 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual-Tube-Based Cooperative Transport Control for Multi-UAV Systems in Constrained Environments
Feb 05, 2026This paper proposes a novel control framework for cooperative transportation of cable-suspended loads by multiple unmanned aerial vehicles (UAVs) operating in constrained environments. Leveraging virtual tube theory and principles from dissipative systems theory, the framework facilitates efficient multi-UAV collaboration for navigating obstacle-rich areas. The proposed framework offers several key advantages. (1) It achieves tension distribution and coordinated transportation within the UAV-cable-load system with low computational overhead, dynamically adapting UAV configurations based on obstacle layouts to facilitate efficient navigation. (2) By integrating dissipative systems theory, the framework ensures high stability and robustness, essential for complex multi-UAV operations. The effectiveness of the proposed approach is validated through extensive simulations, demonstrating its scalability for large-scale multi-UAV systems. Furthermore, the method is experimentally validated in outdoor scenarios, showcasing its practical feasibility and robustness under real-world conditions.
MSACL: Multi-Step Actor-Critic Learning with Lyapunov Certificates for Exponentially Stabilizing Control
Dec 31, 2025Achieving provable stability in model-free reinforcement learning (RL) remains a challenge, particularly in balancing exploration with rigorous safety. This article introduces MSACL, a framework that integrates exponential stability theory with maximum entropy RL through multi-step Lyapunov certificate learning. Unlike methods relying on complex reward engineering, MSACL utilizes off-policy multi-step data to learn Lyapunov certificates satisfying theoretical stability conditions. By introducing Exponential Stability Labels (ESL) and a $λ$-weighted aggregation mechanism, the framework effectively balances the bias-variance trade-off in multi-step learning. Policy optimization is guided by a stability-aware advantage function, ensuring the learned policy promotes rapid Lyapunov descent. We evaluate MSACL across six benchmarks, including stabilization and nonlinear tracking tasks, demonstrating its superiority over state-of-the-art Lyapunov-based RL algorithms. MSACL achieves exponential stability and rapid convergence under simple rewards, while exhibiting significant robustness to uncertainties and generalization to unseen trajectories. Sensitivity analysis establishes the multi-step horizon $n=20$ as a robust default across diverse systems. By linking Lyapunov theory with off-policy actor-critic frameworks, MSACL provides a foundation for verifiably safe learning-based control. Source code and benchmark environments will be made publicly available.
RflyUT-Sim: A Simulation Platform for Development and Testing of Complex Low-Altitude Traffic Control
Dec 30, 2025Significant challenges are posed by simulation and testing in the field of low-altitude unmanned aerial vehicle (UAV) traffic due to the high costs associated with large-scale UAV testing and the complexity of establishing low-altitude traffic test scenarios. Stringent safety requirements make high fidelity one of the key metrics for simulation platforms. Despite advancements in simulation platforms for low-altitude UAVs, there is still a shortage of platforms that feature rich traffic scenarios, high-precision UAV and scenario simulators, and comprehensive testing capabilities for low-altitude traffic. Therefore, this paper introduces an integrated high-fidelity simulation platform for low-altitude UAV traffic. This platform simulates all components of the UAV traffic network, including the control system, the traffic management system, the UAV system, the communication network , the anomaly and fault modules, etc. Furthermore, it integrates RflySim/AirSim and Unreal Engine 5 to develop full-state models of UAVs and 3D maps that model the real world using the oblique photogrammetry technique. Additionally, the platform offers a wide range of interfaces, and all models and scenarios can be customized with a high degree of flexibility. The platform's source code has been released, making it easier to conduct research related to low-altitude traffic.
