 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIonopedia: an LLM agent orchestrating multimodal learning for ionic liquid discovery
Nov 14, 2025The discovery of novel Ionic Liquids (ILs) is hindered by critical challenges in property prediction, including limited data, poor model accuracy, and fragmented workflows. Leveraging the power of Large Language Models (LLMs), we introduce AIonopedia, to the best of our knowledge, the first LLM agent for IL discovery. Powered by an LLM-augmented multimodal domain foundation model for ILs, AIonopedia enables accurate property predictions and incorporates a hierarchical search architecture for molecular screening and design. Trained and evaluated on a newly curated and comprehensive IL dataset, our model delivers superior performance. Complementing these results, evaluations on literature-reported systems indicate that the agent can perform effective IL modification. Moving beyond offline tests, the practical efficacy was further confirmed through real-world wet-lab validation, in which the agent demonstrated exceptional generalization capabilities on challenging out-of-distribution tasks, underscoring its ability to accelerate real-world IL discovery.
PELE scores: Pelvic X-ray Landmark Detection by Pelvis Extraction and Enhancement
May 07, 2023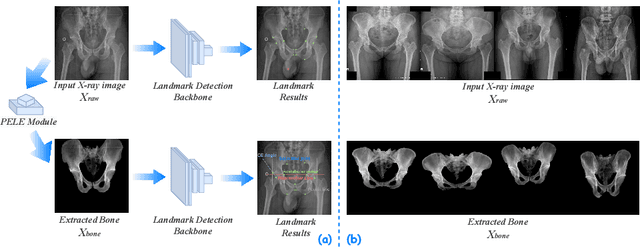

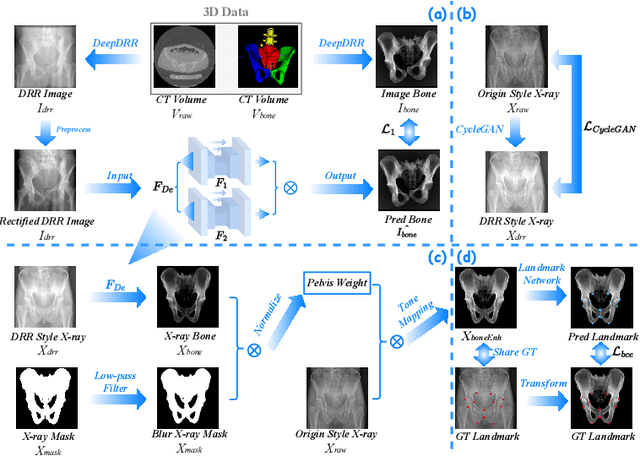

The pelvis, the lower part of the trunk, supports and balances the trunk. Landmark detection from a pelvic X-ray (PXR) facilitates downstream analysis and computer-assisted diagnosis and treatment of pelvic diseases. Although PXRs have the advantages of low radiation and reduced cost compared to computed tomography (CT) images, their 2D pelvis-tissue superposition of 3D structures confuses clinical decision-making. In this paper, we propose a PELvis Extraction (PELE) module that utilizes 3D prior anatomical knowledge in CT to guide and well isolate the pelvis from PXRs, thereby eliminating the influence of soft tissue. We conduct an extensive evaluation based on two public datasets and one private dataset, totaling 850 PXRs. The experimental results show that the proposed PELE module significantly improves the accuracy of PXRs landmark detection and achieves state-of-the-art performances in several benchmark metrics, thus better serving downstream tasks.
Stabilize, Decompose, and Denoise: Self-Supervised Fluoroscopy Denoising
Aug 30, 2022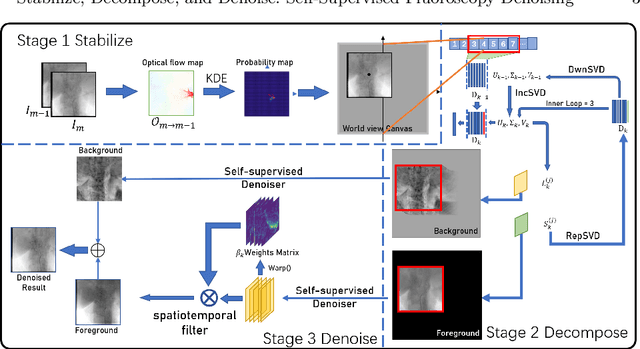


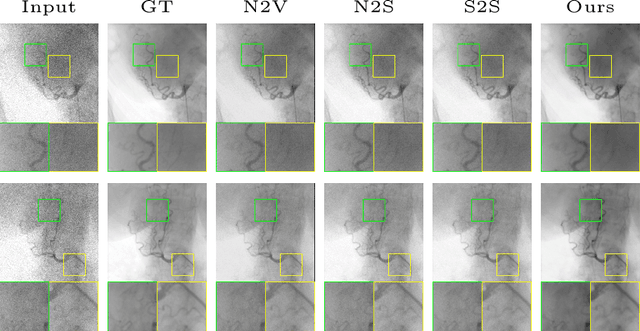
Fluoroscopy is an imaging technique that uses X-ray to obtain a real-time 2D video of the interior of a 3D object, helping surgeons to observe pathological structures and tissue functions especially during intervention. However, it suffers from heavy noise that mainly arises from the clinical use of a low dose X-ray, thereby necessitating the technology of fluoroscopy denoising. Such denoising is challenged by the relative motion between the object being imaged and the X-ray imaging system. We tackle this challenge by proposing a self-supervised, three-stage framework that exploits the domain knowledge of fluoroscopy imaging. (i) Stabilize: we first construct a dynamic panorama based on optical flow calculation to stabilize the non-stationary background induced by the motion of the X-ray detector. (ii) Decompose: we then propose a novel mask-based Robust Principle Component Analysis (RPCA) decomposition method to separate a video with detector motion into a low-rank background and a sparse foreground. Such a decomposition accommodates the reading habit of experts. (iii) Denoise: we finally denoise the background and foreground separately by a self-supervised learning strategy and fuse the denoised parts into the final output via a bilateral, spatiotemporal filter. To assess the effectiveness of our work, we curate a dedicated fluoroscopy dataset of 27 videos (1,568 frames) and corresponding ground truth. Our experiments demonstrate that it achieves significant improvements in terms of denoising and enhancement effects when compared with standard approaches. Finally, expert rating confirms this efficacy.
