 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilize, Decompose, and Denoise: Self-Supervised Fluoroscopy Denoising
Aug 30, 2022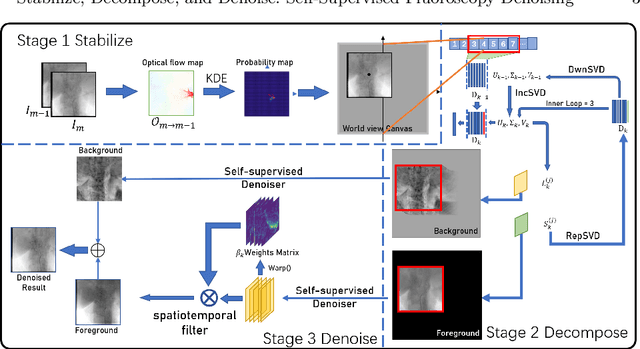


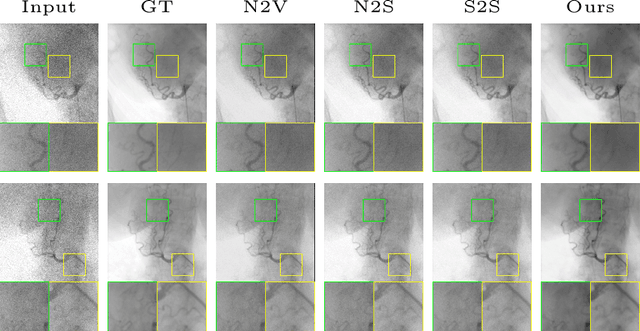
Fluoroscopy is an imaging technique that uses X-ray to obtain a real-time 2D video of the interior of a 3D object, helping surgeons to observe pathological structures and tissue functions especially during intervention. However, it suffers from heavy noise that mainly arises from the clinical use of a low dose X-ray, thereby necessitating the technology of fluoroscopy denoising. Such denoising is challenged by the relative motion between the object being imaged and the X-ray imaging system. We tackle this challenge by proposing a self-supervised, three-stage framework that exploits the domain knowledge of fluoroscopy imaging. (i) Stabilize: we first construct a dynamic panorama based on optical flow calculation to stabilize the non-stationary background induced by the motion of the X-ray detector. (ii) Decompose: we then propose a novel mask-based Robust Principle Component Analysis (RPCA) decomposition method to separate a video with detector motion into a low-rank background and a sparse foreground. Such a decomposition accommodates the reading habit of experts. (iii) Denoise: we finally denoise the background and foreground separately by a self-supervised learning strategy and fuse the denoised parts into the final output via a bilateral, spatiotemporal filter. To assess the effectiveness of our work, we curate a dedicated fluoroscopy dataset of 27 videos (1,568 frames) and corresponding ground truth. Our experiments demonstrate that it achieves significant improvements in terms of denoising and enhancement effects when compared with standard approaches. Finally, expert rating confirms this efficacy.
Rib Suppression in Digital Chest Tomosynthesis
Mar 05, 2022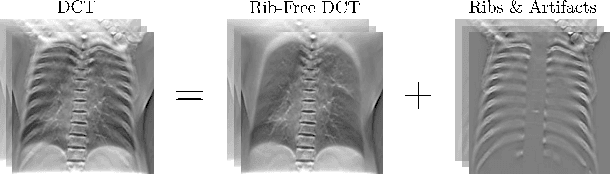
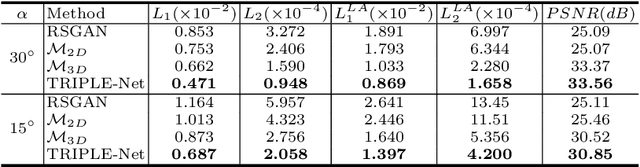
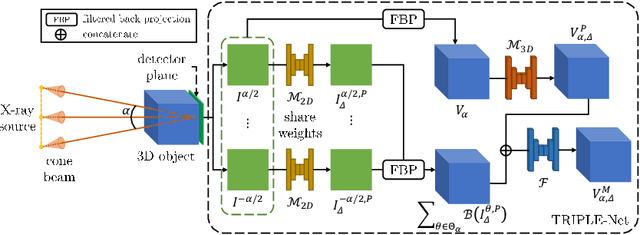
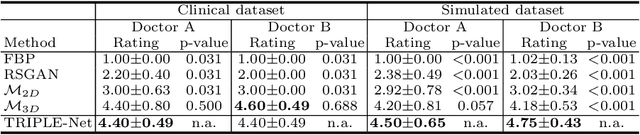
Digital chest tomosynthesis (DCT) is a technique to produce sectional 3D images of a human chest for pulmonary disease screening, with 2D X-ray projections taken within an extremely limited range of angles. However, under the limited angle scenario, DCT contains strong artifacts caused by the presence of ribs, jamming the imaging quality of the lung area. Recently, great progress has been achieved for rib suppression in a single X-ray image, to reveal a clearer lung texture. We firstly extend the rib suppression problem to the 3D case at the software level. We propose a $\textbf{T}$omosynthesis $\textbf{RI}$b Su$\textbf{P}$pression and $\textbf{L}$ung $\textbf{E}$nhancement $\textbf{Net}$work (TRIPLE-Net) to model the 3D rib component and provide a rib-free DCT. TRIPLE-Net takes the advantages from both 2D and 3D domains, which model the ribs in DCT with the exact FBP procedure and 3D depth information, respectively. The experiments on simulated datasets and clinical data have shown the effectiveness of TRIPLE-Net to preserve lung details as well as improve the imaging quality of pulmonary diseases. Finally, an expert user study confirms our findings.
GAN-based disentanglement learning for chest X-ray rib suppression
Oct 18, 2021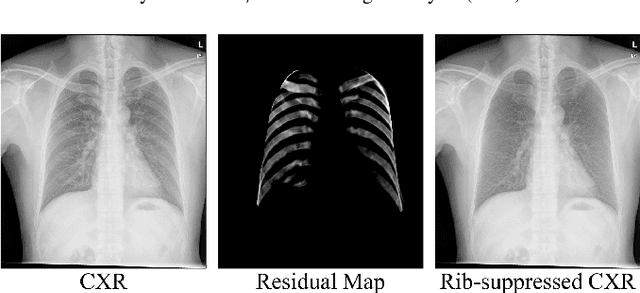


