 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-Guided Diffusion for Interactive Scene Generation
Dec 11, 2025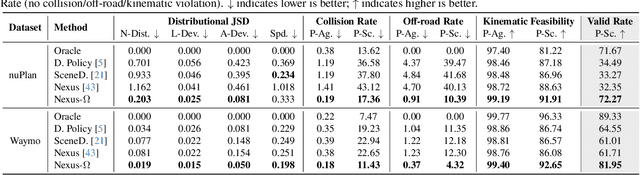
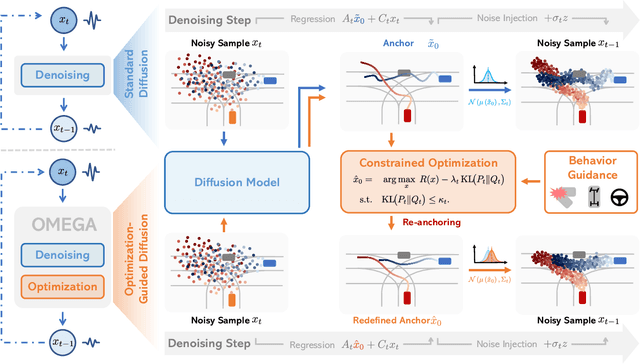
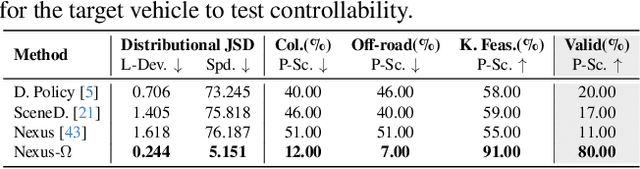
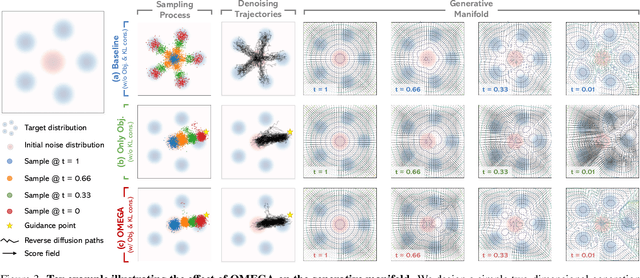
Realistic and diverse multi-agent driving scenes are crucial for evaluating autonomous vehicles, but safety-critical events which are essential for this task are rare and underrepresented in driving datasets. Data-driven scene generation offers a low-cost alternative by synthesizing complex traffic behaviors from existing driving logs. However, existing models often lack controllability or yield samples that violate physical or social constraints, limiting their usability. We present OMEGA, an optimization-guided, training-free framework that enforces structural consistency and interaction awareness during diffusion-based sampling from a scene generation model. OMEGA re-anchors each reverse diffusion step via constrained optimization, steering the generation towards physically plausible and behaviorally coherent trajectories. Building on this framework, we formulate ego-attacker interactions as a game-theoretic optimization in the distribution space, approximating Nash equilibria to generate realistic, safety-critical adversarial scenarios. Experiments on nuPlan and Waymo show that OMEGA improves generation realism, consistency, and controllability, increasing the ratio of physically and behaviorally valid scenes from 32.35% to 72.27% for free exploration capabilities, and from 11% to 80% for controllability-focused generation. Our approach can also generate $5\times$ more near-collision frames with a time-to-collision under three seconds while maintaining the overall scene realism.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025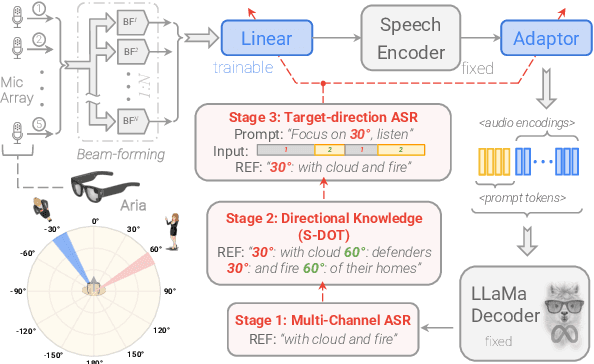