Rib Suppression in Digital Chest Tomosynthesis
Mar 05, 2022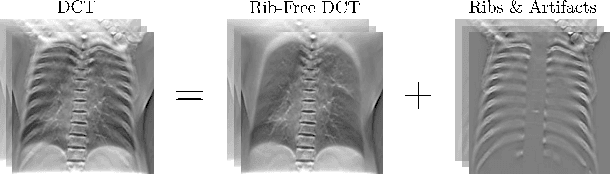
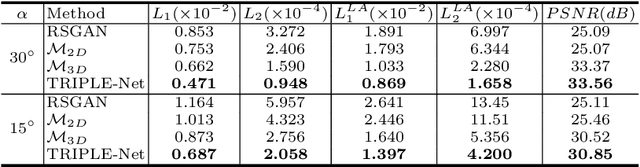
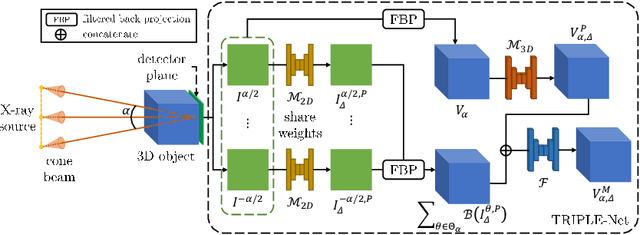
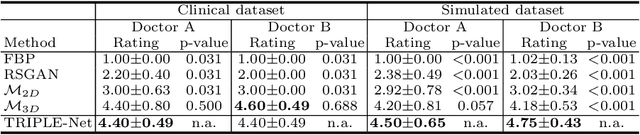
Digital chest tomosynthesis (DCT) is a technique to produce sectional 3D images of a human chest for pulmonary disease screening, with 2D X-ray projections taken within an extremely limited range of angles. However, under the limited angle scenario, DCT contains strong artifacts caused by the presence of ribs, jamming the imaging quality of the lung area. Recently, great progress has been achieved for rib suppression in a single X-ray image, to reveal a clearer lung texture. We firstly extend the rib suppression problem to the 3D case at the software level. We propose a $\textbf{T}$omosynthesis $\textbf{RI}$b Su$\textbf{P}$pression and $\textbf{L}$ung $\textbf{E}$nhancement $\textbf{Net}$work (TRIPLE-Net) to model the 3D rib component and provide a rib-free DCT. TRIPLE-Net takes the advantages from both 2D and 3D domains, which model the ribs in DCT with the exact FBP procedure and 3D depth information, respectively. The experiments on simulated datasets and clinical data have shown the effectiveness of TRIPLE-Net to preserve lung details as well as improve the imaging quality of pulmonary diseases. Finally, an expert user study confirms our findings.
