 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed3D-R1: Incentivizing Clinical Reasoning in 3D Medical Vision-Language Models for Abnormality Diagnosis
Feb 01, 2026Developing 3D vision-language models with robust clinical reasoning remains a challenge due to the inherent complexity of volumetric medical imaging, the tendency of models to overfit superficial report patterns, and the lack of interpretability-aware reward designs. In this paper, we propose Med3D-R1, a reinforcement learning framework with a two-stage training process: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). During SFT stage, we introduce a residual alignment mechanism to bridge the gap between high-dimensional 3D features and textual embeddings, and an abnormality re-weighting strategy to emphasize clinically informative tokens and reduce structural bias in reports. In RL stage, we redesign the consistency reward to explicitly promote coherent, step-by-step diagnostic reasoning. We evaluate our method on medical multiple-choice visual question answering using two 3D diagnostic benchmarks, CT-RATE and RAD-ChestCT, where our model attains state-of-the-art accuracies of 41.92\% on CT-RATE and 44.99\% on RAD-ChestCT. These results indicate improved abnormality diagnosis and clinical reasoning and outperform prior methods on both benchmarks. Overall, our approach holds promise for enhancing real-world diagnostic workflows by enabling more reliable and transparent 3D medical vision-language systems.
SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
Sep 10, 2025Medical vision-language pre-training shows great potential in learning representative features from massive paired radiographs and reports. However, in computed tomography (CT) scans, the distribution of lesions which contain intricate structures is characterized by spatial sparsity. Besides, the complex and implicit relationships between different pathological descriptions in each sentence of the report and their corresponding sub-regions in radiographs pose additional challenges. In this paper, we propose a Similarity-Driven Cross-Granularity Pre-training (SimCroP) framework on chest CTs, which combines similarity-driven alignment and cross-granularity fusion to improve radiograph interpretation. We first leverage multi-modal masked modeling to optimize the encoder for understanding precise low-level semantics from radiographs. Then, similarity-driven alignment is designed to pre-train the encoder to adaptively select and align the correct patches corresponding to each sentence in reports. The cross-granularity fusion module integrates multimodal information across instance level and word-patch level, which helps the model better capture key pathology structures in sparse radiographs, resulting in improved performance for multi-scale downstream tasks. SimCroP is pre-trained on a large-scale paired CT-reports dataset and validated on image classification and segmentation tasks across five public datasets. Experimental results demonstrate that SimCroP outperforms both cutting-edge medical self-supervised learning methods and medical vision-language pre-training methods. Codes and models are available at https://github.com/ToniChopp/SimCroP.
Detect Anything 3D in the Wild
Apr 10, 2025Despite the success of deep learning in close-set 3D object detection, existing approaches struggle with zero-shot generalization to novel objects and camera configurations. We introduce DetAny3D, a promptable 3D detection foundation model capable of detecting any novel object under arbitrary camera configurations using only monocular inputs. Training a foundation model for 3D detection is fundamentally constrained by the limited availability of annotated 3D data, which motivates DetAny3D to leverage the rich prior knowledge embedded in extensively pre-trained 2D foundation models to compensate for this scarcity. To effectively transfer 2D knowledge to 3D, DetAny3D incorporates two core modules: the 2D Aggregator, which aligns features from different 2D foundation models, and the 3D Interpreter with Zero-Embedding Mapping, which mitigates catastrophic forgetting in 2D-to-3D knowledge transfer. Experimental results validate the strong generalization of our DetAny3D, which not only achieves state-of-the-art performance on unseen categories and novel camera configurations, but also surpasses most competitors on in-domain data.DetAny3D sheds light on the potential of the 3D foundation model for diverse applications in real-world scenarios, e.g., rare object detection in autonomous driving, and demonstrates promise for further exploration of 3D-centric tasks in open-world settings. More visualization results can be found at DetAny3D project page.