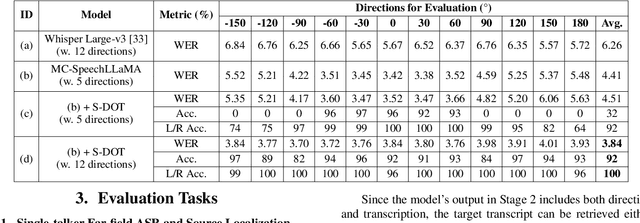
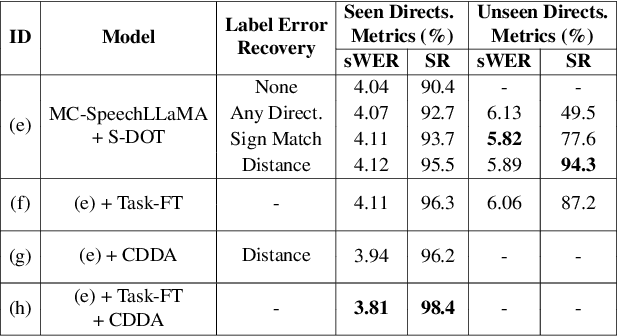
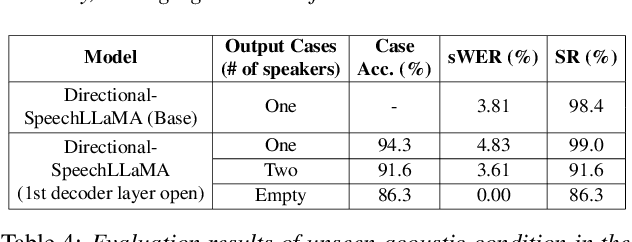
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
MTGS: Multi-Traversal Gaussian Splatting
Mar 16, 2025

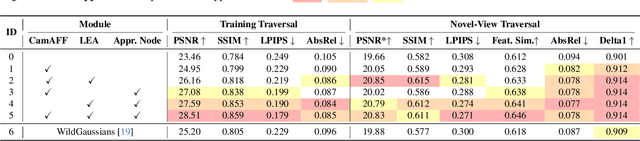

Multi-traversal data, commonly collected through daily commutes or by self-driving fleets, provides multiple viewpoints for scene reconstruction within a road block. This data offers significant potential for high-quality novel view synthesis, which is crucial for applications such as autonomous vehicle simulators. However, inherent challenges in multi-traversal data often result in suboptimal reconstruction quality, including variations in appearance and the presence of dynamic objects. To address these issues, we propose Multi-Traversal Gaussian Splatting (MTGS), a novel approach that reconstructs high-quality driving scenes from arbitrarily collected multi-traversal data by modeling a shared static geometry while separately handling dynamic elements and appearance variations. Our method employs a multi-traversal dynamic scene graph with a shared static node and traversal-specific dynamic nodes, complemented by color correction nodes with learnable spherical harmonics coefficient residuals. This approach enables high-fidelity novel view synthesis and provides flexibility to navigate any viewpoint. We conduct extensive experiments on a large-scale driving dataset, nuPlan, with multi-traversal data. Our results demonstrate that MTGS improves LPIPS by 23.5% and geometry accuracy by 46.3% compared to single-traversal baselines. The code and data would be available to the public.
