 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Text Following: Repairable Arbitration Reversals in Audio-Language Models
Jun 03, 2026Audio-language models (ALMs) often follow text that conflicts with audio, even when the audio evidence is clear. This raises a basic question: is the audio-supported answer unavailable, or is it represented but overridden by the conflicting text? We examine this question using a same-audio counterfactual that keeps the audio fixed, removes only the conflicting text, and measures the resulting shift in model preference. Across five ALMs and four conflict tasks, 64.1% of conflict samples show a sign flip: the same-audio branch prefers the audio-supported answer, whereas the joint branch prefers the text-supported answer. This pattern suggests that the relevant audio evidence is encoded but loses in arbitration. Activation patching further localizes the reversal to answer-position computation, and patching effects closely track output candidate-score differences (Spearman rho=0.93). Using this diagnostic, we propose Gated Audio Counterfactual Logit Correction (GACL), a training-free decoding rule that interpolates between joint and same-audio scores. Under a strict 5 pp faithfulness-drop budget, GACL improves nAUC by 17.8 points over the best contrastive baseline and transfers without retuning to vision-text arbitration (up to +40.5 pp).
NeRF-based CBCT Reconstruction needs Normalization and Initialization
Jun 24, 2025Cone Beam Computed Tomography (CBCT) is widely used in medical imaging. However, the limited number and intensity of X-ray projections make reconstruction an ill-posed problem with severe artifacts. NeRF-based methods have achieved great success in this task. However, they suffer from a local-global training mismatch between their two key components: the hash encoder and the neural network. Specifically, in each training step, only a subset of the hash encoder's parameters is used (local sparse), whereas all parameters in the neural network participate (global dense). Consequently, hash features generated in each step are highly misaligned, as they come from different subsets of the hash encoder. These misalignments from different training steps are then fed into the neural network, causing repeated inconsistent global updates in training, which leads to unstable training, slower convergence, and degraded reconstruction quality. Aiming to alleviate the impact of this local-global optimization mismatch, we introduce a Normalized Hash Encoder, which enhances feature consistency and mitigates the mismatch. Additionally, we propose a Mapping Consistency Initialization(MCI) strategy that initializes the neural network before training by leveraging the global mapping property from a well-trained model. The initialized neural network exhibits improved stability during early training, enabling faster convergence and enhanced reconstruction performance. Our method is simple yet effective, requiring only a few lines of code while substantially improving training efficiency on 128 CT cases collected from 4 different datasets, covering 7 distinct anatomical regions.
MS-Glance: Non-semantic context vectors and the applications in supervising image reconstruction
Oct 31, 2024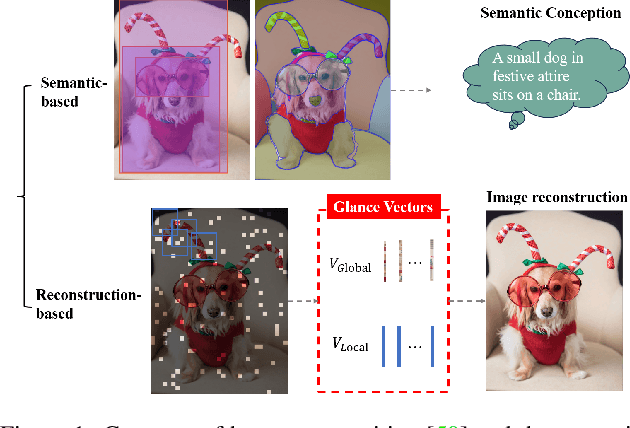
Non-semantic context information is crucial for visual recognition, as the human visual perception system first uses global statistics to process scenes rapidly before identifying specific objects. However, while semantic information is increasingly incorporated into computer vision tasks such as image reconstruction, non-semantic information, such as global spatial structures, is often overlooked. To bridge the gap, we propose a biologically informed non-semantic context descriptor, \textbf{MS-Glance}, along with the Glance Index Measure for comparing two images. A Global Glance vector is formulated by randomly retrieving pixels based on a perception-driven rule from an image to form a vector representing non-semantic global context, while a local Glance vector is a flattened local image window, mimicking a zoom-in observation. The Glance Index is defined as the inner product of two standardized sets of Glance vectors. We evaluate the effectiveness of incorporating Glance supervision in two reconstruction tasks: image fitting with implicit neural representation (INR) and undersampled MRI reconstruction. Extensive experimental results show that MS-Glance outperforms existing image restoration losses across both natural and medical images. The code is available at \url{https://github.com/Z7Gao/MSGlance}.
Longitudinal Causal Image Synthesis
Oct 23, 2024



