 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdacc: Adaptive Compression and Activation Checkpointing for LLM Memory Management
Aug 01, 2025Training large language models often employs recomputation to alleviate memory pressure, which can introduce up to 30% overhead in real-world scenarios. In this paper, we propose Adacc, a novel memory management framework that combines adaptive compression and activation checkpointing to reduce the GPU memory footprint. It comprises three modules: (1) We design layer-specific compression algorithms that account for outliers in LLM tensors, instead of directly quantizing floats from FP16 to INT4, to ensure model accuracy. (2) We propose an optimal scheduling policy that employs MILP to determine the best memory optimization for each tensor. (3) To accommodate changes in training tensors, we introduce an adaptive policy evolution mechanism that adjusts the policy during training to enhance throughput. Experimental results show that Adacc can accelerate the LLM training by 1.01x to 1.37x compared to state-of-the-art frameworks, while maintaining comparable model accuracy to the Baseline.
Saga: Capturing Multi-granularity Semantics from Massive Unlabelled IMU Data for User Perception
Apr 16, 2025Inertial measurement units (IMUs), have been prevalently used in a wide range of mobile perception applications such as activity recognition and user authentication, where a large amount of labelled data are normally required to train a satisfactory model. However, it is difficult to label micro-activities in massive IMU data due to the hardness of understanding raw IMU data and the lack of ground truth. In this paper, we propose a novel fine-grained user perception approach, called Saga, which only needs a small amount of labelled IMU data to achieve stunning user perception accuracy. The core idea of Saga is to first pre-train a backbone feature extraction model, utilizing the rich semantic information of different levels embedded in the massive unlabelled IMU data. Meanwhile, for a specific downstream user perception application, Bayesian Optimization is employed to determine the optimal weights for pre-training tasks involving different semantic levels. We implement Saga on five typical mobile phones and evaluate Saga on three typical tasks on three IMU datasets. Results show that when only using about 100 training samples per class, Saga can achieve over 90% accuracy of the full-fledged model trained on over ten thousands training samples with no additional system overhead.
Decoupled Diffusion Sparks Adaptive Scene Generation
Apr 14, 2025Controllable scene generation could reduce the cost of diverse data collection substantially for autonomous driving. Prior works formulate the traffic layout generation as predictive progress, either by denoising entire sequences at once or by iteratively predicting the next frame. However, full sequence denoising hinders online reaction, while the latter's short-sighted next-frame prediction lacks precise goal-state guidance. Further, the learned model struggles to generate complex or challenging scenarios due to a large number of safe and ordinal driving behaviors from open datasets. To overcome these, we introduce Nexus, a decoupled scene generation framework that improves reactivity and goal conditioning by simulating both ordinal and challenging scenarios from fine-grained tokens with independent noise states. At the core of the decoupled pipeline is the integration of a partial noise-masking training strategy and a noise-aware schedule that ensures timely environmental updates throughout the denoising process. To complement challenging scenario generation, we collect a dataset consisting of complex corner cases. It covers 540 hours of simulated data, including high-risk interactions such as cut-in, sudden braking, and collision. Nexus achieves superior generation realism while preserving reactivity and goal orientation, with a 40% reduction in displacement error. We further demonstrate that Nexus improves closed-loop planning by 20% through data augmentation and showcase its capability in safety-critical data generation.
Detect Anything 3D in the Wild
Apr 10, 2025Despite the success of deep learning in close-set 3D object detection, existing approaches struggle with zero-shot generalization to novel objects and camera configurations. We introduce DetAny3D, a promptable 3D detection foundation model capable of detecting any novel object under arbitrary camera configurations using only monocular inputs. Training a foundation model for 3D detection is fundamentally constrained by the limited availability of annotated 3D data, which motivates DetAny3D to leverage the rich prior knowledge embedded in extensively pre-trained 2D foundation models to compensate for this scarcity. To effectively transfer 2D knowledge to 3D, DetAny3D incorporates two core modules: the 2D Aggregator, which aligns features from different 2D foundation models, and the 3D Interpreter with Zero-Embedding Mapping, which mitigates catastrophic forgetting in 2D-to-3D knowledge transfer. Experimental results validate the strong generalization of our DetAny3D, which not only achieves state-of-the-art performance on unseen categories and novel camera configurations, but also surpasses most competitors on in-domain data.DetAny3D sheds light on the potential of the 3D foundation model for diverse applications in real-world scenarios, e.g., rare object detection in autonomous driving, and demonstrates promise for further exploration of 3D-centric tasks in open-world settings. More visualization results can be found at DetAny3D project page.