Multi-view Granular-ball Contrastive Clustering
Dec 19, 2024



Previous multi-view contrastive learning methods typically operate at two scales: instance-level and cluster-level. Instance-level approaches construct positive and negative pairs based on sample correspondences, aiming to bring positive pairs closer and push negative pairs further apart in the latent space. Cluster-level methods focus on calculating cluster assignments for samples under each view and maximize view consensus by reducing distribution discrepancies, e.g., minimizing KL divergence or maximizing mutual information. However, these two types of methods either introduce false negatives, leading to reduced model discriminability, or overlook local structures and cannot measure relationships between clusters across views explicitly. To this end, we propose a method named Multi-view Granular-ball Contrastive Clustering (MGBCC). MGBCC segments the sample set into coarse-grained granular balls, and establishes associations between intra-view and cross-view granular balls. These associations are reinforced in a shared latent space, thereby achieving multi-granularity contrastive learning. Granular balls lie between instances and clusters, naturally preserving the local topological structure of the sample set. We conduct extensive experiments to validate the effectiveness of the proposed method.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Recovering from Privacy-Preserving Masking with Large Language Models
Sep 23, 2023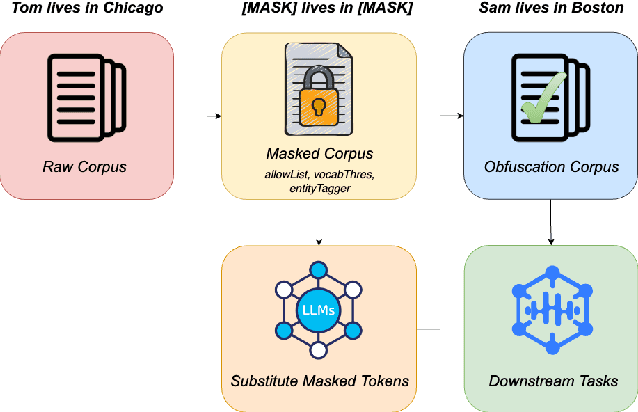
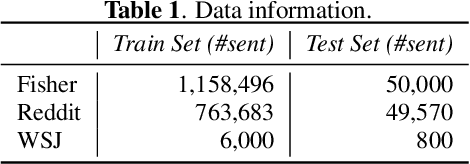
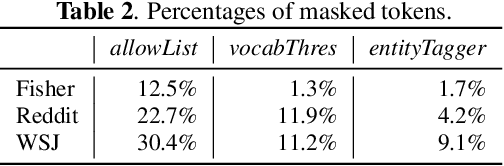
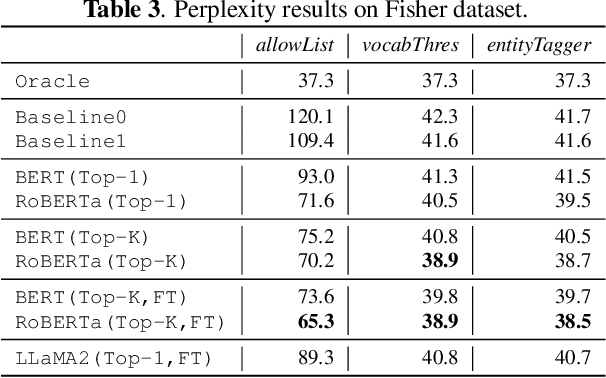
Model adaptation is crucial to handle the discrepancy between proxy training data and actual users data received. To effectively perform adaptation, textual data of users is typically stored on servers or their local devices, where downstream natural language processing (NLP) models can be directly trained using such in-domain data. However, this might raise privacy and security concerns due to the extra risks of exposing user information to adversaries. Replacing identifying information in textual data with a generic marker has been recently explored. In this work, we leverage large language models (LLMs) to suggest substitutes of masked tokens and have their effectiveness evaluated on downstream language modeling tasks. Specifically, we propose multiple pre-trained and fine-tuned LLM-based approaches and perform empirical studies on various datasets for the comparison of these methods. Experimental results show that models trained on the obfuscation corpora are able to achieve comparable performance with the ones trained on the original data without privacy-preserving token masking.