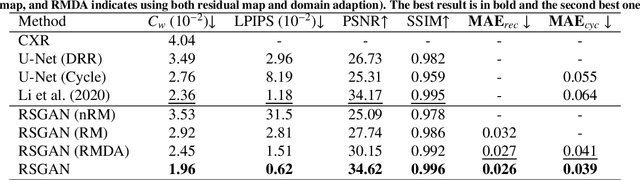
Clinical evidence has shown that rib-suppressed chest X-rays (CXRs) can improve the reliability of pulmonary disease diagnosis. However, previous approaches on generating rib-suppressed CXR face challenges in preserving details and eliminating rib residues. We hereby propose a GAN-based disentanglement learning framework called Rib Suppression GAN, or RSGAN, to perform rib suppression by utilizing the anatomical knowledge embedded in unpaired computed tomography (CT) images. In this approach, we employ a residual map to characterize the intensity difference between CXR and the corresponding rib-suppressed result. To predict the residual map in CXR domain, we disentangle the image into structure- and contrast-specific features and transfer the rib structural priors from digitally reconstructed radiographs (DRRs) computed by CT. Furthermore, we employ additional adaptive loss to suppress rib residue and preserve more details. We conduct extensive experiments based on 1,673 CT volumes, and four benchmarking CXR datasets, totaling over 120K images, to demonstrate that (i) our proposed RSGAN achieves superior image quality compared to the state-of-the-art rib suppression methods; (ii) combining CXR with our rib-suppressed result leads to better performance in lung disease classification and tuberculosis area detection.
Generalizable Limited-Angle CT Reconstruction via Sinogram Extrapolation
Mar 15, 2021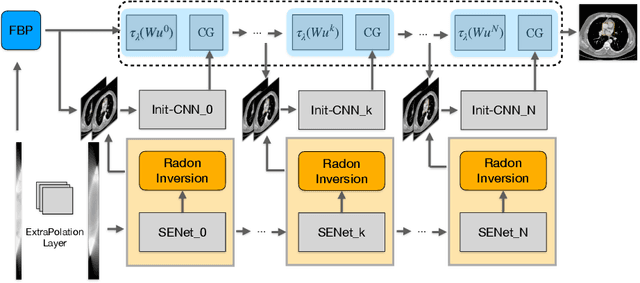


