 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
Structure-Accurate Medical Image Translation based on Dynamic Frequency Balance and Knowledge Guidance
Apr 13, 2025



Multimodal medical images play a crucial role in the precise and comprehensive clinical diagnosis. Diffusion model is a powerful strategy to synthesize the required medical images. However, existing approaches still suffer from the problem of anatomical structure distortion due to the overfitting of high-frequency information and the weakening of low-frequency information. Thus, we propose a novel method based on dynamic frequency balance and knowledge guidance. Specifically, we first extract the low-frequency and high-frequency components by decomposing the critical features of the model using wavelet transform. Then, a dynamic frequency balance module is designed to adaptively adjust frequency for enhancing global low-frequency features and effective high-frequency details as well as suppressing high-frequency noise. To further overcome the challenges posed by the large differences between different medical modalities, we construct a knowledge-guided mechanism that fuses the prior clinical knowledge from a visual language model with visual features, to facilitate the generation of accurate anatomical structures. Experimental evaluations on multiple datasets show the proposed method achieves significant improvements in qualitative and quantitative assessments, verifying its effectiveness and superiority.
Towards Computation- and Communication-efficient Computational Pathology
Apr 03, 2025Despite the impressive performance across a wide range of applications, current computational pathology models face significant diagnostic efficiency challenges due to their reliance on high-magnification whole-slide image analysis. This limitation severely compromises their clinical utility, especially in time-sensitive diagnostic scenarios and situations requiring efficient data transfer. To address these issues, we present a novel computation- and communication-efficient framework called Magnification-Aligned Global-Local Transformer (MAGA-GLTrans). Our approach significantly reduces computational time, file transfer requirements, and storage overhead by enabling effective analysis using low-magnification inputs rather than high-magnification ones. The key innovation lies in our proposed magnification alignment (MAGA) mechanism, which employs self-supervised learning to bridge the information gap between low and high magnification levels by effectively aligning their feature representations. Through extensive evaluation across various fundamental CPath tasks, MAGA-GLTrans demonstrates state-of-the-art classification performance while achieving remarkable efficiency gains: up to 10.7 times reduction in computational time and over 20 times reduction in file transfer and storage requirements. Furthermore, we highlight the versatility of our MAGA framework through two significant extensions: (1) its applicability as a feature extractor to enhance the efficiency of any CPath architecture, and (2) its compatibility with existing foundation models and histopathology-specific encoders, enabling them to process low-magnification inputs with minimal information loss. These advancements position MAGA-GLTrans as a particularly promising solution for time-sensitive applications, especially in the context of intraoperative frozen section diagnosis where both accuracy and efficiency are paramount.
Motion Artifact Removal in Pixel-Frequency Domain via Alternate Masks and Diffusion Model
Dec 10, 2024Motion artifacts present in magnetic resonance imaging (MRI) can seriously interfere with clinical diagnosis. Removing motion artifacts is a straightforward solution and has been extensively studied. However, paired data are still heavily relied on in recent works and the perturbations in \textit{k}-space (frequency domain) are not well considered, which limits their applications in the clinical field. To address these issues, we propose a novel unsupervised purification method which leverages pixel-frequency information of noisy MRI images to guide a pre-trained diffusion model to recover clean MRI images. Specifically, considering that motion artifacts are mainly concentrated in high-frequency components in \textit{k}-space, we utilize the low-frequency components as the guide to ensure correct tissue textures. Additionally, given that high-frequency and pixel information are helpful for recovering shape and detail textures, we design alternate complementary masks to simultaneously destroy the artifact structure and exploit useful information. Quantitative experiments are performed on datasets from different tissues and show that our method achieves superior performance on several metrics. Qualitative evaluations with radiologists also show that our method provides better clinical feedback. Our code is available at https://github.com/medcx/PFAD.