Language Agnostic Data-Driven Inverse Text Normalization
Jan 24, 2023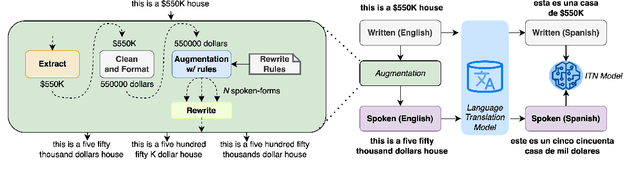
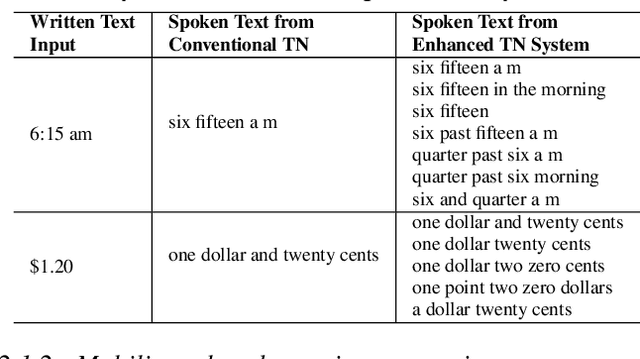
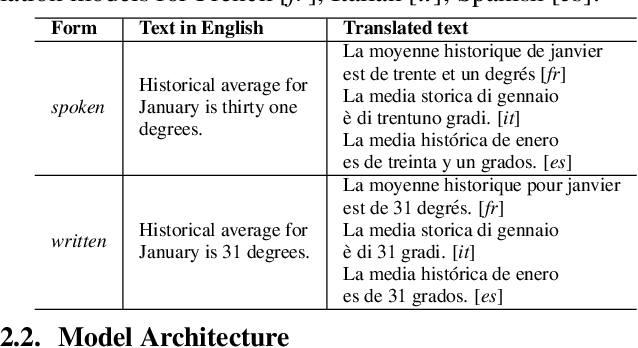
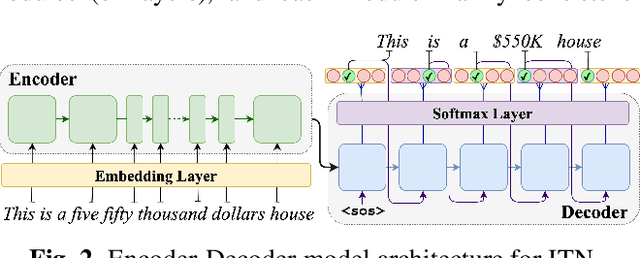
With the emergence of automatic speech recognition (ASR) models, converting the spoken form text (from ASR) to the written form is in urgent need. This inverse text normalization (ITN) problem attracts the attention of researchers from various fields. Recently, several works show that data-driven ITN methods can output high-quality written form text. Due to the scarcity of labeled spoken-written datasets, the studies on non-English data-driven ITN are quite limited. In this work, we propose a language-agnostic data-driven ITN framework to fill this gap. Specifically, we leverage the data augmentation in conjunction with neural machine translated data for low resource languages. Moreover, we design an evaluation method for language agnostic ITN model when only English data is available. Our empirical evaluation shows this language agnostic modeling approach is effective for low resource languages while preserving the performance for high resource languages.