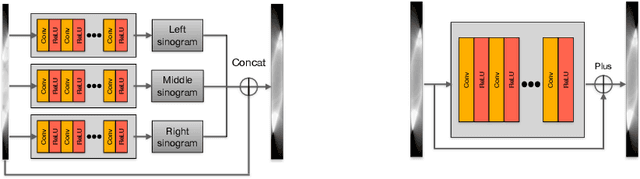
Computed tomography (CT) reconstruction from X-ray projections acquired within a limited angle range is challenging, especially when the angle range is extremely small. Both analytical and iterative models need more projections for effective modeling. Deep learning methods have gained prevalence due to their excellent reconstruction performances, but such success is mainly limited within the same dataset and does not generalize across datasets with different distributions. Hereby we propose ExtraPolationNetwork for limited-angle CT reconstruction via the introduction of a sinogram extrapolation module, which is theoretically justified. The module complements extra sinogram information and boots model generalizability. Extensive experimental results show that our reconstruction model achieves state-of-the-art performance on NIH-AAPM dataset, similar to existing approaches. More importantly, we show that using such a sinogram extrapolation module significantly improves the generalization capability of the model on unseen datasets (e.g., COVID-19 and LIDC datasets) when compared to existing approaches.
U-DuDoNet: Unpaired dual-domain network for CT metal artifact reduction
Mar 08, 2021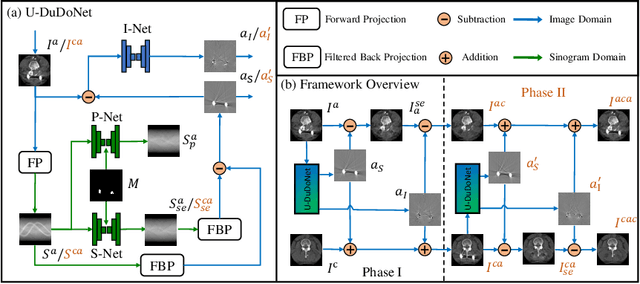
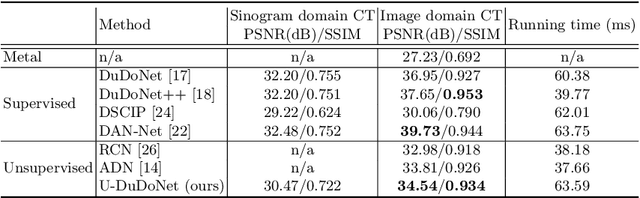
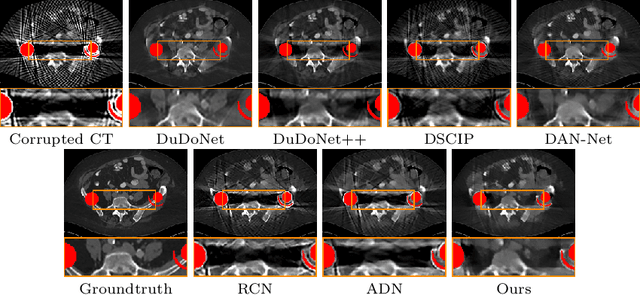

Recently, both supervised and unsupervised deep learning methods have been widely applied on the CT metal artifact reduction (MAR) task. Supervised methods such as Dual Domain Network (Du-DoNet) work well on simulation data; however, their performance on clinical data is limited due to domain gap. Unsupervised methods are more generalized, but do not eliminate artifacts completely through the sole processing on the image domain. To combine the advantages of both MAR methods, we propose an unpaired dual-domain network (U-DuDoNet) trained using unpaired data. Unlike the artifact disentanglement network (ADN) that utilizes multiple encoders and decoders for disentangling content from artifact, our U-DuDoNet directly models the artifact generation process through additions in both sinogram and image domains, which is theoretically justified by an additive property associated with metal artifact. Our design includes a self-learned sinogram prior net, which provides guidance for restoring the information in the sinogram domain, and cyclic constraints for artifact reduction and addition on unpaired data. Extensive experiments on simulation data and clinical images demonstrate that our novel framework outperforms the state-of-the-art unpaired approaches.
Joint Unsupervised Learning for the Vertebra Segmentation, Artifact Reduction and Modality Translation of CBCT Images
Jan 18, 2020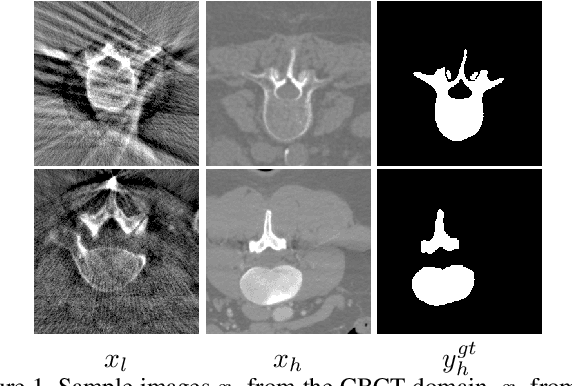