Relative distance matters for one-shot landmark detection
Mar 04, 2022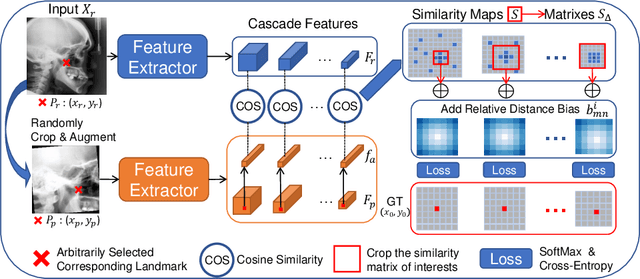
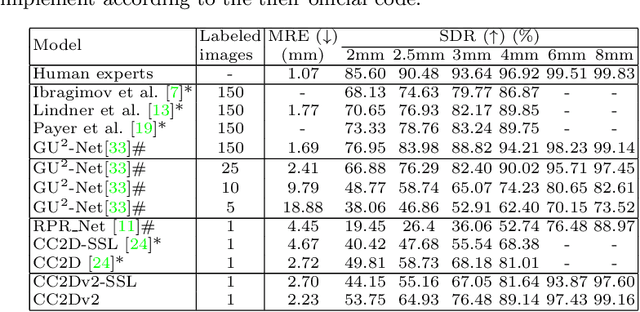
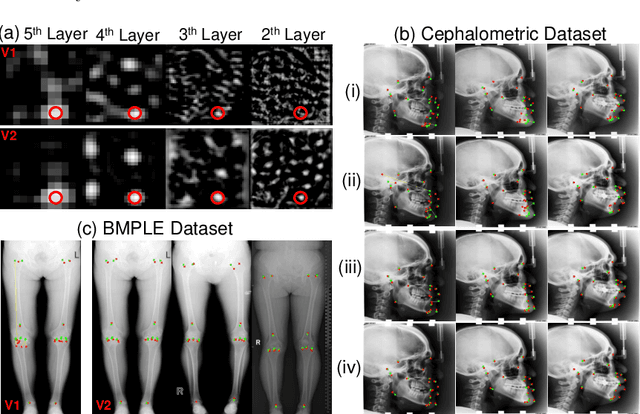
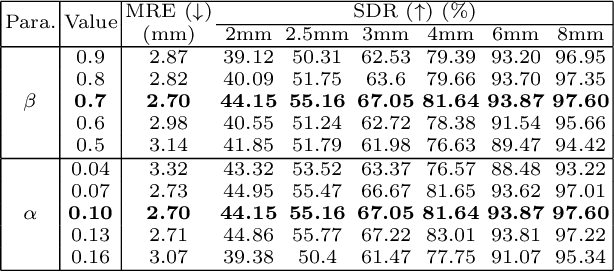
Contrastive learning based methods such as cascade comparing to detect (CC2D) have shown great potential for one-shot medical landmark detection. However, the important cue of relative distance between landmarks is ignored in CC2D. In this paper, we upgrade CC2D to version II by incorporating a simple-yet-effective relative distance bias in the training stage, which is theoretically proved to encourage the encoder to project the relatively distant landmarks to the embeddings with low similarities. As consequence, CC2Dv2 is less possible to detect a wrong point far from the correct landmark. Furthermore, we present an open-source, landmark-labeled dataset for the measurement of biomechanical parameters of the lower extremity to alleviate the burden of orthopedic surgeons. The effectiveness of CC2Dv2 is evaluated on the public dataset from the ISBI 2015 Grand-Challenge of cephalometric radiographs and our new dataset, which greatly outperforms the state-of-the-art one-shot landmark detection approaches.
Conditional Uncorrelation and Efficient Non-approximate Subset Selection in Sparse Regression
Sep 08, 2020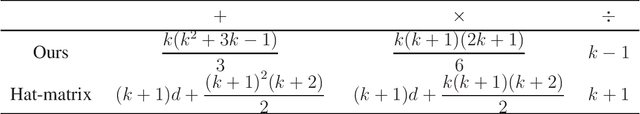
Given $m$ $d$-dimensional responsors and $n$ $d$-dimensional predictors, sparse regression finds at most $k$ predictors for each responsor for linearly approximation, $1\leq k \leq d-1$. The key problem in sparse regression is subset selection, which usually suffers from the high computational cost. Here we consider sparse regression from the view of correlation, and propose the formula of conditional uncorrelation. Then an efficient non-approximate method of subset selection is proposed in which we do not need to calculate any linear coefficients for the candidate predictors. By the proposed method, the computational complexity is reduced from $O(\frac{1}{2}{k^3}+kd)$ to $O(\frac{1}{3}{k^3})$ for each candidate subset in sparse regression. Because the dimension $d$ is generally the number of observations or experiments and large enough, the proposed method can significantly improve the efficiency of sparse regression.
Associations among Image Assessments as Cost Functions in Linear Decomposition: MSE, SSIM, and Correlation Coefficient
Aug 04, 2017The traditional methods of image assessment, such as mean squared error (MSE), signal-to-noise ratio (SNR), and Peak signal-to-noise ratio (PSNR), are all based on the absolute error of images. Pearson's inner-product correlation coefficient (PCC) is also usually used to measure the similarity between images. Structural similarity (SSIM) index is another important measurement which has been shown to be more effective in the human vision system (HVS). Although there are many essential differences among these image assessments, some important associations among them as cost functions in linear decomposition are discussed in this paper. Firstly, the selected bases from a basis set for a target vector are the same in the linear decomposition schemes with different cost functions MSE, SSIM, and PCC. Moreover, for a target vector, the ratio of the corresponding affine parameters in the MSE-based linear decomposition scheme and the SSIM-based scheme is a constant, which is just the value of PCC between the target vector and its estimated vector.