Landmarks Are Alike Yet Distinct: Harnessing Similarity and Individuality for One-Shot Medical Landmark Detection
Mar 20, 2025



Landmark detection plays a crucial role in medical imaging applications such as disease diagnosis, bone age estimation, and therapy planning. However, training models for detecting multiple landmarks simultaneously often encounters the "seesaw phenomenon", where improvements in detecting certain landmarks lead to declines in detecting others. Yet, training a separate model for each landmark increases memory usage and computational overhead. To address these challenges, we propose a novel approach based on the belief that "landmarks are distinct" by training models with pseudo-labels and template data updated continuously during the training process, where each model is dedicated to detecting a single landmark to achieve high accuracy. Furthermore, grounded on the belief that "landmarks are also alike", we introduce an adapter-based fusion model, combining shared weights with landmark-specific weights, to efficiently share model parameters while allowing flexible adaptation to individual landmarks. This approach not only significantly reduces memory and computational resource requirements but also effectively mitigates the seesaw phenomenon in multi-landmark training. Experimental results on publicly available medical image datasets demonstrate that the single-landmark models significantly outperform traditional multi-point joint training models in detecting individual landmarks. Although our adapter-based fusion model shows slightly lower performance compared to the combined results of all single-landmark models, it still surpasses the current state-of-the-art methods while achieving a notable improvement in resource efficiency.
AA-CLIP: Enhancing Zero-shot Anomaly Detection via Anomaly-Aware CLIP
Mar 09, 2025Anomaly detection (AD) identifies outliers for applications like defect and lesion detection. While CLIP shows promise for zero-shot AD tasks due to its strong generalization capabilities, its inherent Anomaly-Unawareness leads to limited discrimination between normal and abnormal features. To address this problem, we propose Anomaly-Aware CLIP (AA-CLIP), which enhances CLIP's anomaly discrimination ability in both text and visual spaces while preserving its generalization capability. AA-CLIP is achieved through a straightforward yet effective two-stage approach: it first creates anomaly-aware text anchors to differentiate normal and abnormal semantics clearly, then aligns patch-level visual features with these anchors for precise anomaly localization. This two-stage strategy, with the help of residual adapters, gradually adapts CLIP in a controlled manner, achieving effective AD while maintaining CLIP's class knowledge. Extensive experiments validate AA-CLIP as a resource-efficient solution for zero-shot AD tasks, achieving state-of-the-art results in industrial and medical applications. The code is available at https://github.com/Mwxinnn/AA-CLIP.
* 8 pages, 7 figures
H3DE-Net: Efficient and Accurate 3D Landmark Detection in Medical Imaging
Feb 20, 20253D landmark detection is a critical task in medical image analysis, and accurately detecting anatomical landmarks is essential for subsequent medical imaging tasks. However, mainstream deep learning methods in this field struggle to simultaneously capture fine-grained local features and model global spatial relationships, while maintaining a balance between accuracy and computational efficiency. Local feature extraction requires capturing fine-grained anatomical details, while global modeling requires understanding the spatial relationships within complex anatomical structures. The high-dimensional nature of 3D volume further exacerbates these challenges, as landmarks are sparsely distributed, leading to significant computational costs. Therefore, achieving efficient and precise 3D landmark detection remains a pressing challenge in medical image analysis. In this work, We propose a \textbf{H}ybrid \textbf{3}D \textbf{DE}tection \textbf{Net}(H3DE-Net), a novel framework that combines CNNs for local feature extraction with a lightweight attention mechanism designed to efficiently capture global dependencies in 3D volumetric data. This mechanism employs a hierarchical routing strategy to reduce computational cost while maintaining global context modeling. To our knowledge, H3DE-Net is the first 3D landmark detection model that integrates such a lightweight attention mechanism with CNNs. Additionally, integrating multi-scale feature fusion further enhances detection accuracy and robustness. Experimental results on a public CT dataset demonstrate that H3DE-Net achieves state-of-the-art(SOTA) performance, significantly improving accuracy and robustness, particularly in scenarios with missing landmarks or complex anatomical variations. We aready open-source our project, including code, data and model weights.