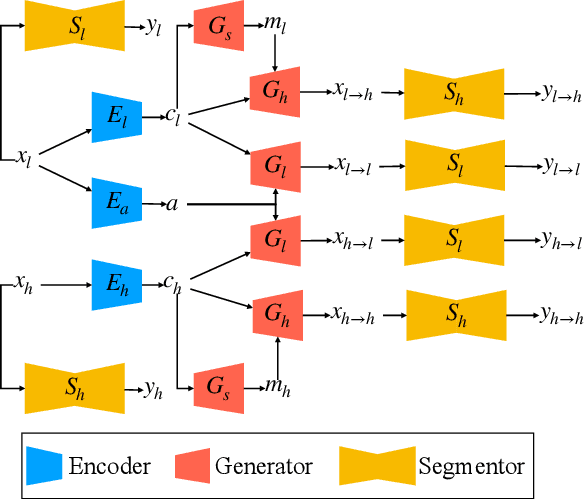

We investigate the unsupervised learning of the vertebra segmentation, artifact reduction and modality translation of CBCT images. To this end, we formulate this problem under a unified framework that jointly addresses these three tasks and intensively leverages the knowledge sharing. The unsupervised learning of this framework is enabled by 1) a novel shape-aware artifact disentanglement network that supports different forms of image synthesis and vertebra segmentation and 2) a deliberate fusion of knowledge from an independent CT dataset. Specifically, the proposed framework takes a random pair of CBCT and CT images as the input, and manipulates the synthesis and segmentation via different combinations of the decodings of the disentangled latent codes. Then, by discovering various forms of consistencies between the synthesized images and segmented , the learning is achieved via self-learning from the given CBCT and CT images obviating the need for the paired (i.e., anatomically identical) groundtruth data. Extensive experiments on clinical CBCT and CT datasets show that the proposed approach performs significantly better than other state-of-the-art unsupervised methods trained independently for each task and, remarkably, the proposed approach achieves a dice coefficient of 0.879 for unsupervised CBCT vertebra segmentation.
DuDoNet++: Encoding mask projection to reduce CT metal artifacts
Jan 18, 2020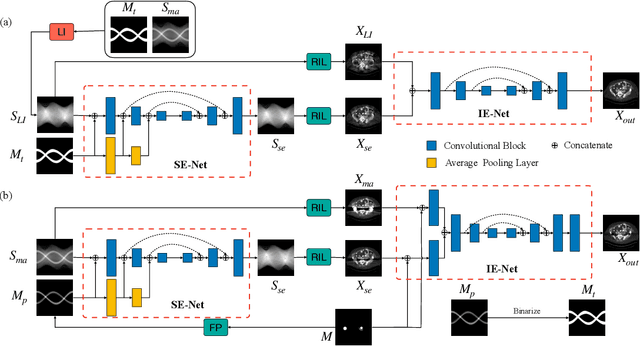

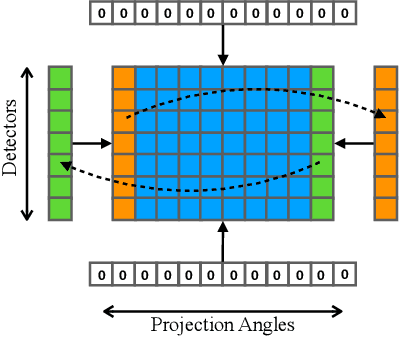

CT metal artifact reduction (MAR) is a notoriously challenging task because the artifacts are structured and non-local in the image domain. However, they are inherently local in the sinogram domain. DuDoNet is the state-of-the-art MAR algorithm which exploits the latter characteristic by learning to reduce artifacts in the sinogram and image domain jointly. By design, DuDoNet treats the metal-affected regions in sinogram as missing and replaces them with the surrogate data generated by a neural network. Since fine-grained details within the metal-affected regions are completely ignored, the artifact-reduced CT images by DuDoNet tend to be over-smoothed and distorted. In this work, we investigate the issue by theoretical derivation. We propose to address the problem by (1) retaining the metal-affected regions in sinogram and (2) replacing the binarized metal trace with the metal mask projection such that the geometry information of metal implants is encoded. Extensive experiments on simulated datasets and expert evaluations on clinical images demonstrate that our network called DuDoNet++ yields anatomically more precise artifact-reduced images than DuDoNet, especially when the metallic objects are large.