HySparK: Hybrid Sparse Masking for Large Scale Medical Image Pre-Training
Aug 11, 2024



The generative self-supervised learning strategy exhibits remarkable learning representational capabilities. However, there is limited attention to end-to-end pre-training methods based on a hybrid architecture of CNN and Transformer, which can learn strong local and global representations simultaneously. To address this issue, we propose a generative pre-training strategy called Hybrid Sparse masKing (HySparK) based on masked image modeling and apply it to large-scale pre-training on medical images. First, we perform a bottom-up 3D hybrid masking strategy on the encoder to keep consistency masking. Then we utilize sparse convolution for the top CNNs and encode unmasked patches for the bottom vision Transformers. Second, we employ a simple hierarchical decoder with skip-connections to achieve dense multi-scale feature reconstruction. Third, we implement our pre-training method on a collection of multiple large-scale 3D medical imaging datasets. Extensive experiments indicate that our proposed pre-training strategy demonstrates robust transfer-ability in supervised downstream tasks and sheds light on HySparK's promising prospects. The code is available at https://github.com/FengheTan9/HySparK
Prototype Learning Guided Hybrid Network for Breast Tumor Segmentation in DCE-MRI
Aug 11, 2024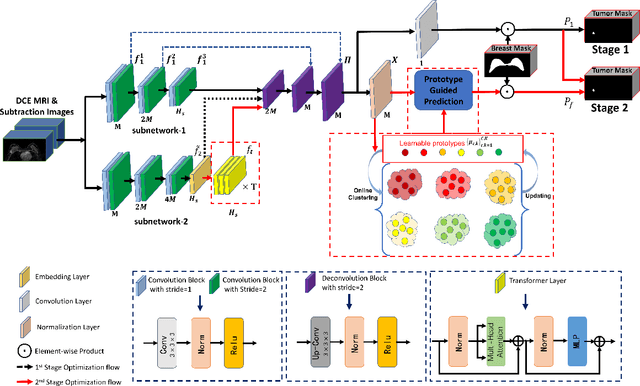
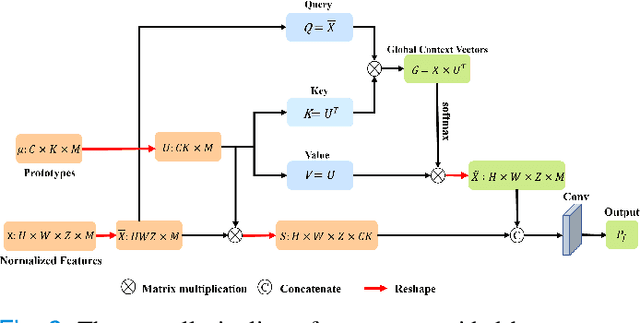
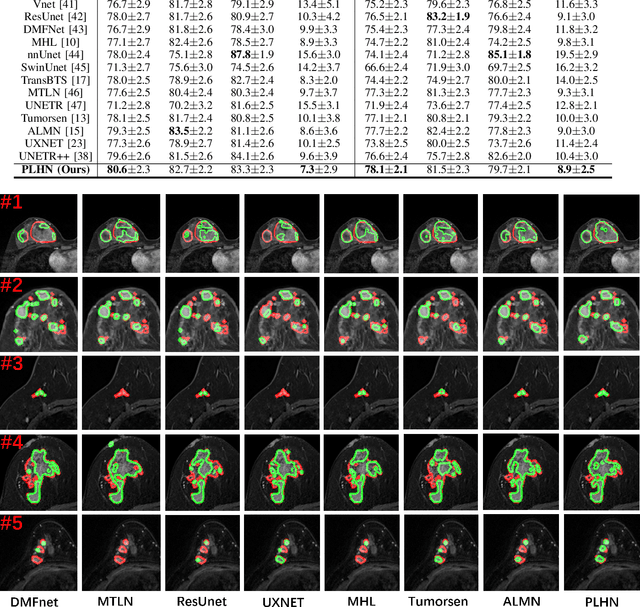
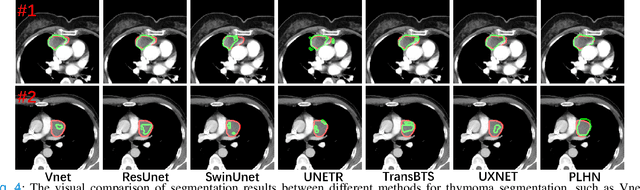
Automated breast tumor segmentation on the basis of dynamic contrast-enhancement magnetic resonance imaging (DCE-MRI) has shown great promise in clinical practice, particularly for identifying the presence of breast disease. However, accurate segmentation of breast tumor is a challenging task, often necessitating the development of complex networks. To strike an optimal trade-off between computational costs and segmentation performance, we propose a hybrid network via the combination of convolution neural network (CNN) and transformer layers. Specifically, the hybrid network consists of a encoder-decoder architecture by stacking convolution and decovolution layers. Effective 3D transformer layers are then implemented after the encoder subnetworks, to capture global dependencies between the bottleneck