Prism: Mining Task-aware Domains in Non-i.i.d. IMU Data for Flexible User Perception
Jan 03, 2025



A wide range of user perception applications leverage inertial measurement unit (IMU) data for online prediction. However, restricted by the non-i.i.d. nature of IMU data collected from mobile devices, most systems work well only in a controlled setting (e.g., for a specific user in particular postures), limiting application scenarios. To achieve uncontrolled online prediction on mobile devices, referred to as the flexible user perception (FUP) problem, is attractive but hard. In this paper, we propose a novel scheme, called Prism, which can obtain high FUP accuracy on mobile devices. The core of Prism is to discover task-aware domains embedded in IMU dataset, and to train a domain-aware model on each identified domain. To this end, we design an expectation-maximization (EM) algorithm to estimate latent domains with respect to the specific downstream perception task. Finally, the best-fit model can be automatically selected for use by comparing the test sample and all identified domains in the feature space. We implement Prism on various mobile devices and conduct extensive experiments. Results demonstrate that Prism can achieve the best FUP performance with a low latency.
SimGen: Simulator-conditioned Driving Scene Generation
Jun 13, 2024
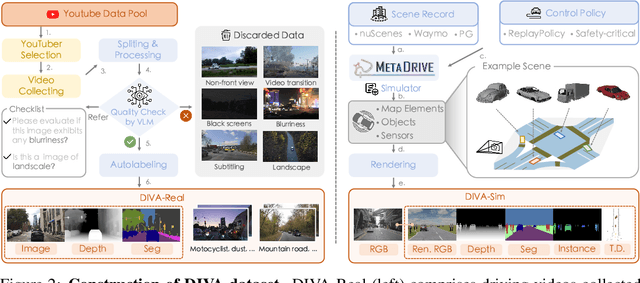
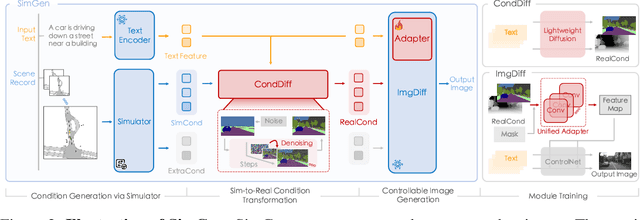

Controllable synthetic data generation can substantially lower the annotation cost of training data in autonomous driving research and development. Prior works use diffusion models to generate driving images conditioned on the 3D object layout. However, those models are trained on small-scale datasets like nuScenes, which lack appearance and layout diversity. Moreover, the trained models can only generate images based on the real-world layout data from the validation set of the same dataset, where overfitting might happen. In this work, we introduce a simulator-conditioned scene generation framework called SimGen that can learn to generate diverse driving scenes by mixing data from the simulator and the real world. It uses a novel cascade diffusion pipeline to address challenging sim-to-real gaps and multi-condition conflicts. A driving video dataset DIVA is collected to enhance the generative diversity of SimGen, which contains over 147.5 hours of real-world driving videos from 73 locations worldwide and simulated driving data from the MetaDrive simulator. SimGen achieves superior generation quality and diversity while preserving controllability based on the text prompt and the layout pulled from a simulator. We further demonstrate the improvements brought by SimGen for synthetic data augmentation on the BEV detection and segmentation task and showcase its capability in safety-critical data generation. Code, data, and models will be made available.