Self-Organizing Aerial Swarm Robotics for Resilient Load Transportation : A Table-Mechanics-Inspired Approach
Sep 03, 2025In comparison with existing approaches, which struggle with scalability, communication dependency, and robustness against dynamic failures, cooperative aerial transportation via robot swarms holds transformative potential for logistics and disaster response. Here, we present a physics-inspired cooperative transportation approach for flying robot swarms that imitates the dissipative mechanics of table-leg load distribution. By developing a decentralized dissipative force model, our approach enables autonomous formation stabilization and adaptive load allocation without the requirement of explicit communication. Based on local neighbor robots and the suspended payload, each robot dynamically adjusts its position. This is similar to energy-dissipating table leg reactions. The stability of the resultant control system is rigorously proved. Simulations demonstrate that the tracking errors of the proposed approach are 20%, 68%, 55.5%, and 21.9% of existing approaches under the cases of capability variation, cable uncertainty, limited vision, and payload variation, respectively. In real-world experiments with six flying robots, the cooperative aerial transportation system achieved a 94% success rate under single-robot failure, disconnection events, 25% payload variation, and 40% cable length uncertainty, demonstrating strong robustness under outdoor winds up to Beaufort scale 4. Overall, this physics-inspired approach bridges swarm intelligence and mechanical stability principles, offering a scalable framework for heterogeneous aerial systems to collectively handle complex transportation tasks in communication-constrained environments.
An Efficient Real-Time Planning Method for Swarm Robotics Based on an Optimal Virtual Tube
May 02, 2025Swarm robotics navigating through unknown obstacle environments is an emerging research area that faces challenges. Performing tasks in such environments requires swarms to achieve autonomous localization, perception, decision-making, control, and planning. The limited computational resources of onboard platforms present significant challenges for planning and control. Reactive planners offer low computational demands and high re-planning frequencies but lack predictive capabilities, often resulting in local minima. Long-horizon planners, on the other hand, can perform multi-step predictions to reduce deadlocks but cost much computation, leading to lower re-planning frequencies. This paper proposes a real-time optimal virtual tube planning method for swarm robotics in unknown environments, which generates approximate solutions for optimal trajectories through affine functions. As a result, the computational complexity of approximate solutions is $O(n_t)$, where $n_t$ is the number of parameters in the trajectory, thereby significantly reducing the overall computational burden. By integrating reactive methods, the proposed method enables low-computation, safe swarm motion in unknown environments. The effectiveness of the proposed method is validated through several simulations and experiments.
Navigating Robot Swarm Through a Virtual Tube with Flow-Adaptive Distribution Control
Jan 21, 2025



With the rapid development of robot swarm technology and its diverse applications, navigating robot swarms through complex environments has emerged as a critical research direction. To ensure safe navigation and avoid potential collisions with obstacles, the concept of virtual tubes has been introduced to define safe and navigable regions. However, current control methods in virtual tubes face the congestion issues, particularly in narrow virtual tubes with low throughput. To address these challenges, we first originally introduce the concepts of virtual tube area and flow capacity, and develop an new evolution model for the spatial density function. Next, we propose a novel control method that combines a modified artificial potential field (APF) for swarm navigation and density feedback control for distribution regulation, under which a saturated velocity command is designed. Then, we generate a global velocity field that not only ensures collision-free navigation through the virtual tube, but also achieves locally input-to-state stability (LISS) for density tracking errors, both of which are rigorously proven. Finally, numerical simulations and realistic applications validate the effectiveness and advantages of the proposed method in managing robot swarms within narrow virtual tubes.