features. To improve the efficiency of hybrid network, two parallel encoder subnetworks are designed for the decoder and the transformer layers, respectively. To further enhance the discriminative capability of hybrid network, a prototype learning guided prediction module is proposed, where the category-specified prototypical features are calculated through on-line clustering. All learned prototypical features are finally combined with the features from decoder for tumor mask prediction. The experimental results on private and public DCE-MRI datasets demonstrate that the proposed hybrid network achieves superior performance than the state-of-the-art (SOTA) methods, while maintaining balance between segmentation accuracy and computation cost. Moreover, we demonstrate that automatically generated tumor masks can be effectively applied to identify HER2-positive subtype from HER2-negative subtype with the similar accuracy to the analysis based on manual tumor segmentation. The source code is available at https://github.com/ZhouL-lab/PLHN.
CycleINR: Cycle Implicit Neural Representation for Arbitrary-Scale Volumetric Super-Resolution of Medical Data
Apr 07, 2024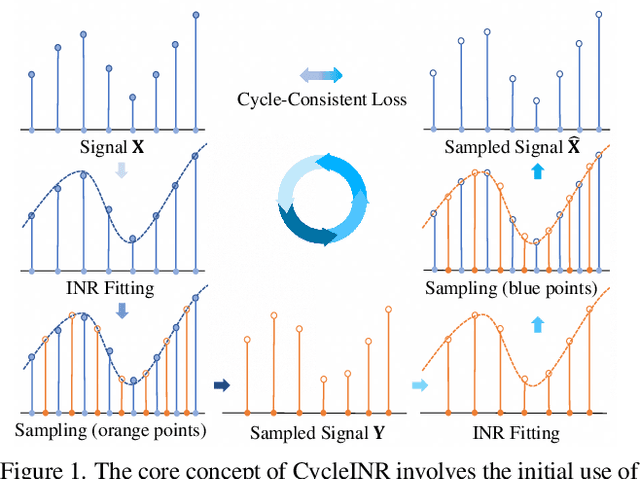
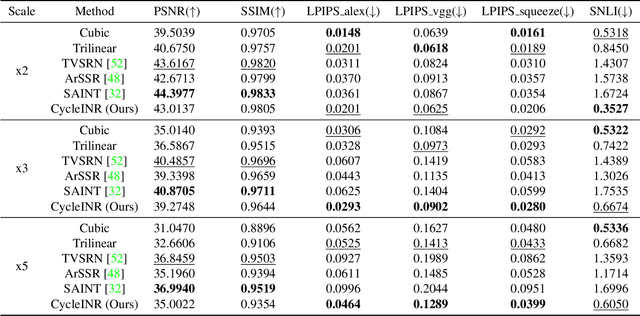
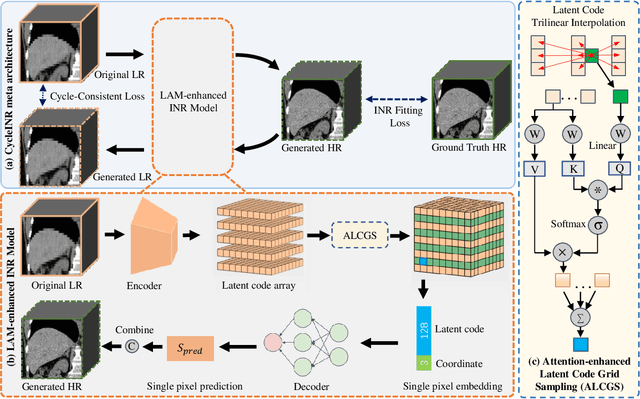

In the realm of medical 3D data, such as CT and MRI images, prevalent anisotropic resolution is characterized by high intra-slice but diminished inter-slice resolution. The lowered resolution between adjacent slices poses challenges, hindering optimal viewing experiences and impeding the development of robust downstream analysis algorithms. Various volumetric super-resolution algorithms aim to surmount these challenges, enhancing inter-slice resolution and overall 3D medical imaging quality. However, existing approaches confront inherent challenges: 1) often tailored to specific upsampling factors, lacking flexibility for diverse clinical scenarios; 2) newly generated slices frequently suffer from over-smoothing, degrading fine details, and leading to inter-slice inconsistency. In response, this study presents CycleINR, a novel enhanced Implicit Neural Representation model for 3D medical data volumetric super-resolution. Leveraging the continuity of the learned implicit function, the CycleINR model can achieve results with arbitrary up-sampling