Hi-End-MAE: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation
Feb 12, 2025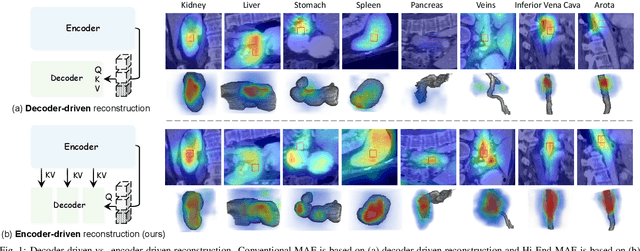
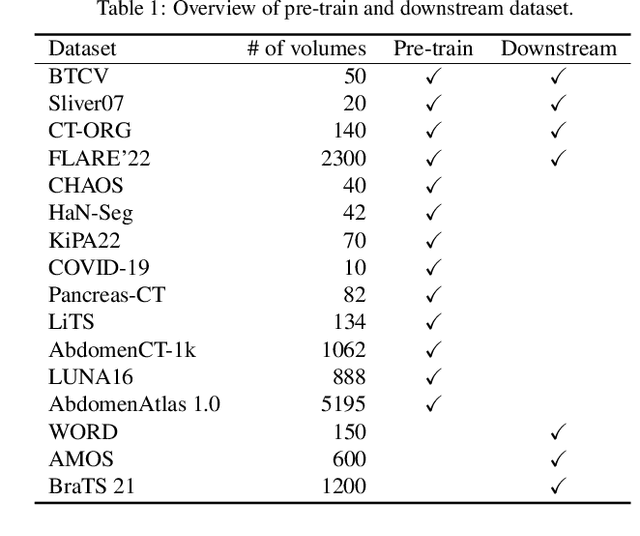
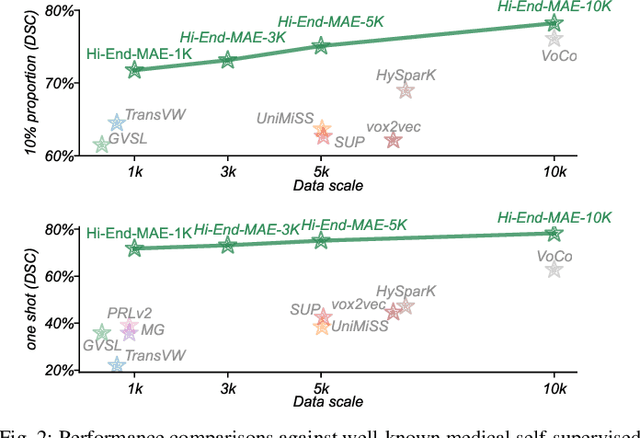
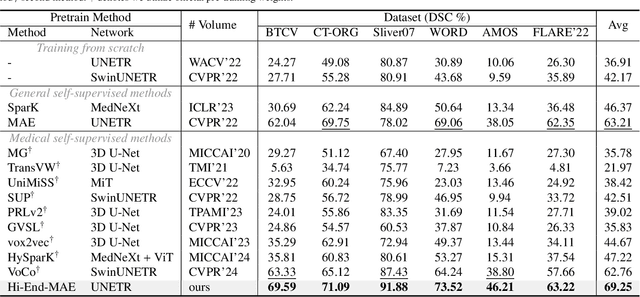
Medical image segmentation remains a formidable challenge due to the label scarcity. Pre-training Vision Transformer (ViT) through masked image modeling (MIM) on large-scale unlabeled medical datasets presents a promising solution, providing both computational efficiency and model generalization for various downstream tasks. However, current ViT-based MIM pre-training frameworks predominantly emphasize local aggregation representations in output layers and fail to exploit the rich representations across different ViT layers that better capture fine-grained semantic information needed for more precise medical downstream tasks. To fill the above gap, we hereby present Hierarchical Encoder-driven MAE (Hi-End-MAE), a simple yet effective ViT-based pre-training solution, which centers on two key innovations: (1) Encoder-driven reconstruction, which encourages the encoder to learn more informative features to guide the reconstruction of masked patches; and (2) Hierarchical dense decoding, which implements a hierarchical decoding structure to capture rich representations across different layers. We pre-train Hi-End-MAE on a large-scale dataset of 10K CT scans and evaluated its performance across seven public medical image segmentation benchmarks. Extensive experiments demonstrate that Hi-End-MAE achieves superior transfer learning capabilities across various downstream tasks, revealing the potential of ViT in medical imaging applications. The code is available at: https://github.com/FengheTan9/Hi-End-MAE
Towards Accurate Unified Anomaly Segmentation
Jan 21, 2025
Unsupervised anomaly detection (UAD) from images strives to model normal data distributions, creating discriminative representations to distinguish and precisely localize anomalies. Despite recent advancements in the efficient and unified one-for-all scheme, challenges persist in accurately segmenting anomalies for further monitoring. Moreover, this problem is obscured by the widely-used AUROC metric under imbalanced UAD settings. This motivates us to emphasize the significance of precise segmentation of anomaly pixels using pAP and DSC as metrics. To address the unsolved segmentation task, we introduce the Unified Anomaly Segmentation (UniAS). UniAS presents a multi-level hybrid pipeline that progressively enhances normal information from coarse to fine, incorporating a novel multi-granularity gated CNN (MGG-CNN) into Transformer layers to explicitly aggregate local details from different granularities. UniAS achieves state-of-the-art anomaly segmentation performance, attaining 65.12/59.33 and 40.06/32.50 in pAP/DSC on the MVTec-AD and VisA datasets, respectively, surpassing previous methods significantly. The codes are shared at https://github.com/Mwxinnn/UniAS.
Bridged Semantic Alignment for Zero-shot 3D Medical Image Diagnosis