Clinical decision-making relies heavily on causal reasoning and longitudinal analysis. For example, for a patient with Alzheimer's disease (AD), how will the brain grey matter atrophy in a year if intervened on the A-beta level in cerebrospinal fluid? The answer is fundamental to diagnosis and follow-up treatment. However, this kind of inquiry involves counterfactual medical images which can not be acquired by instrumental or correlation-based image synthesis models. Yet, such queries require counterfactual medical images, not obtainable through standard image synthesis models. Hence, a causal longitudinal image synthesis (CLIS) method, enabling the synthesis of such images, is highly valuable. However, building a CLIS model confronts three primary yet unmet challenges: mismatched dimensionality between high-dimensional images and low-dimensional tabular variables, inconsistent collection intervals of follow-up data, and inadequate causal modeling capability of existing causal graph methods for image data. In this paper, we established a tabular-visual causal graph (TVCG) for CLIS overcoming these challenges through a novel integration of generative imaging, continuous-time modeling, and structural causal models combined with a neural network. We train our CLIS based on the ADNI dataset and evaluate it on two other AD datasets, which illustrate the outstanding yet controllable quality of the synthesized images and the contributions of synthesized MRI to the characterization of AD progression, substantiating the reliability and utility in clinics.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Solving MaxSAT with Matrix Multiplication
Nov 01, 2023
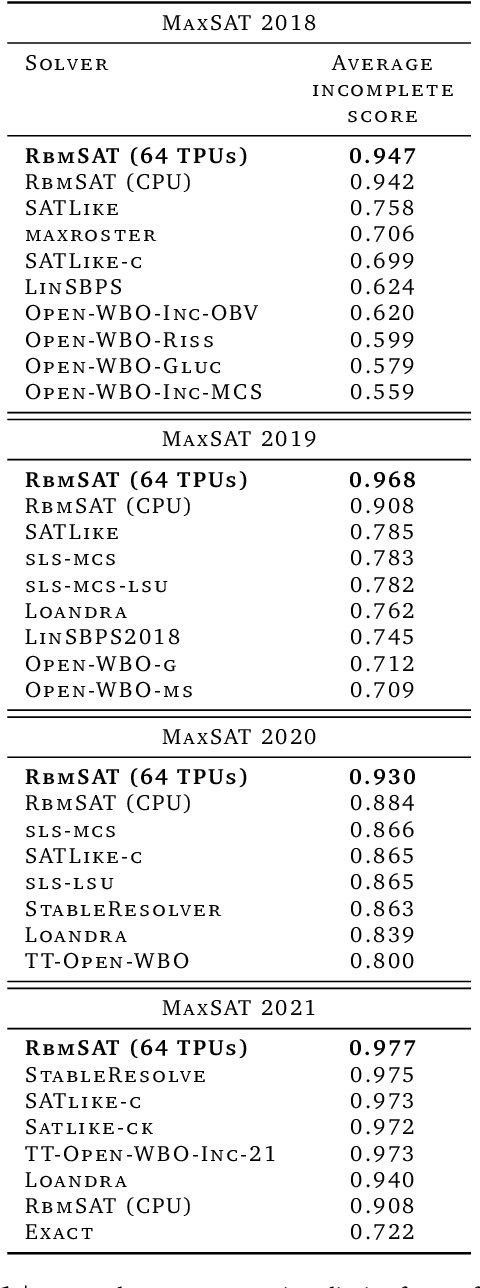


We propose an incomplete algorithm for Maximum Satisfiability (MaxSAT) specifically designed to run on neural network accelerators such as GPUs and TPUs. Given a MaxSAT problem instance in conjunctive normal form, our procedure constructs a Restricted Boltzmann Machine (RBM) with an equilibrium distribution wherein the probability of a Boolean assignment is exponential in the number of clauses it satisfies. Block Gibbs sampling is used to stochastically search the space of assignments with parallel Markov chains. Since matrix multiplication is the main computational primitive for block Gibbs sampling in an RBM, our approach leads to an elegantly simple algorithm (40 lines of JAX) well-suited for neural network accelerators. Theoretical results about RBMs guarantee that the required number of visible and hidden units of the RBM scale only linearly with the number of variables and constant-sized clauses in the MaxSAT instance, ensuring that the computational cost of a Gibbs step scales reasonably with the instance size. Search throughput can be increased by batching parallel chains within a single accelerator as well as by distributing them across multiple accelerators. As a further enhancement, a heuristic based on unit propagation running on CPU is periodically applied to the sampled assignments. Our approach, which we term RbmSAT, is a new design point in the algorithm-hardware co-design space for MaxSAT. We present timed results on a subset of problem instances from the annual MaxSAT Evaluation's Incomplete Unweighted Track for the years 2018 to 2021. When allotted the same running time and CPU compute budget (but no TPUs), RbmSAT outperforms other participating solvers on problems drawn from three out of the four years' competitions. Given the same running time on a TPU cluster for which RbmSAT is uniquely designed, it outperforms all solvers on problems drawn from all four years.
Large Language Models as Analogical Reasoners
Oct 07, 2023



