 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed3D-R1: Incentivizing Clinical Reasoning in 3D Medical Vision-Language Models for Abnormality Diagnosis
Feb 01, 2026Developing 3D vision-language models with robust clinical reasoning remains a challenge due to the inherent complexity of volumetric medical imaging, the tendency of models to overfit superficial report patterns, and the lack of interpretability-aware reward designs. In this paper, we propose Med3D-R1, a reinforcement learning framework with a two-stage training process: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). During SFT stage, we introduce a residual alignment mechanism to bridge the gap between high-dimensional 3D features and textual embeddings, and an abnormality re-weighting strategy to emphasize clinically informative tokens and reduce structural bias in reports. In RL stage, we redesign the consistency reward to explicitly promote coherent, step-by-step diagnostic reasoning. We evaluate our method on medical multiple-choice visual question answering using two 3D diagnostic benchmarks, CT-RATE and RAD-ChestCT, where our model attains state-of-the-art accuracies of 41.92\% on CT-RATE and 44.99\% on RAD-ChestCT. These results indicate improved abnormality diagnosis and clinical reasoning and outperform prior methods on both benchmarks. Overall, our approach holds promise for enhancing real-world diagnostic workflows by enabling more reliable and transparent 3D medical vision-language systems.
Equivariant Sampling for Improving Diffusion Model-based Image Restoration
Nov 13, 2025

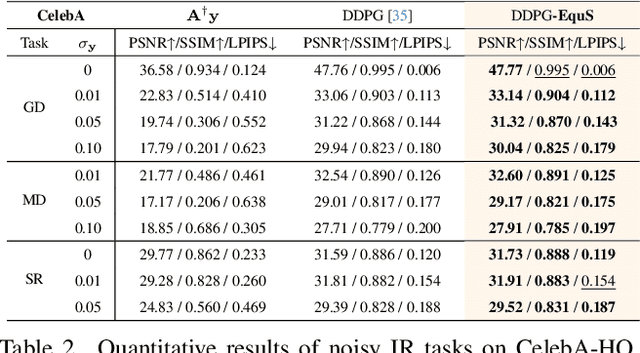

Recent advances in generative models, especially diffusion models, have significantly improved image restoration (IR) performance. However, existing problem-agnostic diffusion model-based image restoration (DMIR) methods face challenges in fully leveraging diffusion priors, resulting in suboptimal performance. In this paper, we address the limitations of current problem-agnostic DMIR methods by analyzing their sampling process and providing effective solutions. We introduce EquS, a DMIR method that imposes equivariant information through dual sampling trajectories. To further boost EquS, we propose the Timestep-Aware Schedule (TAS) and introduce EquS$^+$. TAS prioritizes deterministic steps to enhance certainty and sampling efficiency. Extensive experiments on benchmarks demonstrate that our method is compatible with previous problem-agnostic DMIR methods and significantly boosts their performance without increasing computational costs. Our code is available at https://github.com/FouierL/EquS.
U-Bench: A Comprehensive Understanding of U-Net through 100-Variant Benchmarking
Oct 08, 2025


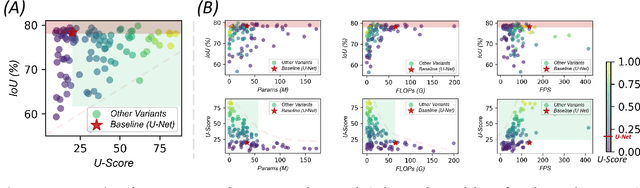
Over the past decade, U-Net has been the dominant architecture in medical image segmentation, leading to the development of thousands of U-shaped variants. Despite its widespread adoption, there is still no comprehensive benchmark to systematically evaluate their performance and utility, largely because of insufficient statistical validation and limited consideration of efficiency and generalization across diverse datasets. To bridge this gap, we present U-Bench, the first large-scale, statistically rigorous benchmark that evaluates 100 U-Net variants across 28 datasets and 10 imaging modalities. Our contributions are threefold: (1) Comprehensive Evaluation: U-Bench evaluates models along three key dimensions: statistical robustness, zero-shot generalization, and computational efficiency. We introduce a novel metric, U-Score, which jointly captures the performance-efficiency trade-off, offering a deployment-oriented perspective on model progress. (2) Systematic Analysis and Model Selection Guidance: We summarize key findings from the large-scale evaluation and systematically analyze the impact of dataset characteristics and architectural paradigms on model performance. Based on these insights, we propose a model advisor agent to guide researchers in selecting the most suitable models for specific datasets and tasks. (3) Public Availability: We provide all code, models, protocols, and weights, enabling the community to reproduce our results and extend the benchmark with future methods. In summary, U-Bench not only exposes gaps in previous evaluations but also establishes a foundation for fair, reproducible, and practically relevant benchmarking in the next decade of U-Net-based segmentation models. The project can be accessed at: https://fenghetan9.github.io/ubench. Code is available at: https://github.com/FengheTan9/U-Bench.
