 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE3D-GPT: Enhanced 3D Visual Foundation for Medical Vision-Language Model
Paper and Code
Oct 18, 2024
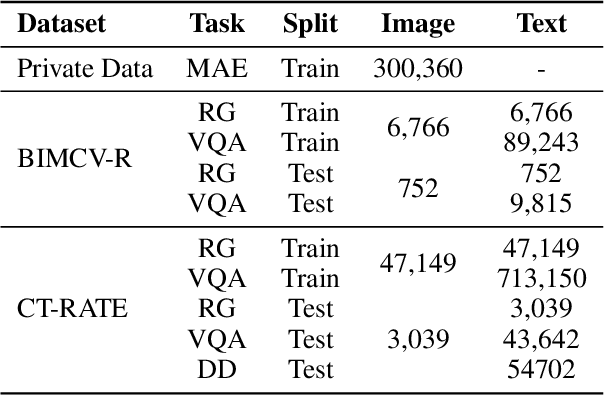


The development of 3D medical vision-language models holds significant potential for disease diagnosis and patient treatment. However, compared to 2D medical images, 3D medical images, such as CT scans, face challenges related to limited training data and high dimension, which severely restrict the progress of 3D medical vision-language models. To address these issues, we collect a large amount of unlabeled 3D CT data and utilize self-supervised learning to construct a 3D visual foundation model for extracting 3D visual features. Then, we apply 3D spatial convolutions to aggregate and project high-level image features, reducing computational complexity while preserving spatial information. We also construct two instruction-tuning datasets based on BIMCV-R and CT-RATE to fine-tune the 3D vision-language model. Our model demonstrates superior performance compared to existing methods in report generation, visual question answering, and disease diagnosis. Code and data will be made publicly available soon.