Embodied Understanding of Driving Scenarios
Mar 07, 2024
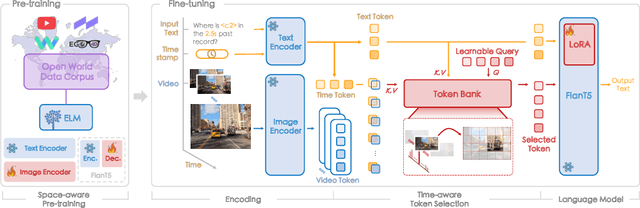
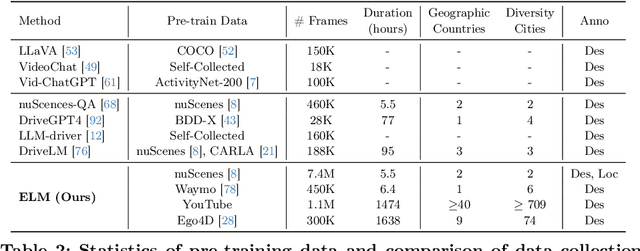
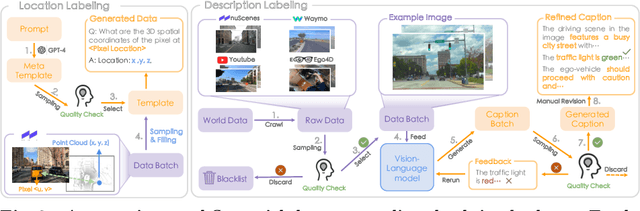
Embodied scene understanding serves as the cornerstone for autonomous agents to perceive, interpret, and respond to open driving scenarios. Such understanding is typically founded upon Vision-Language Models (VLMs). Nevertheless, existing VLMs are restricted to the 2D domain, devoid of spatial awareness and long-horizon extrapolation proficiencies. We revisit the key aspects of autonomous driving and formulate appropriate rubrics. Hereby, we introduce the Embodied Language Model (ELM), a comprehensive framework tailored for agents' understanding of driving scenes with large spatial and temporal spans. ELM incorporates space-aware pre-training to endow the agent with robust spatial localization capabilities. Besides, the model employs time-aware token selection to accurately inquire about temporal cues. We instantiate ELM on the reformulated multi-faced benchmark, and it surpasses previous state-of-the-art approaches in all aspects. All code, data, and models will be publicly shared.
Extend Your Own Correspondences: Unsupervised Distant Point Cloud Registration by Progressive Distance Extension
Mar 06, 2024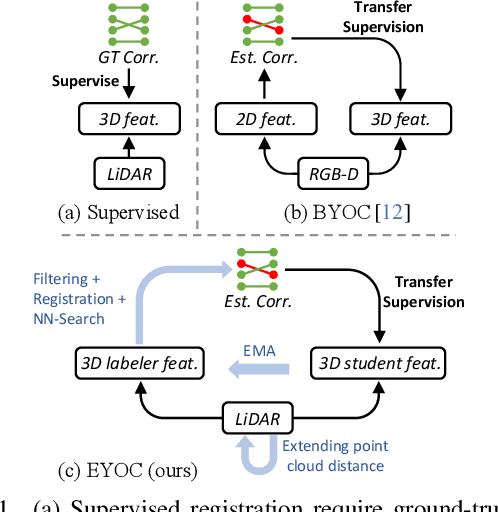
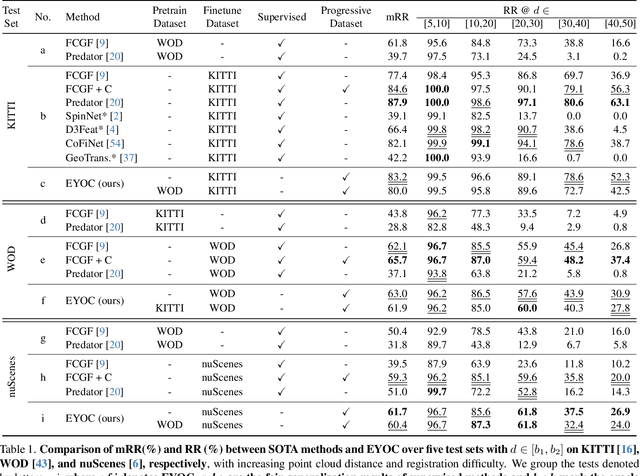
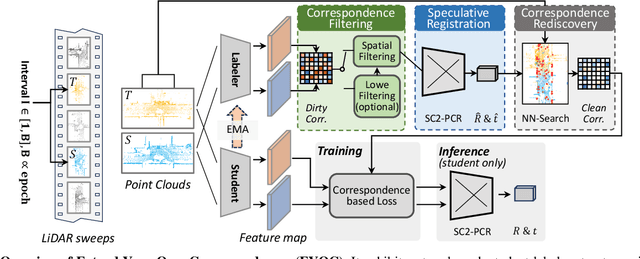

Registration of point clouds collected from a pair of distant vehicles provides a comprehensive and accurate 3D view of the driving scenario, which is vital for driving safety related applications, yet existing literature suffers from the expensive pose label acquisition and the deficiency to generalize to new data distributions. In this paper, we propose EYOC, an unsupervised distant point cloud registration method that adapts to new point cloud distributions on the fly, requiring no global pose labels. The core idea of EYOC is to train a feature extractor in a progressive fashion, where in each round, the feature extractor, trained with near point cloud pairs, can label slightly farther point cloud pairs, enabling self-supervision on such far point cloud pairs. This process continues until the derived extractor can be used to register distant point clouds. Particularly, to enable high-fidelity correspondence label generation, we devise an effective spatial filtering scheme to select the most representative correspondences to register a point cloud pair, and then utilize the aligned point clouds to discover more correct correspondences. Experiments show that EYOC can achieve comparable performance with state-of-the-art supervised methods at a lower training cost. Moreover, it outwits supervised methods regarding generalization performance on new data distributions.