SimCroP: Radiograph Representation Learning with Similarity-driven Cross-granularity Pre-training
Sep 10, 2025Medical vision-language pre-training shows great potential in learning representative features from massive paired radiographs and reports. However, in computed tomography (CT) scans, the distribution of lesions which contain intricate structures is characterized by spatial sparsity. Besides, the complex and implicit relationships between different pathological descriptions in each sentence of the report and their corresponding sub-regions in radiographs pose additional challenges. In this paper, we propose a Similarity-Driven Cross-Granularity Pre-training (SimCroP) framework on chest CTs, which combines similarity-driven alignment and cross-granularity fusion to improve radiograph interpretation. We first leverage multi-modal masked modeling to optimize the encoder for understanding precise low-level semantics from radiographs. Then, similarity-driven alignment is designed to pre-train the encoder to adaptively select and align the correct patches corresponding to each sentence in reports. The cross-granularity fusion module integrates multimodal information across instance level and word-patch level, which helps the model better capture key pathology structures in sparse radiographs, resulting in improved performance for multi-scale downstream tasks. SimCroP is pre-trained on a large-scale paired CT-reports dataset and validated on image classification and segmentation tasks across five public datasets. Experimental results demonstrate that SimCroP outperforms both cutting-edge medical self-supervised learning methods and medical vision-language pre-training methods. Codes and models are available at https://github.com/ToniChopp/SimCroP.
Dyna3DGR: 4D Cardiac Motion Tracking with Dynamic 3D Gaussian Representation
Jul 22, 2025Accurate analysis of cardiac motion is crucial for evaluating cardiac function. While dynamic cardiac magnetic resonance imaging (CMR) can capture detailed tissue motion throughout the cardiac cycle, the fine-grained 4D cardiac motion tracking remains challenging due to the homogeneous nature of myocardial tissue and the lack of distinctive features. Existing approaches can be broadly categorized into image based and representation-based, each with its limitations. Image-based methods, including both raditional and deep learning-based registration approaches, either struggle with topological consistency or rely heavily on extensive training data. Representation-based methods, while promising, often suffer from loss of image-level details. To address these limitations, we propose Dynamic 3D Gaussian Representation (Dyna3DGR), a novel framework that combines explicit 3D Gaussian representation with implicit neural motion field modeling. Our method simultaneously optimizes cardiac structure and motion in a self-supervised manner, eliminating the need for extensive training data or point-to-point correspondences. Through differentiable volumetric rendering, Dyna3DGR efficiently bridges continuous motion representation with image-space alignment while preserving both topological and temporal consistency. Comprehensive evaluations on the ACDC dataset demonstrate that our approach surpasses state-of-the-art deep learning-based diffeomorphic registration methods in tracking accuracy. The code will be available in https://github.com/windrise/Dyna3DGR.
AA-CLIP: Enhancing Zero-shot Anomaly Detection via Anomaly-Aware CLIP
Mar 09, 2025Anomaly detection (AD) identifies outliers for applications like defect and lesion detection. While CLIP shows promise for zero-shot AD tasks due to its strong generalization capabilities, its inherent Anomaly-Unawareness leads to limited discrimination between normal and abnormal features. To address this problem, we propose Anomaly-Aware CLIP (AA-CLIP), which enhances CLIP's anomaly discrimination ability in both text and visual spaces while preserving its generalization capability. AA-CLIP is achieved through a straightforward yet effective two-stage approach: it first creates anomaly-aware text anchors to differentiate normal and abnormal semantics clearly, then aligns patch-level visual features with these anchors for precise anomaly localization. This two-stage strategy, with the help of residual adapters, gradually adapts CLIP in a controlled manner, achieving effective AD while maintaining CLIP's class knowledge. Extensive experiments validate AA-CLIP as a resource-efficient solution for zero-shot AD tasks, achieving state-of-the-art results in industrial and medical applications. The code is available at https://github.com/Mwxinnn/AA-CLIP.
