 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF-based CBCT Reconstruction needs Normalization and Initialization
Jun 24, 2025Cone Beam Computed Tomography (CBCT) is widely used in medical imaging. However, the limited number and intensity of X-ray projections make reconstruction an ill-posed problem with severe artifacts. NeRF-based methods have achieved great success in this task. However, they suffer from a local-global training mismatch between their two key components: the hash encoder and the neural network. Specifically, in each training step, only a subset of the hash encoder's parameters is used (local sparse), whereas all parameters in the neural network participate (global dense). Consequently, hash features generated in each step are highly misaligned, as they come from different subsets of the hash encoder. These misalignments from different training steps are then fed into the neural network, causing repeated inconsistent global updates in training, which leads to unstable training, slower convergence, and degraded reconstruction quality. Aiming to alleviate the impact of this local-global optimization mismatch, we introduce a Normalized Hash Encoder, which enhances feature consistency and mitigates the mismatch. Additionally, we propose a Mapping Consistency Initialization(MCI) strategy that initializes the neural network before training by leveraging the global mapping property from a well-trained model. The initialized neural network exhibits improved stability during early training, enabling faster convergence and enhanced reconstruction performance. Our method is simple yet effective, requiring only a few lines of code while substantially improving training efficiency on 128 CT cases collected from 4 different datasets, covering 7 distinct anatomical regions.
PELE scores: Pelvic X-ray Landmark Detection by Pelvis Extraction and Enhancement
May 07, 2023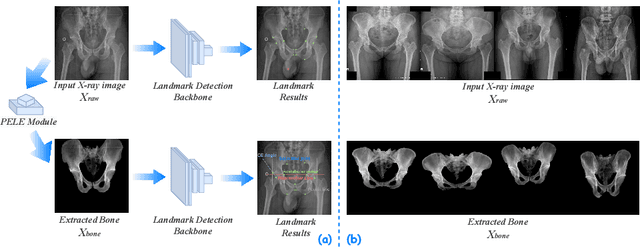

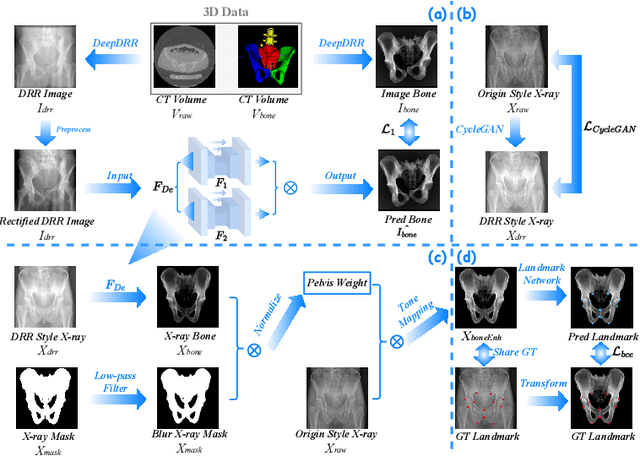

The pelvis, the lower part of the trunk, supports and balances the trunk. Landmark detection from a pelvic X-ray (PXR) facilitates downstream analysis and computer-assisted diagnosis and treatment of pelvic diseases. Although PXRs have the advantages of low radiation and reduced cost compared to computed tomography (CT) images, their 2D pelvis-tissue superposition of 3D structures confuses clinical decision-making. In this paper, we propose a PELvis Extraction (PELE) module that utilizes 3D prior anatomical knowledge in CT to guide and well isolate the pelvis from PXRs, thereby eliminating the influence of soft tissue. We conduct an extensive evaluation based on two public datasets and one private dataset, totaling 850 PXRs. The experimental results show that the proposed PELE module significantly improves the accuracy of PXRs landmark detection and achieves state-of-the-art performances in several benchmark metrics, thus better serving downstream tasks.
Stabilize, Decompose, and Denoise: Self-Supervised Fluoroscopy Denoising
Aug 30, 2022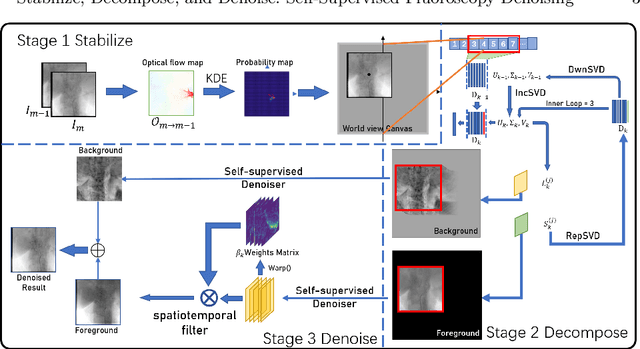


