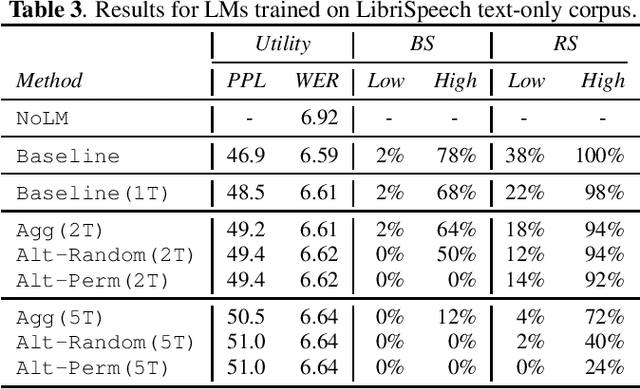
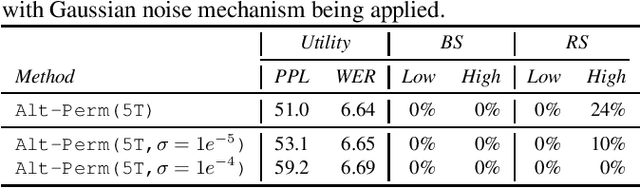
Recent research has shown that language models have a tendency to memorize rare or unique sequences in the training corpora which can thus leak sensitive attributes of user data. We employ a teacher-student framework and propose a novel approach called alternating teaching to mitigate unintended memorization in sequential modeling. In our method, multiple teachers are trained on disjoint training sets whose privacy one wishes to protect, and teachers' predictions supervise the training of a student model in an alternating manner at each time step. Experiments on LibriSpeech datasets show that the proposed method achieves superior privacy-preserving results than other counterparts. In comparison with no prevention for unintended memorization, the overall utility loss is small when training records are sufficient.
Improving Data Driven Inverse Text Normalization using Data Augmentation
Jul 20, 2022
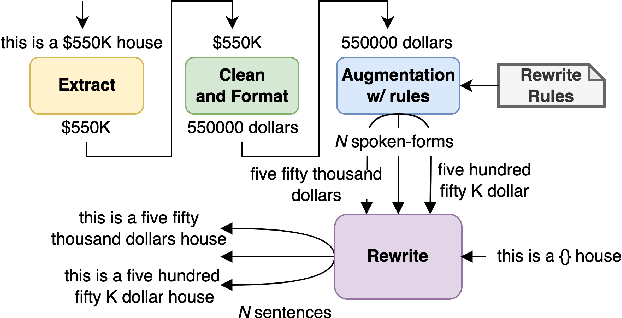

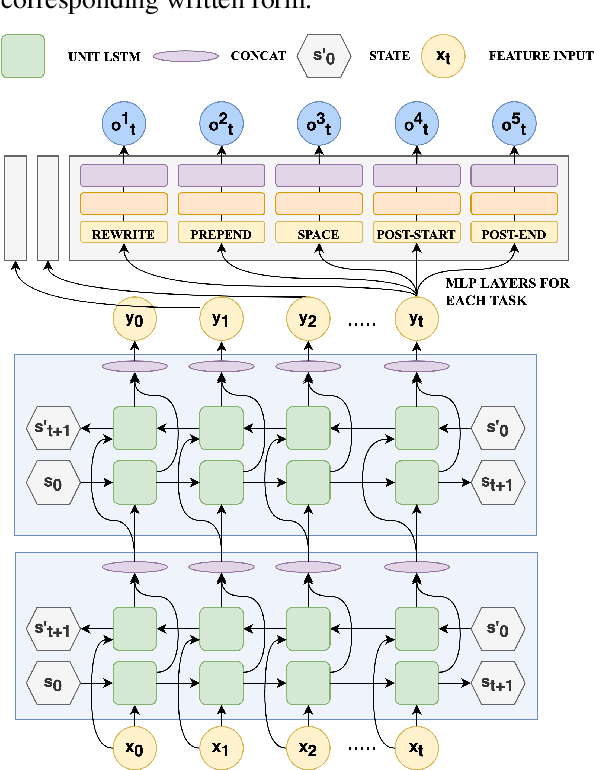
Inverse text normalization (ITN) is used to convert the spoken form output of an automatic speech recognition (ASR) system to a written form. Traditional handcrafted ITN rules can be complex to transcribe and maintain. Meanwhile neural modeling approaches require quality large-scale spoken-written pair examples in the same or similar domain as the ASR system (in-domain data), to train. Both these approaches require costly and complex annotations. In this paper, we present a data augmentation technique that effectively generates rich spoken-written numeric pairs from out-of-domain textual data with minimal human annotation. We empirically demonstrate that ITN model trained using our data augmentation technique consistently outperform ITN model trained using only in-domain data across all numeric surfaces like cardinal, currency, and fraction, by an overall accuracy of 14.44%.