 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Sampling for Improving Diffusion Model-based Image Restoration
Nov 13, 2025

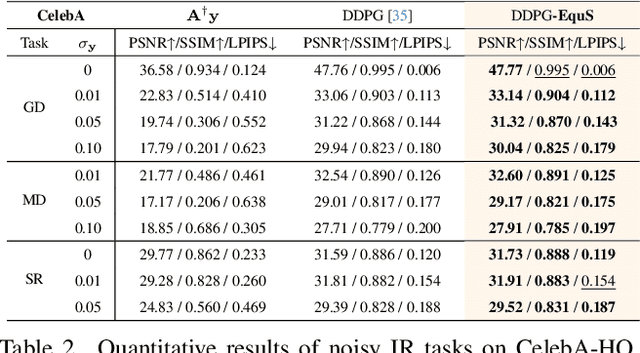

Recent advances in generative models, especially diffusion models, have significantly improved image restoration (IR) performance. However, existing problem-agnostic diffusion model-based image restoration (DMIR) methods face challenges in fully leveraging diffusion priors, resulting in suboptimal performance. In this paper, we address the limitations of current problem-agnostic DMIR methods by analyzing their sampling process and providing effective solutions. We introduce EquS, a DMIR method that imposes equivariant information through dual sampling trajectories. To further boost EquS, we propose the Timestep-Aware Schedule (TAS) and introduce EquS$^+$. TAS prioritizes deterministic steps to enhance certainty and sampling efficiency. Extensive experiments on benchmarks demonstrate that our method is compatible with previous problem-agnostic DMIR methods and significantly boosts their performance without increasing computational costs. Our code is available at https://github.com/FouierL/EquS.
MS-Glance: Non-semantic context vectors and the applications in supervising image reconstruction
Oct 31, 2024Non-semantic context information is crucial for visual recognition, as the human visual perception system first uses global statistics to process scenes rapidly before identifying specific objects. However, while semantic information is increasingly incorporated into computer vision tasks such as image reconstruction, non-semantic information, such as global spatial structures, is often overlooked. To bridge the gap, we propose a biologically informed non-semantic context descriptor, \textbf{MS-Glance}, along with the Glance Index Measure for comparing two images. A Global Glance vector is formulated by randomly retrieving pixels based on a perception-driven rule from an image to form a vector representing non-semantic global context, while a local Glance vector is a flattened local image window, mimicking a zoom-in observation. The Glance Index is defined as the inner product of two standardized sets of Glance vectors. We evaluate the effectiveness of incorporating Glance supervision in two reconstruction tasks: image fitting with implicit neural representation (INR) and undersampled MRI reconstruction. Extensive experimental results show that MS-Glance outperforms existing image restoration losses across both natural and medical images. The code is available at \url{https://github.com/Z7Gao/MSGlance}.
PostoMETRO: Pose Token Enhanced Mesh Transformer for Robust 3D Human Mesh Recovery
Mar 19, 2024With the recent advancements in single-image-based human mesh recovery, there is a growing interest in enhancing its performance in certain extreme scenarios, such as occlusion, while maintaining overall model accuracy. Although obtaining accurately annotated 3D human poses under occlusion is challenging, there is still a wealth of rich and precise 2D pose annotations that can be leveraged. However, existing works mostly focus on directly leveraging 2D pose coordinates to estimate 3D pose and mesh. In this paper, we present PostoMETRO($\textbf{Pos}$e $\textbf{to}$ken enhanced $\textbf{ME}$sh $\textbf{TR}$ansf$\textbf{O}$rmer), which integrates occlusion-resilient 2D pose representation into transformers in a token-wise manner. Utilizing a specialized pose tokenizer, we efficiently condense 2D pose data to a compact sequence of pose tokens and feed them to the transformer together with the image tokens. This process not only ensures a rich depiction of texture from the image but also fosters a robust integration of pose and image information. Subsequently, these combined tokens are queried by vertex and joint tokens to decode 3D coordinates of mesh vertices and human joints. Facilitated by the robust pose token representation and the effective combination, we are able to produce more precise 3D coordinates, even under extreme scenarios like occlusion. Experiments on both standard and occlusion-specific benchmarks demonstrate the effectiveness of PostoMETRO. Qualitative results further illustrate the clarity of how 2D pose can help 3D reconstruction. Code will be made available.