 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3D2: Realistic 3D Asset Insertion via Diffusion for Autonomous Driving Simulation
Jun 09, 2025



Validating autonomous driving (AD) systems requires diverse and safety-critical testing, making photorealistic virtual environments essential. Traditional simulation platforms, while controllable, are resource-intensive to scale and often suffer from a domain gap with real-world data. In contrast, neural reconstruction methods like 3D Gaussian Splatting (3DGS) offer a scalable solution for creating photorealistic digital twins of real-world driving scenes. However, they struggle with dynamic object manipulation and reusability as their per-scene optimization-based methodology tends to result in incomplete object models with integrated illumination effects. This paper introduces R3D2, a lightweight, one-step diffusion model designed to overcome these limitations and enable realistic insertion of complete 3D assets into existing scenes by generating plausible rendering effects-such as shadows and consistent lighting-in real time. This is achieved by training R3D2 on a novel dataset: 3DGS object assets are generated from in-the-wild AD data using an image-conditioned 3D generative model, and then synthetically placed into neural rendering-based virtual environments, allowing R3D2 to learn realistic integration. Quantitative and qualitative evaluations demonstrate that R3D2 significantly enhances the realism of inserted assets, enabling use-cases like text-to-3D asset insertion and cross-scene/dataset object transfer, allowing for true scalability in AD validation. To promote further research in scalable and realistic AD simulation, we will release our dataset and code, see https://research.zenseact.com/publications/R3D2/.
Decoupled Diffusion Sparks Adaptive Scene Generation
Apr 14, 2025Controllable scene generation could reduce the cost of diverse data collection substantially for autonomous driving. Prior works formulate the traffic layout generation as predictive progress, either by denoising entire sequences at once or by iteratively predicting the next frame. However, full sequence denoising hinders online reaction, while the latter's short-sighted next-frame prediction lacks precise goal-state guidance. Further, the learned model struggles to generate complex or challenging scenarios due to a large number of safe and ordinal driving behaviors from open datasets. To overcome these, we introduce Nexus, a decoupled scene generation framework that improves reactivity and goal conditioning by simulating both ordinal and challenging scenarios from fine-grained tokens with independent noise states. At the core of the decoupled pipeline is the integration of a partial noise-masking training strategy and a noise-aware schedule that ensures timely environmental updates throughout the denoising process. To complement challenging scenario generation, we collect a dataset consisting of complex corner cases. It covers 540 hours of simulated data, including high-risk interactions such as cut-in, sudden braking, and collision. Nexus achieves superior generation realism while preserving reactivity and goal orientation, with a 40% reduction in displacement error. We further demonstrate that Nexus improves closed-loop planning by 20% through data augmentation and showcase its capability in safety-critical data generation.
GASP: Unifying Geometric and Semantic Self-Supervised Pre-training for Autonomous Driving
Mar 19, 2025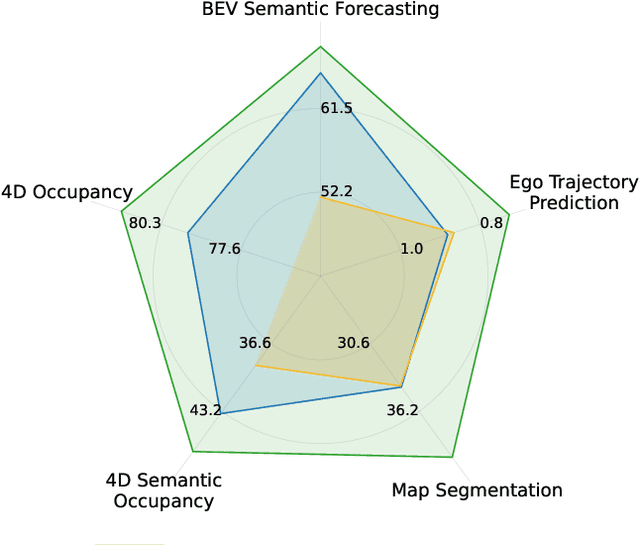
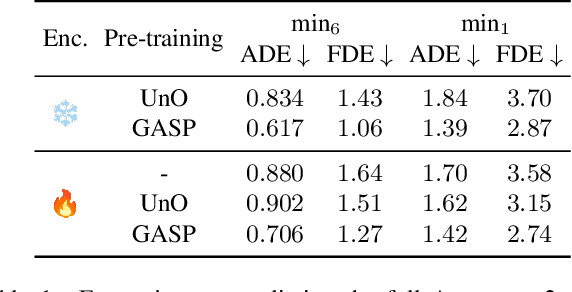
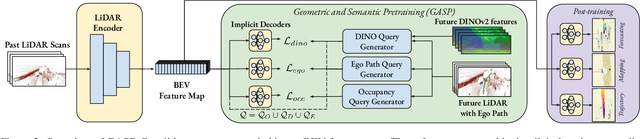
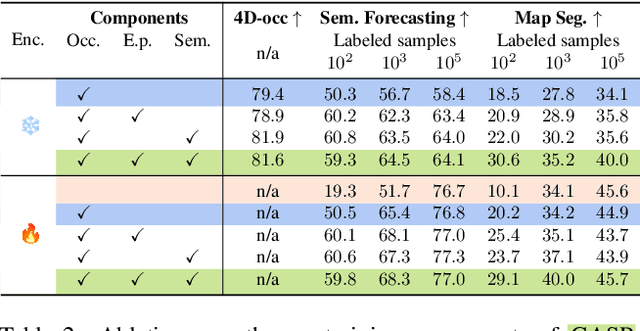