Improving BERT Model Using Contrastive Learning for Biomedical Relation Extraction
Apr 28, 2021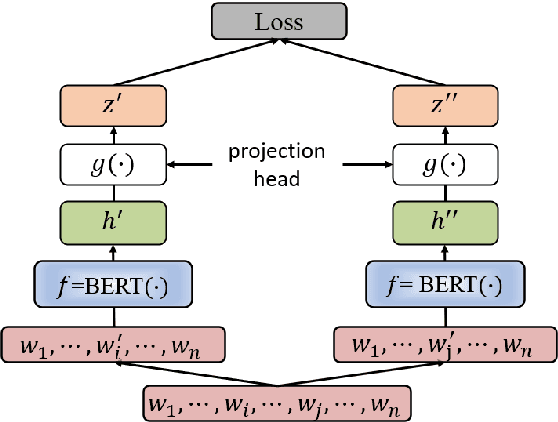

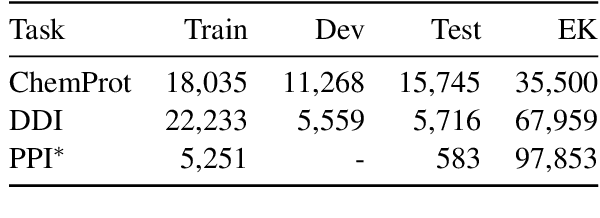
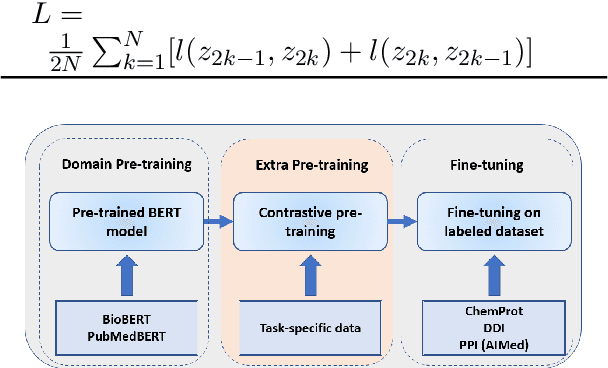
Contrastive learning has been used to learn a high-quality representation of the image in computer vision. However, contrastive learning is not widely utilized in natural language processing due to the lack of a general method of data augmentation for text data. In this work, we explore the method of employing contrastive learning to improve the text representation from the BERT model for relation extraction. The key knob of our framework is a unique contrastive pre-training step tailored for the relation extraction tasks by seamlessly integrating linguistic knowledge into the data augmentation. Furthermore, we investigate how large-scale data constructed from the external knowledge bases can enhance the generality of contrastive pre-training of BERT. The experimental results on three relation extraction benchmark datasets demonstrate that our method can improve the BERT model representation and achieve state-of-the-art performance. In addition, we explore the interpretability of models by showing that BERT with contrastive pre-training relies more on rationales for prediction. Our code and data are publicly available at: https://github.com/udel-biotm-lab/BERT-CLRE.
Gradient Regularized Contrastive Learning for Continual Domain Adaptation
Mar 23, 2021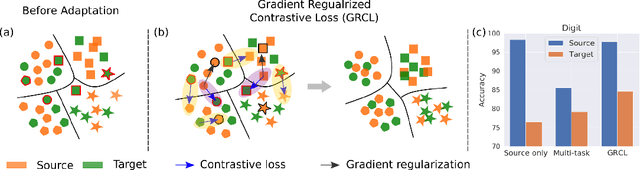
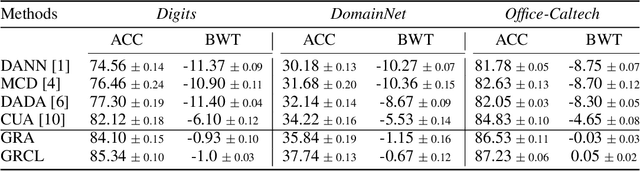
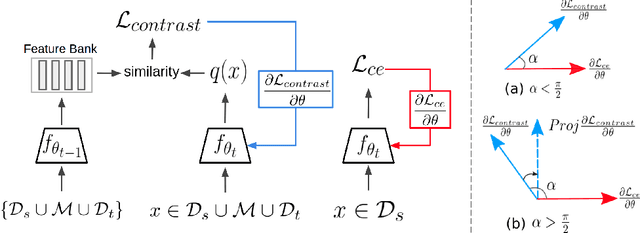

Human beings can quickly adapt to environmental changes by leveraging learning experience. However, adapting deep neural networks to dynamic environments by machine learning algorithms remains a challenge. To better understand this issue, we study the problem of continual domain adaptation, where the model is presented with a labelled source domain and a sequence of unlabelled target domains. The obstacles in this problem are both domain shift and catastrophic forgetting. We propose Gradient Regularized Contrastive Learning (GRCL) to solve the obstacles. At the core of our method, gradient regularization plays two key roles: (1) enforcing the gradient not to harm the discriminative ability of source features which can, in turn, benefit the adaptation ability of the model to target domains; (2) constraining the gradient not to increase the classification loss on old target domains, which enables the model to preserve the performance on old target domains when adapting to an in-coming target domain. Experiments on Digits, DomainNet and Office-Caltech benchmarks demonstrate the strong performance of our approach when compared to the other state-of-the-art methods.