Chain-of-thought (CoT) prompting for language models demonstrates impressive performance across reasoning tasks, but typically needs labeled exemplars of the reasoning process. In this work, we introduce a new prompting approach, Analogical Prompting, designed to automatically guide the reasoning process of large language models. Inspired by analogical reasoning, a cognitive process in which humans draw from relevant past experiences to tackle new problems, our approach prompts language models to self-generate relevant exemplars or knowledge in the context, before proceeding to solve the given problem. This method presents several advantages: it obviates the need for labeling or retrieving exemplars, offering generality and convenience; it can also tailor the generated exemplars and knowledge to each problem, offering adaptability. Experimental results show that our approach outperforms 0-shot CoT and manual few-shot CoT in a variety of reasoning tasks, including math problem solving in GSM8K and MATH, code generation in Codeforces, and other reasoning tasks in BIG-Bench.
Detecting the Anomalies in LiDAR Pointcloud
Jul 31, 2023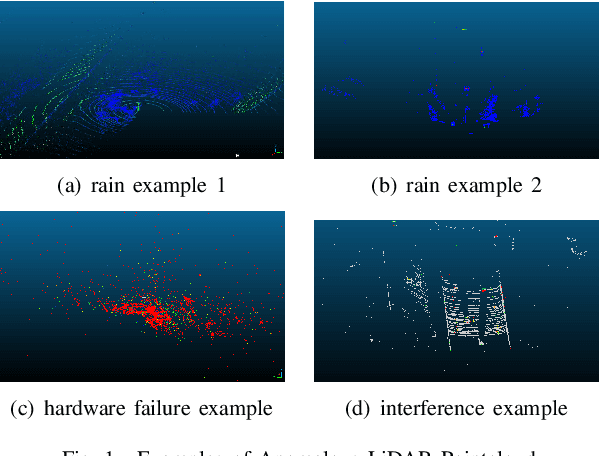
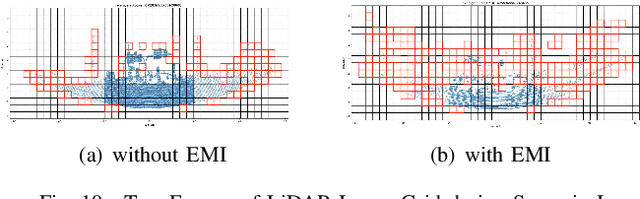

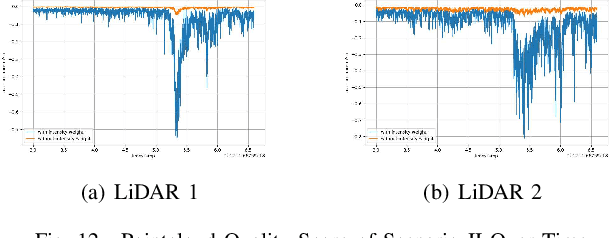
LiDAR sensors play an important role in the perception stack of modern autonomous driving systems. Adverse weather conditions such as rain, fog and dust, as well as some (occasional) LiDAR hardware fault may cause the LiDAR to produce pointcloud with abnormal patterns such as scattered noise points and uncommon intensity values. In this paper, we propose a novel approach to detect whether a LiDAR is generating anomalous pointcloud by analyzing the pointcloud characteristics. Specifically, we develop a pointcloud quality metric based on the LiDAR points' spatial and intensity distribution to characterize the noise level of the pointcloud, which relies on pure mathematical analysis and does not require any labeling or training as learning-based methods do. Therefore, the method is scalable and can be quickly deployed either online to improve the autonomy safety by monitoring anomalies in the LiDAR data or offline to perform in-depth study of the LiDAR behavior over large amount of data. The proposed approach is studied with extensive real public road data collected by LiDARs with different scanning mechanisms and laser spectrums, and is proven to be able to effectively handle various known and unknown sources of pointcloud anomaly.
Causal Image Synthesis of Brain MR in 3D
Mar 25, 2023



Clinical decision making requires counterfactual reasoning based on a factual medical image and thus necessitates causal image synthesis. To this end, we present a novel method for modeling the causality between demographic variables, clinical indices and brain MR images for Alzheimer's Diseases. Specifically, we leverage a structural causal model to depict the causality and a styled generator to synthesize the image. Furthermore, as a crucial step to reduce modeling complexity and make learning tractable, we propose the use of low dimensional latent feature representation of a high-dimensional 3D image, together with exogenous noise, to build causal relationship between the image and non image variables. We experiment the proposed method based on 1586 subjects and 3683 3D images and synthesize counterfactual brain MR images intervened on certain attributes, such as age, brain volume and cognitive test score. Quantitative metrics and qualitative evaluation of counterfactual images demonstrates the superiority of our generated images.