Self-supervised pre-training based on next-token prediction has enabled large language models to capture the underlying structure of text, and has led to unprecedented performance on a large array of tasks when applied at scale. Similarly, autonomous driving generates vast amounts of spatiotemporal data, alluding to the possibility of harnessing scale to learn the underlying geometric and semantic structure of the environment and its evolution over time. In this direction, we propose a geometric and semantic self-supervised pre-training method, GASP, that learns a unified representation by predicting, at any queried future point in spacetime, (1) general occupancy, capturing the evolving structure of the 3D scene; (2) ego occupancy, modeling the ego vehicle path through the environment; and (3) distilled high-level features from a vision foundation model. By modeling geometric and semantic 4D occupancy fields instead of raw sensor measurements, the model learns a structured, generalizable representation of the environment and its evolution through time. We validate GASP on multiple autonomous driving benchmarks, demonstrating significant improvements in semantic occupancy forecasting, online mapping, and ego trajectory prediction. Our results demonstrate that continuous 4D geometric and semantic occupancy prediction provides a scalable and effective pre-training paradigm for autonomous driving. For code and additional visualizations, see \href{https://research.zenseact.com/publications/gasp/.
NeuroNCAP: Photorealistic Closed-loop Safety Testing for Autonomous Driving
Apr 12, 2024



We present a versatile NeRF-based simulator for testing autonomous driving (AD) software systems, designed with a focus on sensor-realistic closed-loop evaluation and the creation of safety-critical scenarios. The simulator learns from sequences of real-world driving sensor data and enables reconfigurations and renderings of new, unseen scenarios. In this work, we use our simulator to test the responses of AD models to safety-critical scenarios inspired by the European New Car Assessment Programme (Euro NCAP). Our evaluation reveals that, while state-of-the-art end-to-end planners excel in nominal driving scenarios in an open-loop setting, they exhibit critical flaws when navigating our safety-critical scenarios in a closed-loop setting. This highlights the need for advancements in the safety and real-world usability of end-to-end planners. By publicly releasing our simulator and scenarios as an easy-to-run evaluation suite, we invite the research community to explore, refine, and validate their AD models in controlled, yet highly configurable and challenging sensor-realistic environments. Code and instructions can be found at https://github.com/wljungbergh/NeuroNCAP
NeuRAD: Neural Rendering for Autonomous Driving
Dec 05, 2023



Neural radiance fields (NeRFs) have gained popularity in the autonomous driving (AD) community. Recent methods show NeRFs' potential for closed-loop simulation, enabling testing of AD systems, and as an advanced training data augmentation technique. However, existing methods often require long training times, dense semantic supervision, or lack generalizability. This, in turn, hinders the application of NeRFs for AD at scale. In this paper, we propose NeuRAD, a robust novel view synthesis method tailored to dynamic AD data. Our method features simple network design, extensive sensor modeling for both camera and lidar -- including rolling shutter, beam divergence and ray dropping -- and is applicable to multiple datasets out of the box. We verify its performance on five popular AD datasets, achieving state-of-the-art performance across the board. To encourage further development, we will openly release the NeuRAD source code. See https://github.com/georghess/NeuRAD .
Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving
May 03, 2023



Existing datasets for autonomous driving (AD) often lack diversity and long-range capabilities, focusing instead on 360{\deg} perception and temporal reasoning. To address this gap, we introduce Zenseact Open Dataset (ZOD), a large-scale and diverse multimodal dataset collected over two years in various European countries, covering an area 9x that of existing datasets. ZOD boasts the highest range and resolution sensors among comparable datasets, coupled with detailed keyframe annotations for 2D and 3D objects (up to 245m), road instance/semantic segmentation, traffic sign recognition, and road classification. We believe that this unique combination will facilitate breakthroughs in long-range perception and multi-task learning. The dataset is composed of Frames, Sequences, and Drives, designed to encompass both data diversity and support for spatio-temporal learning, sensor fusion, localization, and mapping. Frames consist of 100k curated camera images with two seconds of other supporting sensor data, while the 1473 Sequences and 29 Drives include the entire sensor suite for 20 seconds and a few minutes, respectively. ZOD is the only large-scale AD dataset released under a permissive license, allowing for both research and commercial use. The dataset is accompanied by an extensive development kit. Data and more information are available online (https://zod.zenseact.com).
Raw or Cooked? Object Detection on RAW Images
Jan 21, 2023Images fed to a deep neural network have in general undergone several handcrafted image signal processing (ISP) operations, all of which have been optimized to produce visually pleasing images. In this work, we investigate the hypothesis that the intermediate representation of visually pleasing images is sub-optimal for downstream computer vision tasks compared to the RAW image representation. We suggest that the operations of the ISP instead should be optimized towards the end task, by learning the parameters of the operations jointly during training. We extend previous works on this topic and propose a new learnable operation that enables an object detector to achieve superior performance when compared to both previous works and traditional RGB images. In experiments on the open PASCALRAW dataset, we empirically confirm our hypothesis.
Can Deep Learning be Applied to Model-Based Multi-Object Tracking?
Feb 16, 2022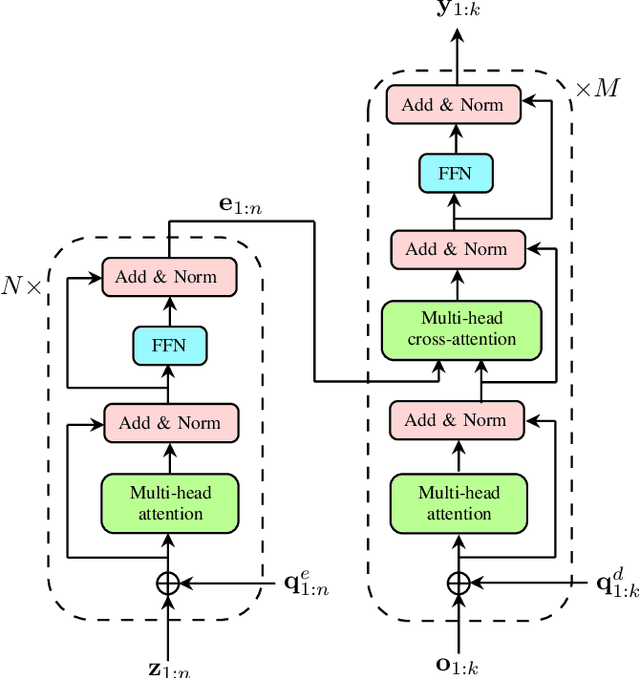
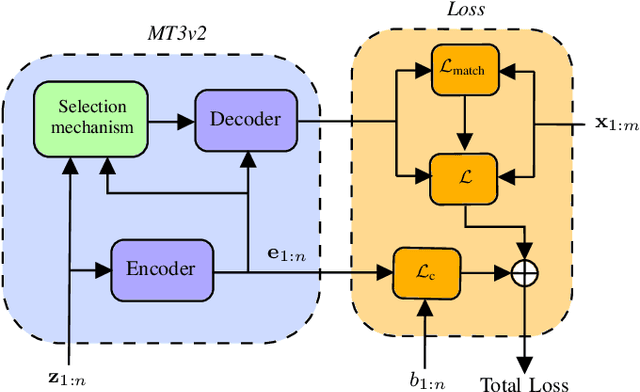

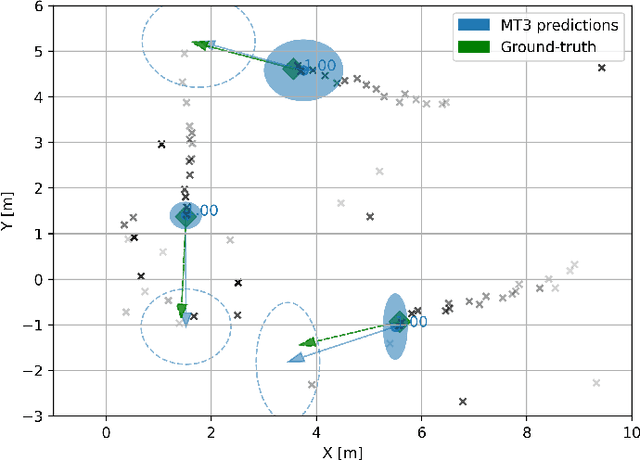
Multi-object tracking (MOT) is the problem of tracking the state of an unknown and time-varying number of objects using noisy measurements, with important applications such as autonomous driving, tracking animal behavior, defense systems, and others. In recent years, deep learning (DL) has been increasingly used in MOT for improving tracking performance, but mostly in settings where the measurements are high-dimensional and there are no available models of the measurement likelihood and the object dynamics. The model-based setting instead has not attracted as much attention, and it is still unclear if DL methods can outperform traditional model-based