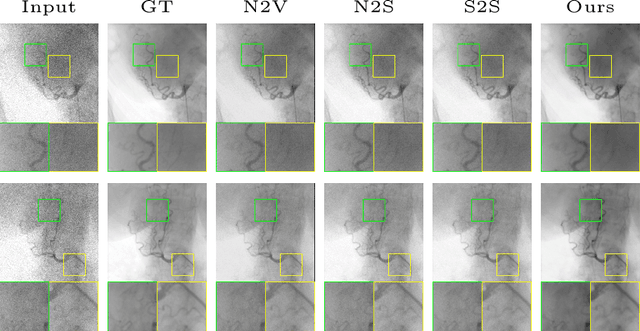
Fluoroscopy is an imaging technique that uses X-ray to obtain a real-time 2D video of the interior of a 3D object, helping surgeons to observe pathological structures and tissue functions especially during intervention. However, it suffers from heavy noise that mainly arises from the clinical use of a low dose X-ray, thereby necessitating the technology of fluoroscopy denoising. Such denoising is challenged by the relative motion between the object being imaged and the X-ray imaging system. We tackle this challenge by proposing a self-supervised, three-stage framework that exploits the domain knowledge of fluoroscopy imaging. (i) Stabilize: we first construct a dynamic panorama based on optical flow calculation to stabilize the non-stationary background induced by the motion of the X-ray detector. (ii) Decompose: we then propose a novel mask-based Robust Principle Component Analysis (RPCA) decomposition method to separate a video with detector motion into a low-rank background and a sparse foreground. Such a decomposition accommodates the reading habit of experts. (iii) Denoise: we finally denoise the background and foreground separately by a self-supervised learning strategy and fuse the denoised parts into the final output via a bilateral, spatiotemporal filter. To assess the effectiveness of our work, we curate a dedicated fluoroscopy dataset of 27 videos (1,568 frames) and corresponding ground truth. Our experiments demonstrate that it achieves significant improvements in terms of denoising and enhancement effects when compared with standard approaches. Finally, expert rating confirms this efficacy.
First image then video: A two-stage network for spatiotemporal video denoising
Jan 22, 2020



Video denoising is to remove noise from noise-corrupted data, thus recovering true signals via spatiotemporal processing. Existing approaches for spatiotemporal video denoising tend to suffer from motion blur artifacts, that is, the boundary of a moving object tends to appear blurry especially when the object undergoes a fast motion, causing optical flow calculation to break down. In this paper, we address this challenge by designing a first-image-then-video two-stage denoising neural network, consisting of an image denoising module for spatially reducing intra-frame noise followed by a regular spatiotemporal video denoising module. The intuition is simple yet powerful and effective: the first stage of image denoising effectively reduces the noise level and, therefore, allows the second stage of spatiotemporal denoising for better modeling and learning everywhere, including along the moving object boundaries. This two-stage network, when trained in an end-to-end fashion, yields the state-of-the-art performances on the video denoising benchmark Vimeo90K dataset in terms of both denoising quality and computation. It also enables an unsupervised approach that achieves comparable performance to existing supervised approaches.