* 8 pages, 7 figures
Hi-End-MAE: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation
Feb 12, 2025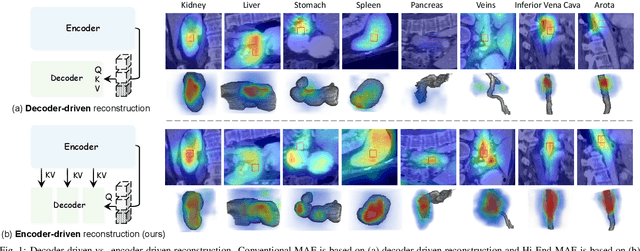
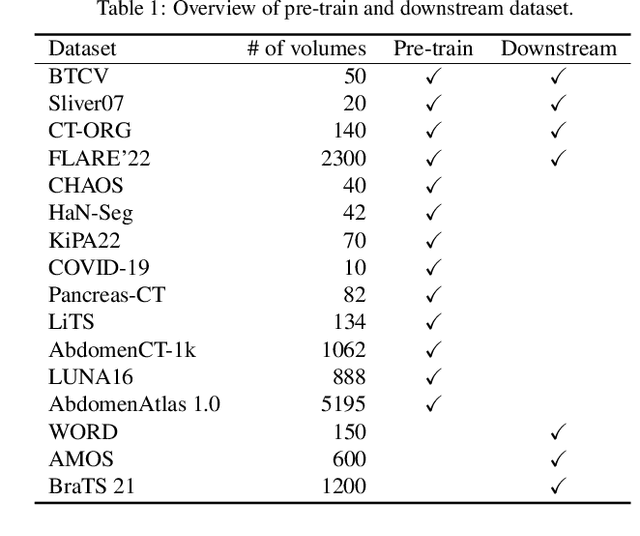
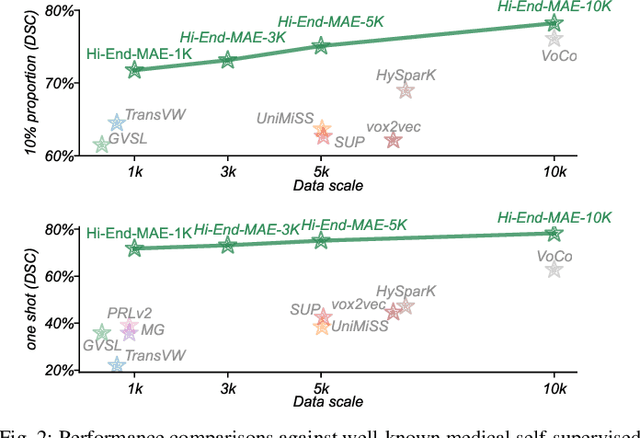
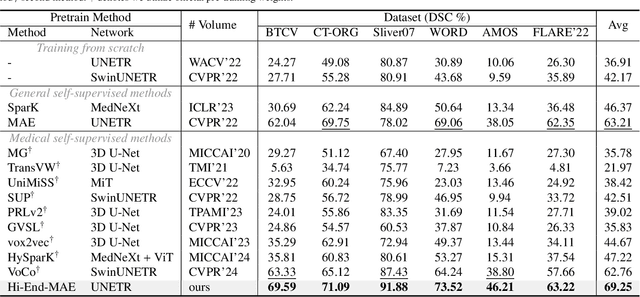
Medical image segmentation remains a formidable challenge due to the label scarcity. Pre-training Vision Transformer (ViT) through masked image modeling (MIM) on large-scale unlabeled medical datasets presents a promising solution, providing both computational efficiency and model generalization for various downstream tasks. However, current ViT-based MIM pre-training frameworks predominantly emphasize local aggregation representations in output layers and fail to exploit the rich representations across different ViT layers that better capture fine-grained semantic information needed for more precise medical downstream tasks. To fill the above gap, we hereby present Hierarchical Encoder-driven MAE (Hi-End-MAE), a simple yet effective ViT-based pre-training solution, which centers on two key innovations: (1) Encoder-driven reconstruction, which encourages the encoder to learn more informative features to guide the reconstruction of masked patches; and (2) Hierarchical dense decoding, which implements a hierarchical decoding structure to capture rich representations across different layers. We pre-train Hi-End-MAE on a large-scale dataset of 10K CT scans and evaluated its performance across seven public medical image segmentation benchmarks. Extensive experiments demonstrate that Hi-End-MAE achieves superior transfer learning capabilities across various downstream tasks, revealing the potential of ViT in medical imaging applications. The code is available at: https://github.com/FengheTan9/Hi-End-MAE
Towards Accurate Unified Anomaly Segmentation
Jan 21, 2025
Unsupervised anomaly detection (UAD) from images strives to model normal data distributions, creating discriminative representations to distinguish and precisely localize anomalies. Despite recent advancements in the efficient and unified one-for-all scheme, challenges persist in accurately segmenting anomalies for further monitoring. Moreover, this problem is obscured by the widely-used AUROC metric under imbalanced UAD settings. This motivates us to emphasize the significance of precise segmentation of anomaly pixels using pAP and DSC as metrics. To address the unsolved segmentation task, we introduce the Unified Anomaly Segmentation (UniAS). UniAS presents a multi-level hybrid pipeline that progressively enhances normal information from coarse to fine, incorporating a novel multi-granularity gated CNN (MGG-CNN) into Transformer layers to explicitly aggregate local details from different granularities. UniAS achieves state-of-the-art anomaly segmentation performance, attaining 65.12/59.33 and 40.06/32.50 in pAP/DSC on the MVTec-AD and VisA datasets, respectively, surpassing previous methods significantly. The codes are shared at https://github.com/Mwxinnn/UniAS.