A Degree of Flowability for Virtual Tubes
Oct 29, 2024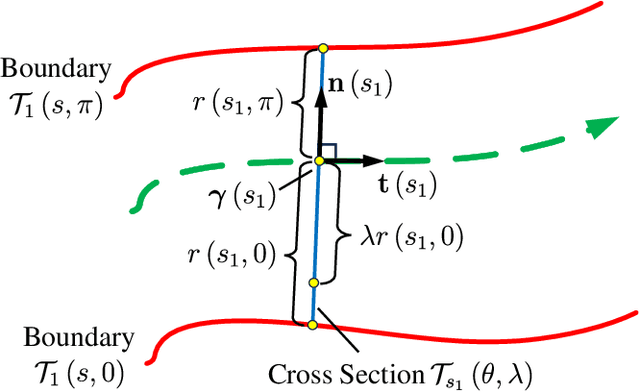
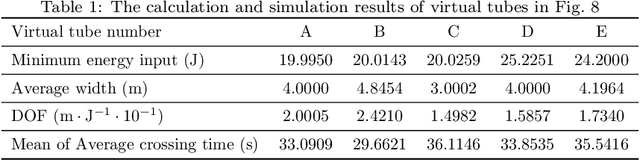
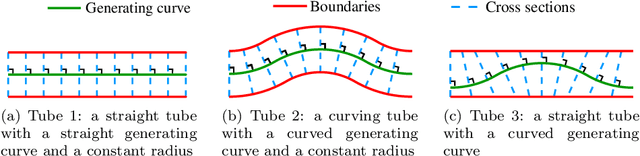
With the rapid development of robotics swarm technology, there are more tasks that require the swarm to pass through complicate environments safely and efficiently. Virtual tube technology is a novel way to achieve this goal. Virtual tubes are free spaces connecting two places that provide safety boundaries and direction of motion for swarm robotics. How to determine the design quality of a virtual tube is a fundamental problem. For such a purpose, this paper presents a degree of flowability (DOF) for two-dimensional virtual tubes according to a minimum energy principle. After that, methods to calculate DOF are proposed with a feasibility analysis. Simulations of swarm robotics in different kinds of two-dimensional virtual tubes are performed to demonstrate the effectiveness of the proposed method of calculating DOF.
HySparK: Hybrid Sparse Masking for Large Scale Medical Image Pre-Training
Aug 11, 2024



The generative self-supervised learning strategy exhibits remarkable learning representational capabilities. However, there is limited attention to end-to-end pre-training methods based on a hybrid architecture of CNN and Transformer, which can learn strong local and global representations simultaneously. To address this issue, we propose a generative pre-training strategy called Hybrid Sparse masKing (HySparK) based on masked image modeling and apply it to large-scale pre-training on medical images. First, we perform a bottom-up 3D hybrid masking strategy on the encoder to keep consistency masking. Then we utilize sparse convolution for the top CNNs and encode unmasked patches for the bottom vision Transformers. Second, we employ a simple hierarchical decoder with skip-connections to achieve dense multi-scale feature reconstruction. Third, we implement our pre-training method on a collection of multiple large-scale 3D medical imaging datasets. Extensive experiments indicate that our proposed pre-training strategy demonstrates robust transfer-ability in supervised downstream tasks and sheds light on HySparK's promising prospects. The code is available at https://github.com/FengheTan9/HySparK
Tube-RRT*: Efficient Homotopic Path Planning for Swarm Robotics Passing-Through Large-Scale Obstacle Environments
Apr 14, 2024



Recently, the concept of optimal virtual tube has emerged as a novel solution to the challenging task of navigating obstacle-dense environments for swarm robotics, offering a wide ranging of applications. However, it lacks an efficient homotopic path planning method in obstacle-dense environments. This paper introduces Tube-RRT*, an innovative homotopic path planning method that builds upon and improves the Rapidly-exploring Random Tree (RRT) algorithm. Tube-RRT* is specifically designed to generate homotopic paths for the trajectories in the virtual tube, strategically considering opening volume and tube length to mitigate swarm congestion and ensure agile navigation. Through comprehensive comparative simulations conducted within complex, large-scale obstacle environments, we demonstrate the effectiveness of Tube-RRT*.
