 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect Anything 3D in the Wild
Apr 10, 2025Despite the success of deep learning in close-set 3D object detection, existing approaches struggle with zero-shot generalization to novel objects and camera configurations. We introduce DetAny3D, a promptable 3D detection foundation model capable of detecting any novel object under arbitrary camera configurations using only monocular inputs. Training a foundation model for 3D detection is fundamentally constrained by the limited availability of annotated 3D data, which motivates DetAny3D to leverage the rich prior knowledge embedded in extensively pre-trained 2D foundation models to compensate for this scarcity. To effectively transfer 2D knowledge to 3D, DetAny3D incorporates two core modules: the 2D Aggregator, which aligns features from different 2D foundation models, and the 3D Interpreter with Zero-Embedding Mapping, which mitigates catastrophic forgetting in 2D-to-3D knowledge transfer. Experimental results validate the strong generalization of our DetAny3D, which not only achieves state-of-the-art performance on unseen categories and novel camera configurations, but also surpasses most competitors on in-domain data.DetAny3D sheds light on the potential of the 3D foundation model for diverse applications in real-world scenarios, e.g., rare object detection in autonomous driving, and demonstrates promise for further exploration of 3D-centric tasks in open-world settings. More visualization results can be found at DetAny3D project page.
Test-time Correction with Human Feedback: An Online 3D Detection System via Visual Prompting
Dec 10, 2024This paper introduces Test-time Correction (TTC) system, a novel online 3D detection system designated for online correction of test-time errors via human feedback, to guarantee the safety of deployed autonomous driving systems. Unlike well-studied offline 3D detectors frozen at inference, TTC explores the capability of instant online error rectification. By leveraging user feedback with interactive prompts at a frame, e.g., a simple click or draw of boxes, TTC could immediately update the corresponding detection results for future streaming inputs, even though the model is deployed with fixed parameters. This enables autonomous driving systems to adapt to new scenarios immediately and decrease deployment risks reliably without additional expensive training. To achieve such TTC system, we equip existing 3D detectors with Online Adapter (OA) module, a prompt-driven query generator for online correction. At the core of OA module are visual prompts, images of missed object-of-interest for guiding the corresponding detection and subsequent tracking. Those visual prompts, belonging to missed objects through online inference, are maintained by the visual prompt buffer for continuous error correction in subsequent frames. By doing so, TTC consistently detects online missed objects and immediately lowers driving risks. It achieves reliable, versatile, and adaptive driving autonomy. Extensive experiments demonstrate significant gain on instant error rectification over pre-trained 3D detectors, even in challenging scenarios with limited labels, zero-shot detection, and adverse conditions. We hope this work would inspire the community to investigate online rectification systems for autonomous driving post-deployment. Code would be publicly shared.
DriveLM: Driving with Graph Visual Question Answering
Dec 21, 2023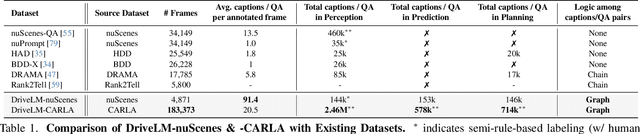
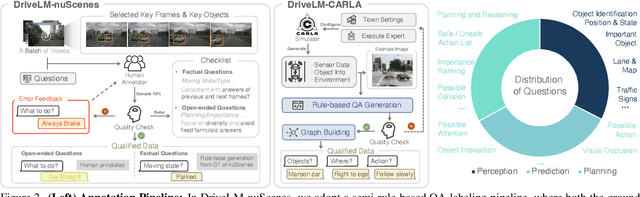
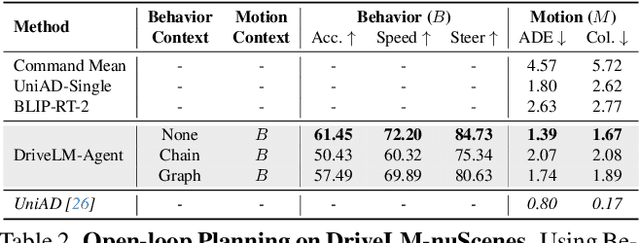
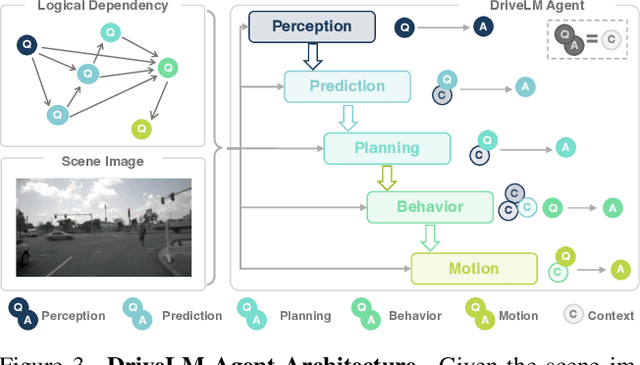
We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual question answering (VQA), human drivers reason about decisions in multiple steps. Starting from the localization of key objects, humans estimate object interactions before taking actions. The key insight is that with our proposed task, Graph VQA, where we model graph-structured reasoning through perception, prediction and planning question-answer pairs, we obtain a suitable proxy task to mimic the human reasoning process. We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving. The experiments demonstrate that Graph VQA provides a simple, principled framework for reasoning about a driving scene, and DriveLM-Data provides a challenging benchmark for this task. Our DriveLM-Agent baseline performs end-to-end autonomous driving competitively in comparison to state-of-the-art driving-specific architectures. Notably, its benefits are pronounced when it is evaluated zero-shot on unseen objects or sensor configurations. We hope this work can be the starting point to shed new light on how to apply VLMs for autonomous driving. To facilitate future research, all code, data, and models are available to the public.
Improving Audio Caption Fluency with Automatic Error Correction
Jun 16, 2023Automated audio captioning (AAC) is an important cross-modality translation task, aiming at generating descriptions for audio clips. However, captions generated by previous AAC models have faced ``false-repetition'' errors due to the training objective. In such scenarios, we propose a new task of AAC error correction and hope to reduce such errors by post-processing AAC outputs. To tackle this problem, we use observation-based rules to corrupt captions without errors, for pseudo grammatically-erroneous sentence generation. One pair of corrupted and clean sentences can thus be used for training. We train a neural network-based model on the synthetic error dataset and apply the model to correct real errors in AAC outputs. Results on two benchmark datasets indicate that our approach significantly improves fluency while maintaining semantic information.