 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Uncorrelation and Efficient Non-approximate Subset Selection in Sparse Regression
Paper and Code
Sep 08, 2020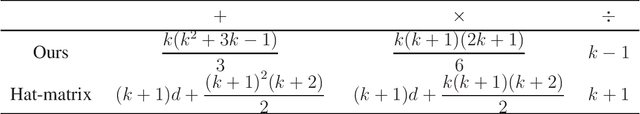
Given $m$ $d$-dimensional responsors and $n$ $d$-dimensional predictors, sparse regression finds at most $k$ predictors for each responsor for linearly approximation, $1\leq k \leq d-1$. The key problem in sparse regression is subset selection, which usually suffers from the high computational cost. Here we consider sparse regression from the view of correlation, and propose the formula of conditional uncorrelation. Then an efficient non-approximate method of subset selection is proposed in which we do not need to calculate any linear coefficients for the candidate predictors. By the proposed method, the computational complexity is reduced from $O(\frac{1}{2}{k^3}+kd)$ to $O(\frac{1}{3}{k^3})$ for each candidate subset in sparse regression. Because the dimension $d$ is generally the number of observations or experiments and large enough, the proposed method can significantly improve the efficiency of sparse regression.