Investigation of BERT Model on Biomedical Relation Extraction Based on Revised Fine-tuning Mechanism
Nov 01, 2020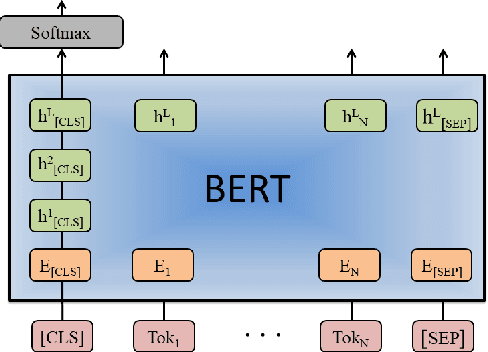
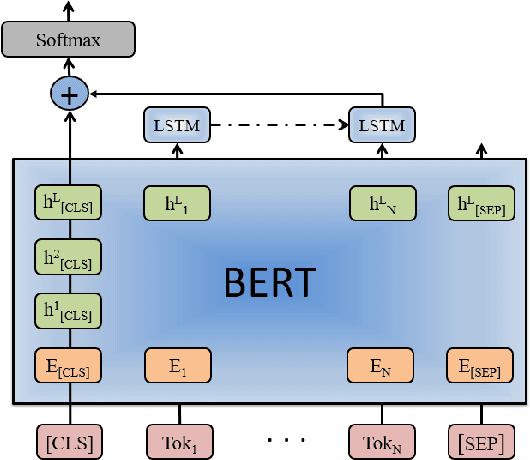
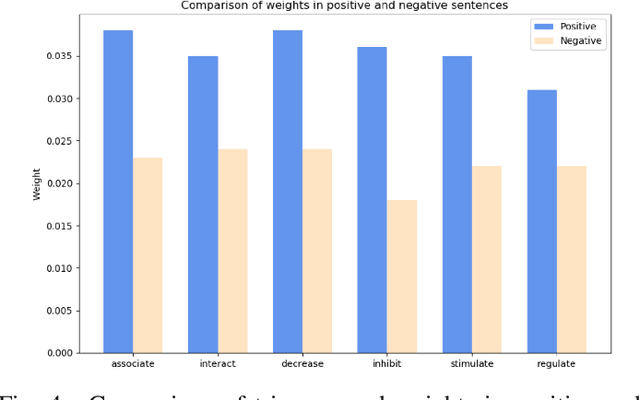
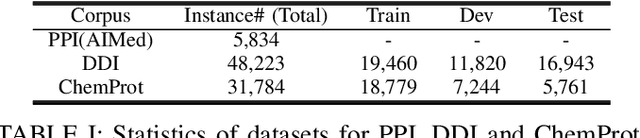
With the explosive growth of biomedical literature, designing automatic tools to extract information from the literature has great significance in biomedical research. Recently, transformer-based BERT models adapted to the biomedical domain have produced leading results. However, all the existing BERT models for relation classification only utilize partial knowledge from the last layer. In this paper, we will investigate the method of utilizing the entire layer in the fine-tuning process of BERT model. To the best of our knowledge, we are the first to explore this method. The experimental results illustrate that our method improves the BERT model performance and outperforms the state-of-the-art methods on three benchmark datasets for different relation extraction tasks. In addition, further analysis indicates that the key knowledge about the relations can be learned from the last layer of BERT model.