Density-invariant Features for Distant Point Cloud Registration
Aug 08, 2023

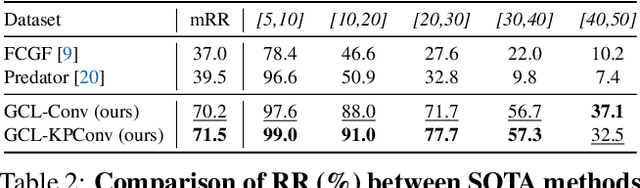
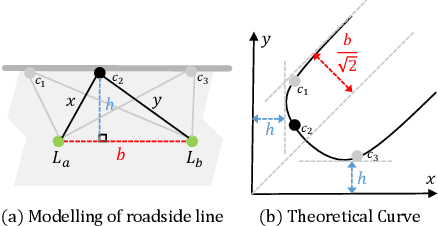
Registration of distant outdoor LiDAR point clouds is crucial to extending the 3D vision of collaborative autonomous vehicles, and yet is challenging due to small overlapping area and a huge disparity between observed point densities. In this paper, we propose Group-wise Contrastive Learning (GCL) scheme to extract density-invariant geometric features to register distant outdoor LiDAR point clouds. We mark through theoretical analysis and experiments that, contrastive positives should be independent and identically distributed (i.i.d.), in order to train densityinvariant feature extractors. We propose upon the conclusion a simple yet effective training scheme to force the feature of multiple point clouds in the same spatial location (referred to as positive groups) to be similar, which naturally avoids the sampling bias introduced by a pair of point clouds to conform with the i.i.d. principle. The resulting fully-convolutional feature extractor is more powerful and density-invariant than state-of-the-art methods, improving the registration recall of distant scenarios on KITTI and nuScenes benchmarks by 40.9% and 26.9%, respectively. Code is available at https://github.com/liuQuan98/GCL.
APR: Online Distant Point Cloud Registration Through Aggregated Point Cloud Reconstruction
May 08, 2023
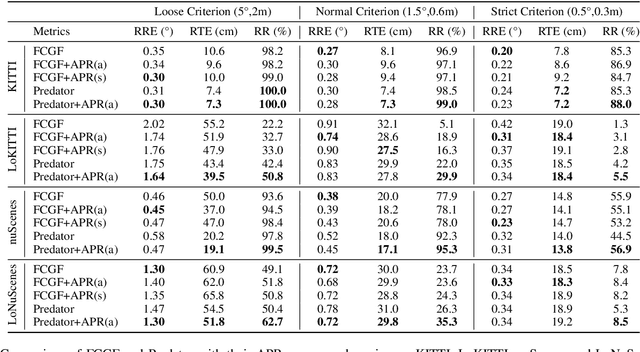
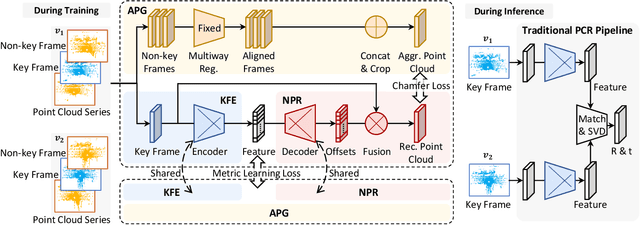

For many driving safety applications, it is of great importance to accurately register LiDAR point clouds generated on distant moving vehicles. However, such point clouds have extremely different point density and sensor perspective on the same object, making registration on such point clouds very hard. In this paper, we propose a novel feature extraction framework, called APR, for online distant point cloud registration. Specifically, APR leverages an autoencoder design, where the autoencoder reconstructs a denser aggregated point cloud with several frames instead of the original single input point cloud. Our design forces the encoder to extract features with rich local geometry information based on one single input point cloud. Such features are then used for online distant point cloud registration. We conduct extensive experiments against state-of-the-art (SOTA) feature extractors on KITTI and nuScenes datasets. Results show that APR outperforms all other extractors by a large margin, increasing average registration recall of SOTA extractors by 7.1% on LoKITTI and 4.6% on LoNuScenes. Code is available at https://github.com/liuQuan98/APR.