 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaMA based Punctuation Restoration With Forward Pass Only Decoding
Aug 09, 2024



This paper introduces two advancements in the field of Large Language Model Annotation with a focus on punctuation restoration tasks. Our first contribution is the application of LLaMA for punctuation restoration, which demonstrates superior performance compared to the established benchmark. Despite its impressive quality, LLaMA faces challenges regarding inference speed and hallucinations. To address this, our second contribution presents Forward Pass Only Decoding (FPOD), a novel decoding approach for annotation tasks. This innovative method results in a substantial 19.8x improvement in inference speed, effectively addressing a critical bottleneck and enhancing the practical utility of LLaMA for large-scale data annotation tasks without hallucinations. The combination of these contributions not only solidifies LLaMA as a powerful tool for punctuation restoration but also highlights FPOD as a crucial strategy for overcoming speed constraints.
RACER: An LLM-powered Methodology for Scalable Analysis of Semi-structured Mental Health Interviews
Feb 05, 2024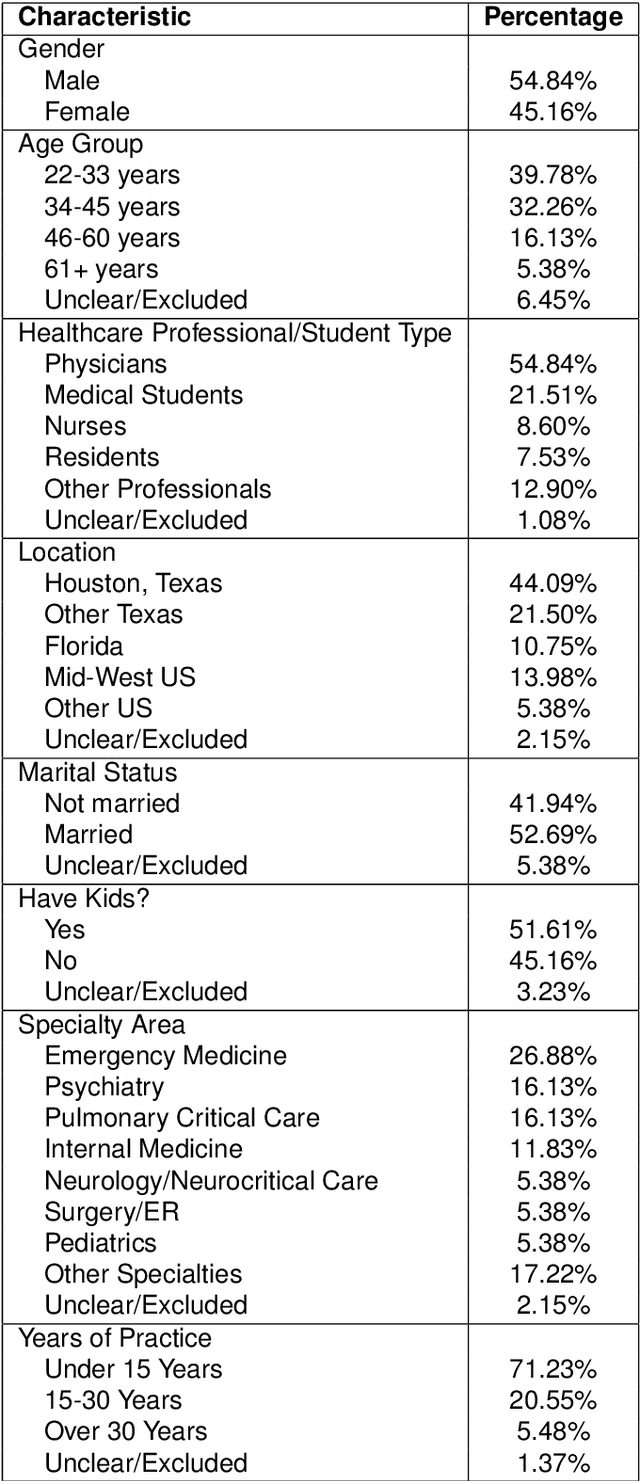
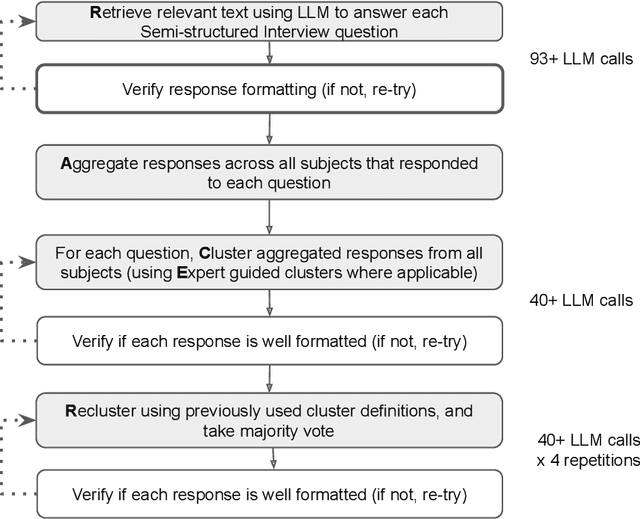

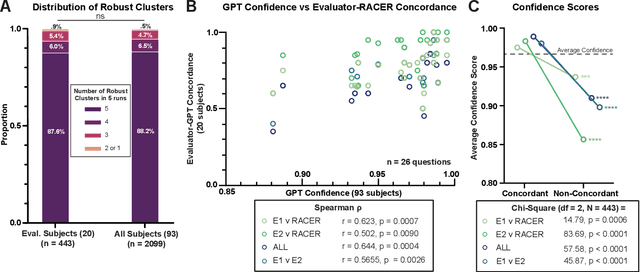
Semi-structured interviews (SSIs) are a commonly employed data-collection method in healthcare research, offering in-depth qualitative insights into subject experiences. Despite their value, the manual analysis of SSIs is notoriously time-consuming and labor-intensive, in part due to the difficulty of extracting and categorizing emotional responses, and challenges in scaling human evaluation for large populations. In this study, we develop RACER, a Large Language Model (LLM) based expert-guided automated pipeline that efficiently converts raw interview transcripts into insightful domain-relevant themes and sub-themes. We used RACER to analyze SSIs conducted with 93 healthcare professionals and trainees to assess the broad personal and