 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Unsupervised Learning for the Vertebra Segmentation, Artifact Reduction and Modality Translation of CBCT Images
Paper and Code
Jan 18, 2020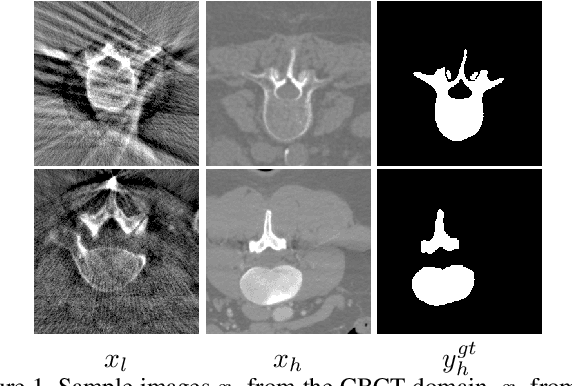

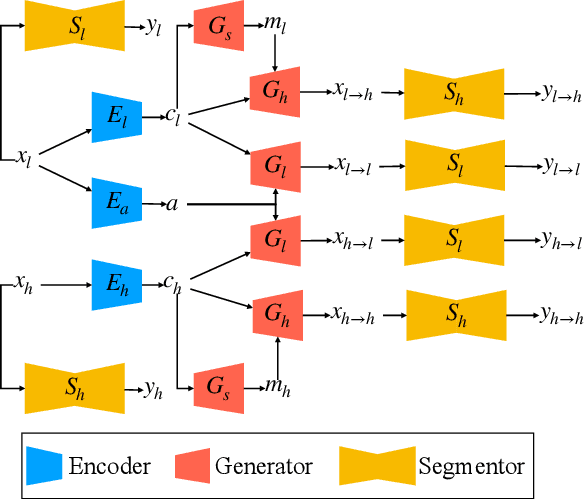

We investigate the unsupervised learning of the vertebra segmentation, artifact reduction and modality translation of CBCT images. To this end, we formulate this problem under a unified framework that jointly addresses these three tasks and intensively leverages the knowledge sharing. The unsupervised learning of this framework is enabled by 1) a novel shape-aware artifact disentanglement network that supports different forms of image synthesis and vertebra segmentation and 2) a deliberate fusion of knowledge from an independent CT dataset. Specifically, the proposed framework takes a random pair of CBCT and CT images as the input, and manipulates the synthesis and segmentation via different combinations of the decodings of the disentangled latent codes. Then, by discovering various forms of consistencies between the synthesized images and segmented , the learning is achieved via self-learning from the given CBCT and CT images obviating the need for the paired (i.e., anatomically identical) groundtruth data. Extensive experiments on clinical CBCT and CT datasets show that the proposed approach performs significantly better than other state-of-the-art unsupervised methods trained independently for each task and, remarkably, the proposed approach achieves a dice coefficient of 0.879 for unsupervised CBCT vertebra segmentation.