rates, eliminating the need for separate training. Additionally, we enhance the grid sampling in CycleINR with a local attention mechanism and mitigate over-smoothing by integrating cycle-consistent loss. We introduce a new metric, Slice-wise Noise Level Inconsistency (SNLI), to quantitatively assess inter-slice noise level inconsistency. The effectiveness of our approach is demonstrated through image quality evaluations on an in-house dataset and a downstream task analysis on the Medical Segmentation Decathlon liver tumor dataset.
$M^{2}$Fusion: Bayesian-based Multimodal Multi-level Fusion on Colorectal Cancer Microsatellite Instability Prediction
Jan 15, 2024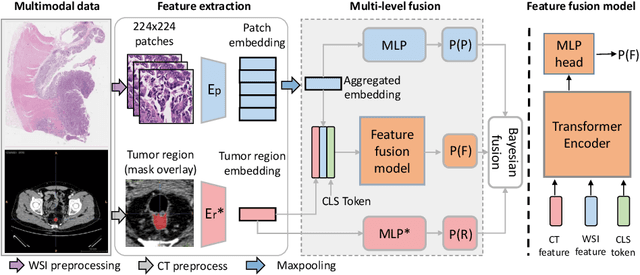
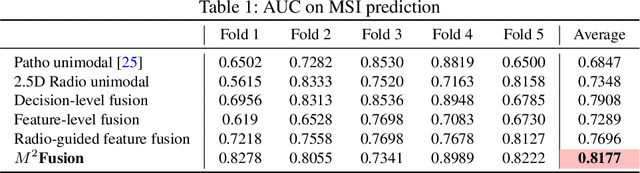
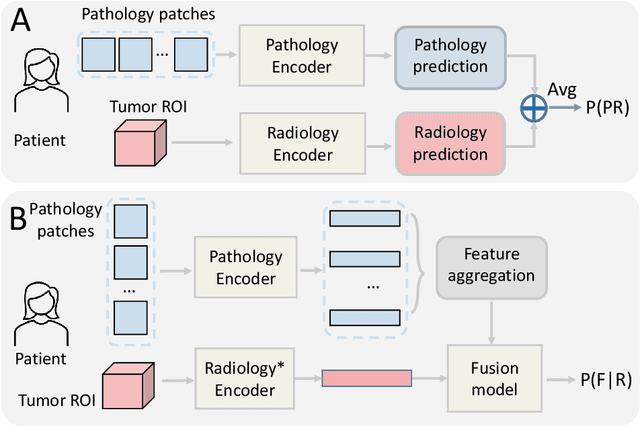

Colorectal cancer (CRC) micro-satellite instability (MSI) prediction on histopathology images is a challenging weakly supervised learning task that involves multi-instance learning on gigapixel images. To date, radiology images have proven to have CRC MSI information and efficient patient imaging techniques. Different data modalities integration offers the opportunity to increase the accuracy and robustness of MSI prediction. Despite the progress in representation learning from the whole slide images (WSI) and exploring the potential of making use of radiology data, CRC MSI prediction remains a challenge to fuse the information from multiple data modalities (e.g., pathology WSI and radiology CT image). In this paper, we propose $M^{2}$Fusion: a Bayesian-based multimodal multi-level fusion pipeline for CRC MSI. The proposed fusion model $M^{2}$Fusion is capable of discovering more novel patterns within and across modalities that are beneficial for predicting MSI than using a single modality alone, as well as other fusion methods. The contribution of the paper is three-fold: (1) $M^{2}$Fusion is the first pipeline of multi-level fusion on pathology WSI and 3D radiology CT image for MSI prediction; (2) CT images are the first time integrated into multimodal fusion for CRC MSI prediction; (3) feature-level fusion strategy is evaluated on both Transformer-based and CNN-based method. Our approach is validated on cross-validation of 352 cases and outperforms either feature-level (0.8177 vs. 0.7908) or decision-level fusion strategy (0.8177 vs. 0.7289) on AUC score.
