 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASP: Unifying Geometric and Semantic Self-Supervised Pre-training for Autonomous Driving
Mar 19, 2025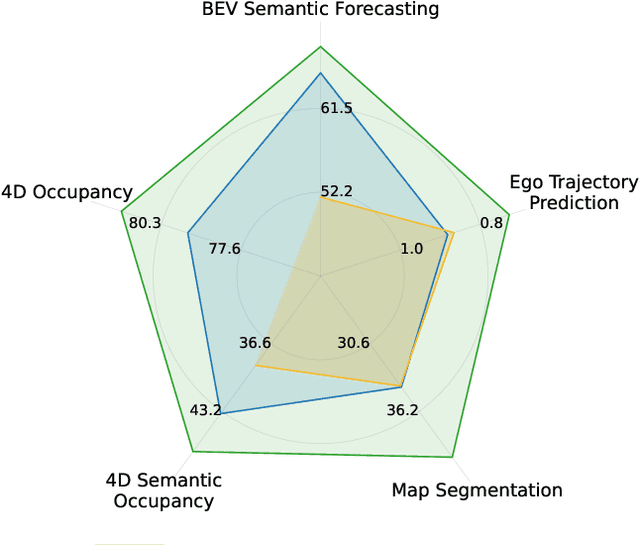
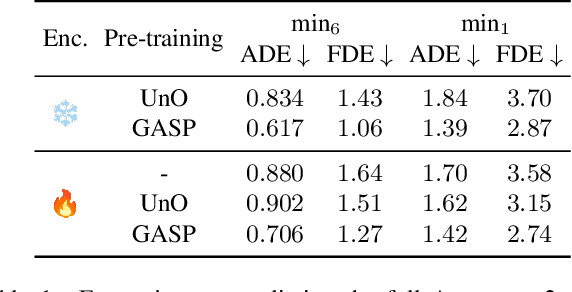
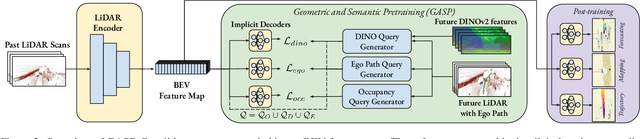
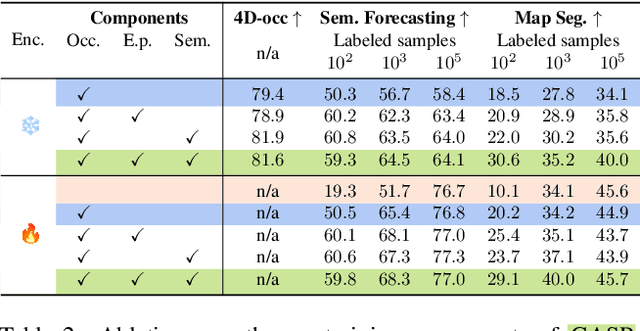
Self-supervised pre-training based on next-token prediction has enabled large language models to capture the underlying structure of text, and has led to unprecedented performance on a large array of tasks when applied at scale. Similarly, autonomous driving generates vast amounts of spatiotemporal data, alluding to the possibility of harnessing scale to learn the underlying geometric and semantic structure of the environment and its evolution over time. In this direction, we propose a geometric and semantic self-supervised pre-training method, GASP, that learns a unified representation by predicting, at any queried future point in spacetime, (1) general occupancy, capturing the evolving structure of the 3D scene; (2) ego occupancy, modeling the ego vehicle path through the environment; and (3) distilled high-level features from a vision foundation model. By modeling geometric and semantic 4D occupancy fields instead of raw sensor measurements, the model learns a structured, generalizable representation of the environment and its evolution through time. We validate GASP on multiple autonomous driving benchmarks, demonstrating significant improvements in semantic occupancy forecasting, online mapping, and ego trajectory prediction. Our results demonstrate that continuous 4D geometric and semantic occupancy prediction provides a scalable and effective pre-training paradigm for autonomous driving. For code and additional visualizations, see \href{https://research.zenseact.com/publications/gasp/.
MTGS: Multi-Traversal Gaussian Splatting
Mar 16, 2025