professional mental health impacts of the COVID-19 crisis. RACER achieves moderately high agreement with two human evaluators (72%), which approaches the human inter-rater agreement (77%). Interestingly, LLMs and humans struggle with similar content involving nuanced emotional, ambivalent/dialectical, and psychological statements. Our study highlights the opportunities and challenges in using LLMs to improve research efficiency and opens new avenues for scalable analysis of SSIs in healthcare research.
Treatment Effect Estimation with Unobserved and Heterogeneous Confounding Variables
Jul 29, 2022
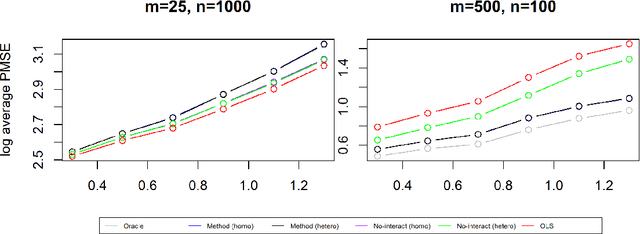


The estimation of the treatment effect is often biased in the presence of unobserved confounding variables which are commonly referred to as hidden variables. Although a few methods have been recently proposed to handle the effect of hidden variables, these methods often overlook the possibility of any interaction between the observed treatment variable and the unobserved covariates. In this work, we address this shortcoming by studying a multivariate response regression problem with both unobserved and heterogeneous confounding variables of the form $Y=A^T X+ B^T Z+ \sum_{j=1}^{p} C^T_j X_j Z + E$, where $Y \in \mathbb{R}^m$ are $m$-dimensional response variables, $X \in \mathbb{R}^p$ are observed covariates (including the treatment variable), $Z \in \mathbb{R}^K$ are $K$-dimensional unobserved confounders, and $E \in \mathbb{R}^m$ is the random noise. Allowing for the interaction between $X_j$ and $Z$ induces the heterogeneous confounding effect. Our goal is to estimate the unknown matrix $A$, the direct effect of the observed covariates or the treatment on the responses. To this end, we propose a new debiased estimation approach via SVD to remove the effect of unobserved confounding variables. The rate of convergence of the estimator is established under both the homoscedastic and heteroscedastic noises. We also present several simulation experiments and a real-world data application to substantiate our findings.