Bayesian methods, which are the state of the art (SOTA) in this context. In this paper, we propose a Transformer-based DL tracker and evaluate its performance in the model-based setting, comparing it to SOTA model-based Bayesian methods in a variety of different tasks. Our results show that the proposed DL method can match the performance of the model-based methods in simple tasks, while outperforming them when the task gets more complicated, either due to an increase in the data association complexity, or to stronger nonlinearities of the models of the environment.
Deep Deterministic Path Following
Apr 13, 2021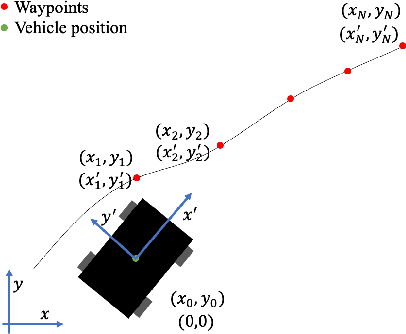
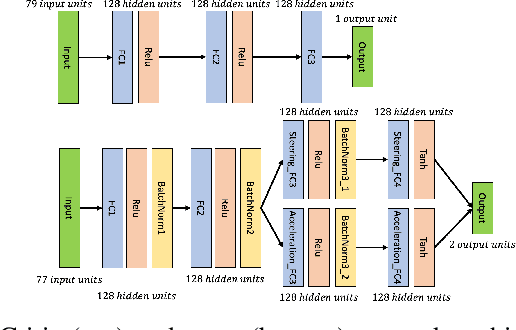
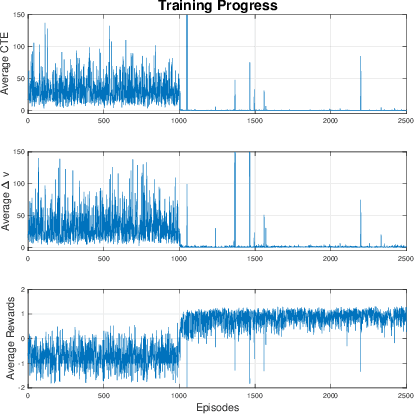
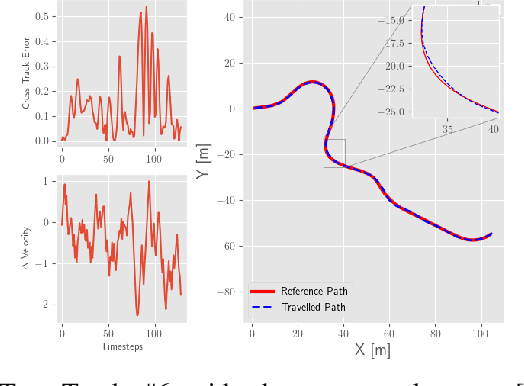
This paper deploys the Deep Deterministic Policy Gradient (DDPG) algorithm for longitudinal and lateral control of a simulated car to solve a path following task. The DDPG agent was implemented using PyTorch and trained and evaluated on a custom kinematic bicycle environment created in Python. The performance was evaluated by measuring cross-track error and velocity error, relative to a reference path. Results show how the agent can learn a policy allowing for small cross-track error, as well as adapting the acceleration to minimize the velocity error.
Next Generation Multitarget Trackers: Random Finite Set Methods vs Transformer-based Deep Learning
Apr 09, 2021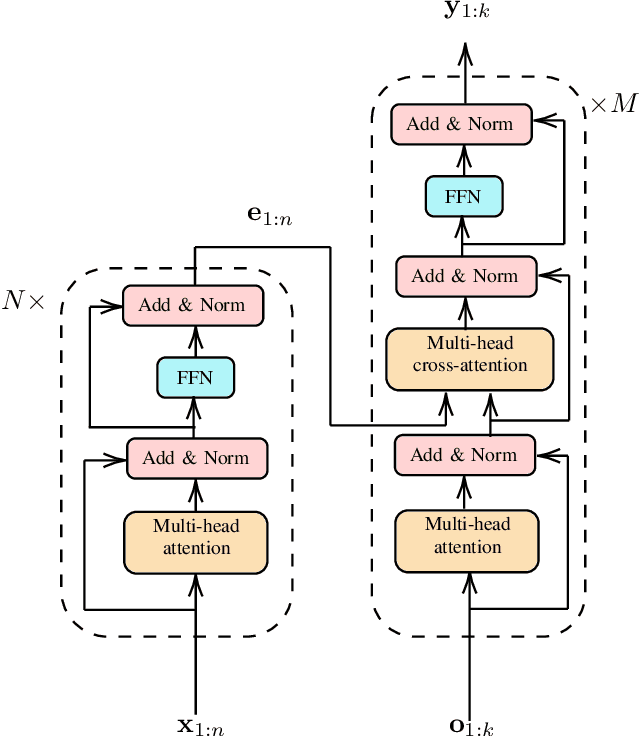
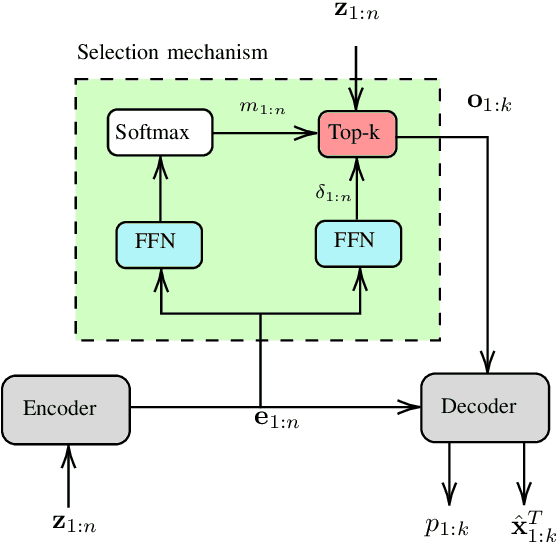
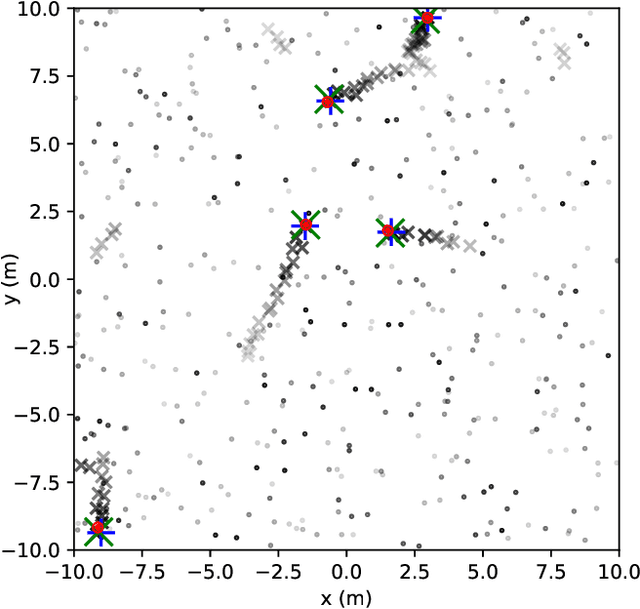
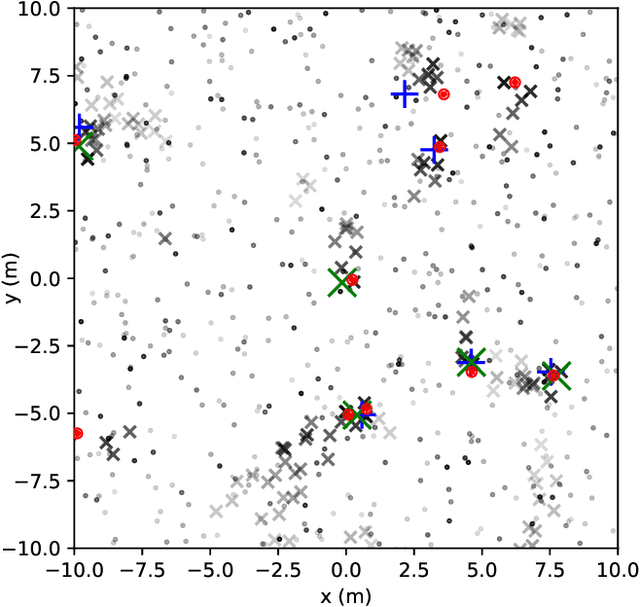
Multitarget Tracking (MTT) is the problem of tracking the states of an unknown number of objects using noisy measurements, with important applications to autonomous driving, surveillance, robotics, and others. In the model-based Bayesian setting, there are conjugate priors that enable us to express the multi-object posterior in closed form, which could theoretically provide Bayes-optimal estimates. However, the posterior involves a super-exponential growth of the number of hypotheses over time, forcing state-of-the-art methods to resort to approximations for remaining tractable, which can impact their performance in complex scenarios. Model-free methods based on deep-learning provide an attractive alternative, as they can, in principle, learn the optimal filter from data, but to the best of our knowledge were never compared to current state-of-the-art Bayesian filters, specially not in contexts where accurate models are available. In this paper, we propose a high-performing deep-learning method for MTT based on the Transformer architecture and compare it to two state-of-the-art Bayesian filters, in a setting where we assume the correct model is provided. Although this gives an edge to the model-based filters, it also allows us to generate unlimited training data. We show that the proposed model outperforms state-of-the-art Bayesian filters in complex scenarios, while matching their performance in simpler cases, which validates the applicability of deep-learning also in the model-based regime. The code for all our implementations is made available at https://github.com/JulianoLagana/MT3 .