Jan 07, 20253D medical images such as Computed tomography (CT) are widely used in clinical practice, offering a great potential for automatic diagnosis. Supervised learning-based approaches have achieved significant progress but rely heavily on extensive manual annotations, limited by the availability of training data and the diversity of abnormality types. Vision-language alignment (VLA) offers a promising alternative by enabling zero-shot learning without additional annotations. However, we empirically discover that the visual and textural embeddings after alignment endeavors from existing VLA methods form two well-separated clusters, presenting a wide gap to be bridged. To bridge this gap, we propose a Bridged Semantic Alignment (BrgSA) framework. First, we utilize a large language model to perform semantic summarization of reports, extracting high-level semantic information. Second, we design a Cross-Modal Knowledge Interaction (CMKI) module that leverages a cross-modal knowledge bank as a semantic bridge, facilitating interaction between the two modalities, narrowing the gap, and improving their alignment. To comprehensively evaluate our method, we construct a benchmark dataset that includes 15 underrepresented abnormalities as well as utilize two existing benchmark datasets. Experimental results demonstrate that BrgSA achieves state-of-the-art performances on both public benchmark datasets and our custom-labeled dataset, with significant improvements in zero-shot diagnosis of underrepresented abnormalities.
HYATT-Net is Grand: A Hybrid Attention Network for Performant Anatomical Landmark Detection
Dec 16, 2024



Anatomical landmark detection (ALD) from a medical image is crucial for a wide array of clinical applications. While existing methods achieve quite some success in ALD, they often struggle to balance global context with computational efficiency, particularly with high-resolution images, thereby leading to the rise of a natural question: where is the performance limit of ALD? In this paper, we aim to forge performant ALD by proposing a {\bf HY}brid {\bf ATT}ention {\bf Net}work (HYATT-Net) with the following designs: (i) A novel hybrid architecture that integrates CNNs and Transformers. Its core is the BiFormer module, utilizing Bi-Level Routing Attention for efficient attention to relevant image regions. This, combined with Attention Residual Module(ARM), enables precise local feature refinement guided by the global context. (ii) A Feature Fusion Correction Module that aggregates multi-scale features and thus mitigates a resolution loss. Deep supervision with a mean-square error loss on multi-resolution heatmaps optimizes the model. Experiments on five diverse datasets demonstrate state-of-the-art performance, surpassing existing methods in accuracy, robustness, and efficiency. The HYATT-Net provides a promising solution for accurate and efficient ALD in complex medical images. Our codes and data are already released at: \url{https://github.com/ECNUACRush/HYATT-Net}.