High-Speed Interception Multicopter Control by Image-based Visual Servoing
Apr 12, 2024
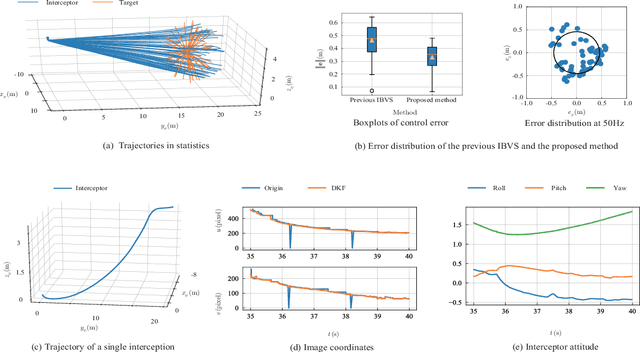
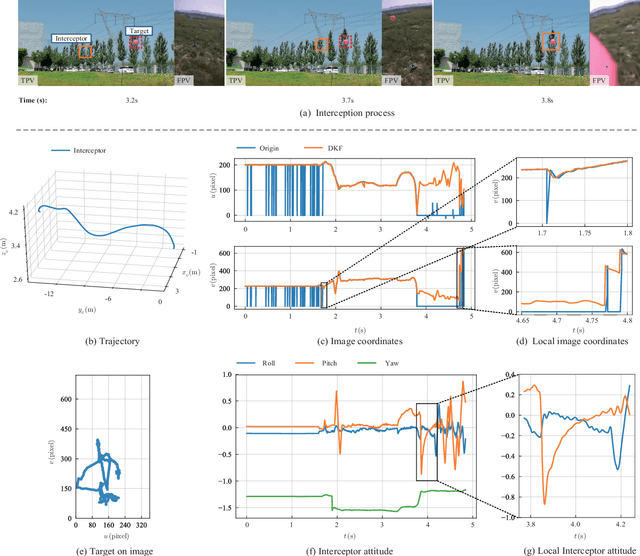
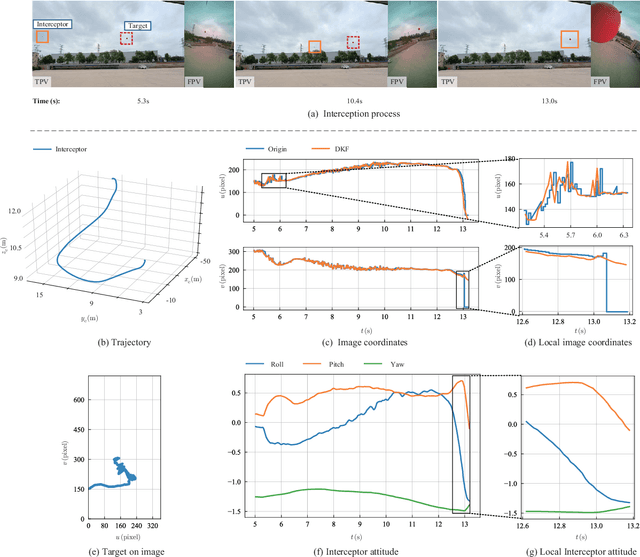
In recent years, reports of illegal drones threatening public safety have increased. For the invasion of fully autonomous drones, traditional methods such as radio frequency interference and GPS shielding may fail. This paper proposes a scheme that uses an autonomous multicopter with a strapdown camera to intercept a maneuvering intruder UAV. The interceptor multicopter can autonomously detect and intercept intruders moving at high speed in the air. The strapdown camera avoids the complex mechanical structure of the electro-optical pod, making the interceptor multicopter compact. However, the coupling of the camera and multicopter motion makes interception tasks difficult. To solve this problem, an Image-Based Visual Servoing (IBVS) controller is proposed to make the interception fast and accurate. Then, in response to the time delay of sensor imaging and image processing relative to attitude changes in high-speed scenarios, a Delayed Kalman Filter (DKF) observer is generalized to predict the current image position and increase the update frequency. Finally, Hardware-in-the-Loop (HITL) simulations and outdoor flight experiments verify that this method has a high interception accuracy and success rate. In the flight experiments, a high-speed interception is achieved with a terminal speed of 20 m/s.