Deep learning long-range information in undirected graphs with wave networks
Oct 29, 2018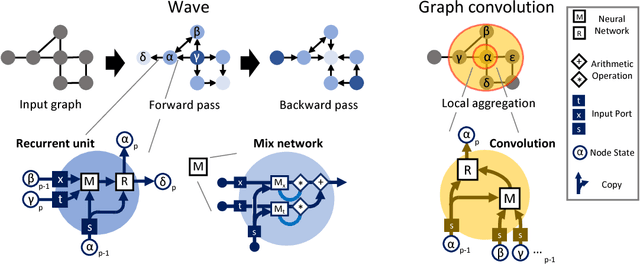
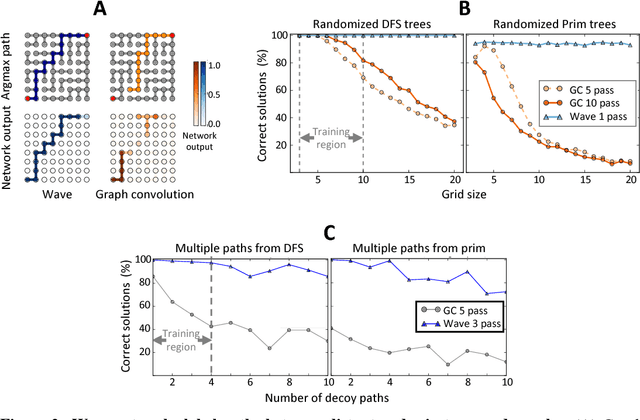
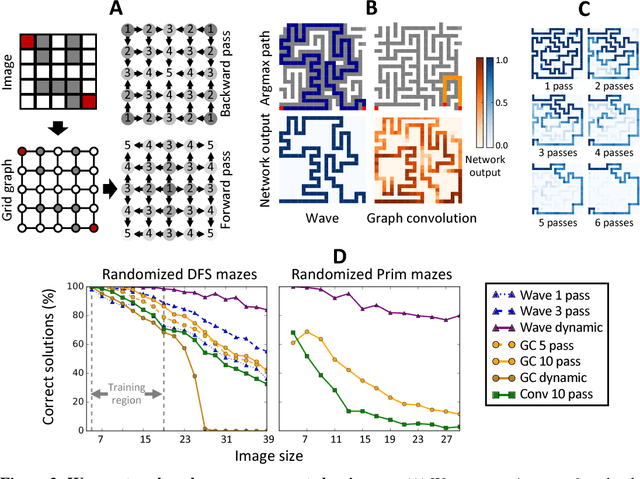
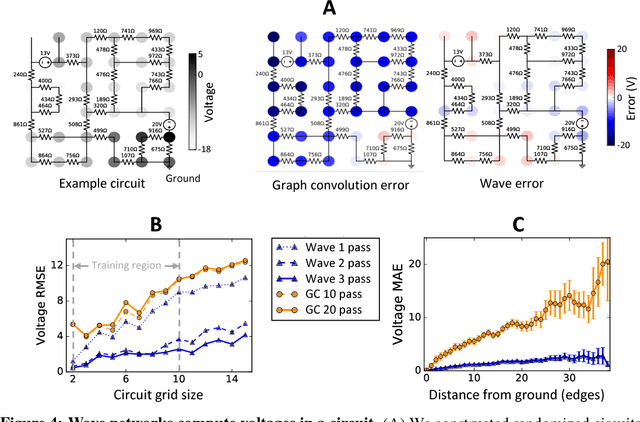
Graph algorithms are key tools in many fields of science and technology. Some of these algorithms depend on propagating information between distant nodes in a graph. Recently, there have been a number of deep learning architectures proposed to learn on undirected graphs. However, most of these architectures aggregate information in the local neighborhood of a node, and therefore they may not be capable of efficiently propagating long-range information. To solve this problem we examine a recently proposed architecture, wave, which propagates information back and forth across an undirected graph in waves of nonlinear computation. We compare wave to graph convolution, an architecture based on local aggregation, and find that wave learns three different graph-based tasks with greater efficiency and accuracy. These three tasks include (1) labeling a path connecting two nodes in a graph, (2) solving a maze presented as an image, and (3) computing voltages in a circuit. These tasks range from trivial to very difficult, but wave can extrapolate from small training examples to much larger testing examples. These results show that wave may be able to efficiently solve a wide range of problems that require long-range information propagation across undirected graphs. An implementation of the wave network, and example code for the maze problem are included in the tflon deep learning toolkit (https://bitbucket.org/mkmatlock/tflon).