Bridged Semantic Alignment for Zero-shot 3D Medical Image Diagnosis
Jan 07, 20253D medical images such as Computed tomography (CT) are widely used in clinical practice, offering a great potential for automatic diagnosis. Supervised learning-based approaches have achieved significant progress but rely heavily on extensive manual annotations, limited by the availability of training data and the diversity of abnormality types. Vision-language alignment (VLA) offers a promising alternative by enabling zero-shot learning without additional annotations. However, we empirically discover that the visual and textural embeddings after alignment endeavors from existing VLA methods form two well-separated clusters, presenting a wide gap to be bridged. To bridge this gap, we propose a Bridged Semantic Alignment (BrgSA) framework. First, we utilize a large language model to perform semantic summarization of reports, extracting high-level semantic information. Second, we design a Cross-Modal Knowledge Interaction (CMKI) module that leverages a cross-modal knowledge bank as a semantic bridge, facilitating interaction between the two modalities, narrowing the gap, and improving their alignment. To comprehensively evaluate our method, we construct a benchmark dataset that includes 15 underrepresented abnormalities as well as utilize two existing benchmark datasets. Experimental results demonstrate that BrgSA achieves state-of-the-art performances on both public benchmark datasets and our custom-labeled dataset, with significant improvements in zero-shot diagnosis of underrepresented abnormalities.
E3D-GPT: Enhanced 3D Visual Foundation for Medical Vision-Language Model
Oct 18, 2024
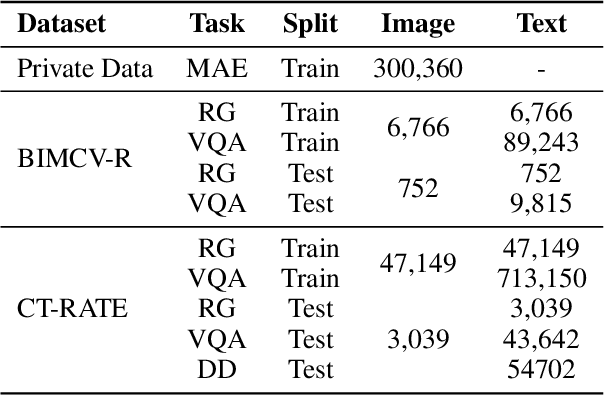


The development of 3D medical vision-language models holds significant potential for disease diagnosis and patient treatment. However, compared to 2D medical images, 3D medical images, such as CT scans, face challenges related to limited training data and high dimension, which severely restrict the progress of 3D medical vision-language models. To address these issues, we collect a large amount of unlabeled 3D CT data and utilize self-supervised learning to construct a 3D visual foundation model for extracting 3D visual features. Then, we apply 3D spatial convolutions to aggregate and project high-level image features, reducing computational complexity while preserving spatial information. We also construct two instruction-tuning datasets based on BIMCV-R and CT-RATE to fine-tune the 3D vision-language model. Our model demonstrates superior performance compared to existing methods in report generation, visual question answering, and disease diagnosis. Code and data will be made publicly available soon.