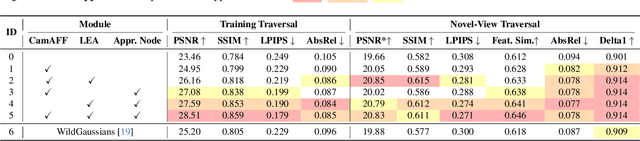

Multi-traversal data, commonly collected through daily commutes or by self-driving fleets, provides multiple viewpoints for scene reconstruction within a road block. This data offers significant potential for high-quality novel view synthesis, which is crucial for applications such as autonomous vehicle simulators. However, inherent challenges in multi-traversal data often result in suboptimal reconstruction quality, including variations in appearance and the presence of dynamic objects. To address these issues, we propose Multi-Traversal Gaussian Splatting (MTGS), a novel approach that reconstructs high-quality driving scenes from arbitrarily collected multi-traversal data by modeling a shared static geometry while separately handling dynamic elements and appearance variations. Our method employs a multi-traversal dynamic scene graph with a shared static node and traversal-specific dynamic nodes, complemented by color correction nodes with learnable spherical harmonics coefficient residuals. This approach enables high-fidelity novel view synthesis and provides flexibility to navigate any viewpoint. We conduct extensive experiments on a large-scale driving dataset, nuPlan, with multi-traversal data. Our results demonstrate that MTGS improves LPIPS by 23.5% and geometry accuracy by 46.3% compared to single-traversal baselines. The code and data would be available to the public.
SplatAD: Real-Time Lidar and Camera Rendering with 3D Gaussian Splatting for Autonomous Driving
Nov 25, 2024Ensuring the safety of autonomous robots, such as self-driving vehicles, requires extensive testing across diverse driving scenarios. Simulation is a key ingredient for conducting such testing in a cost-effective and scalable way. Neural rendering methods have gained popularity, as they can build simulation environments from collected logs in a data-driven manner. However, existing neural radiance field (NeRF) methods for sensor-realistic rendering of camera and lidar data suffer from low rendering speeds, limiting their applicability for large-scale testing. While 3D Gaussian Splatting (3DGS) enables real-time rendering, current methods are limited to camera data and are unable to render lidar data essential for autonomous driving. To address these limitations, we propose SplatAD, the first 3DGS-based method for realistic, real-time rendering of dynamic scenes for both camera and lidar data. SplatAD accurately models key sensor-specific phenomena such as rolling shutter effects, lidar intensity, and lidar ray dropouts, using purpose-built algorithms to optimize rendering efficiency. Evaluation across three autonomous driving datasets demonstrates that SplatAD achieves state-of-the-art rendering quality with up to +2 PSNR for NVS and +3 PSNR for reconstruction while increasing rendering speed over NeRF-based methods by an order of magnitude. See https://research.zenseact.com/publications/splatad/ for our project page.
Are NeRFs ready for autonomous driving? Towards closing the real-to-simulation gap
Mar 24, 2024Neural Radiance Fields (NeRFs) have emerged as promising tools for advancing autonomous driving (AD) research, offering scalable closed-loop simulation and data augmentation capabilities. However, to trust the results achieved in simulation, one needs to ensure that AD systems perceive real and rendered data in the same way. Although the performance of rendering methods is increasing, many scenarios will remain inherently challenging to reconstruct faithfully. To this end, we propose a novel perspective for addressing the real-to-simulated data gap. Rather than solely focusing on improving rendering fidelity, we explore simple yet effective methods to enhance perception model robustness to NeRF artifacts without compromising performance on real data. Moreover, we conduct the first large-scale investigation into the real-to-simulated data gap in an AD setting using a state-of-the-art neural rendering technique. Specifically, we evaluate object detectors and an online mapping model on real and simulated data, and study the effects of different pre-training strategies. Our results show notable improvements in model robustness to simulated data, even improving real-world performance in some cases. Last, we delve into the correlation between the real-to-simulated gap and image reconstruction metrics, identifying FID and LPIPS as strong indicators.
NeuRAD: Neural Rendering for Autonomous Driving
Dec 05, 2023



Neural radiance fields (NeRFs) have gained popularity in the autonomous driving (AD) community. Recent methods show NeRFs' potential for closed-loop simulation, enabling testing of AD systems, and as an advanced training data augmentation technique. However, existing methods often require long training times, dense semantic supervision, or lack generalizability. This, in turn, hinders the application of NeRFs for AD at scale. In this paper, we propose NeuRAD, a robust novel view synthesis method tailored to dynamic AD data. Our method features simple network design, extensive sensor modeling for both camera and lidar -- including rolling shutter, beam divergence and ray dropping -- and is applicable to multiple datasets out of the box. We verify its performance on five popular AD datasets, achieving state-of-the-art performance across the board. To encourage further development, we will openly release the NeuRAD source code. See https://github.com/georghess/NeuRAD .