BroadCAM: Outcome-agnostic Class Activation Mapping for Small-scale Weakly Supervised Applications
Sep 07, 2023



Class activation mapping~(CAM), a visualization technique for interpreting deep learning models, is now commonly used for weakly supervised semantic segmentation~(WSSS) and object localization~(WSOL). It is the weighted aggregation of the feature maps by activating the high class-relevance ones. Current CAM methods achieve it relying on the training outcomes, such as predicted scores~(forward information), gradients~(backward information), etc. However, when with small-scale data, unstable training may lead to less effective model outcomes and generate unreliable weights, finally resulting in incorrect activation and noisy CAM seeds. In this paper, we propose an outcome-agnostic CAM approach, called BroadCAM, for small-scale weakly supervised applications. Since broad learning system (BLS) is independent to the model learning, BroadCAM can avoid the weights being affected by the unreliable model outcomes when with small-scale data. By evaluating BroadCAM on VOC2012 (natural images) and BCSS-WSSS (medical images) for WSSS and OpenImages30k for WSOL, BroadCAM demonstrates superior performance than existing CAM methods with small-scale data (less than 5\%) in different CNN architectures. It also achieves SOTA performance with large-scale training data. Extensive qualitative comparisons are conducted to demonstrate how BroadCAM activates the high class-relevance feature maps and generates reliable CAMs when with small-scale training data.
Improved Prognostic Prediction of Pancreatic Cancer Using Multi-Phase CT by Integrating Neural Distance and Texture-Aware Transformer
Aug 01, 2023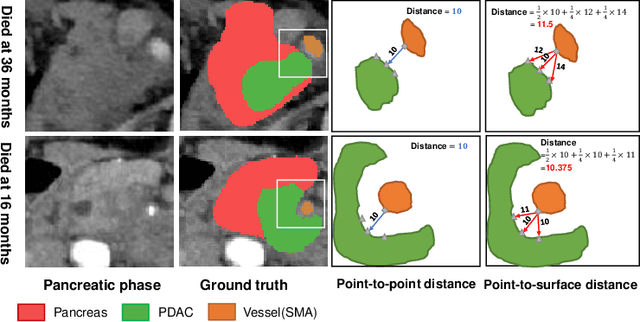
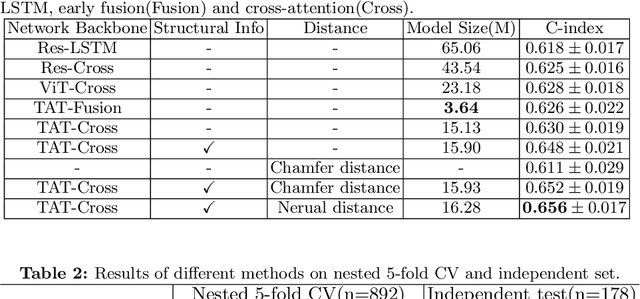
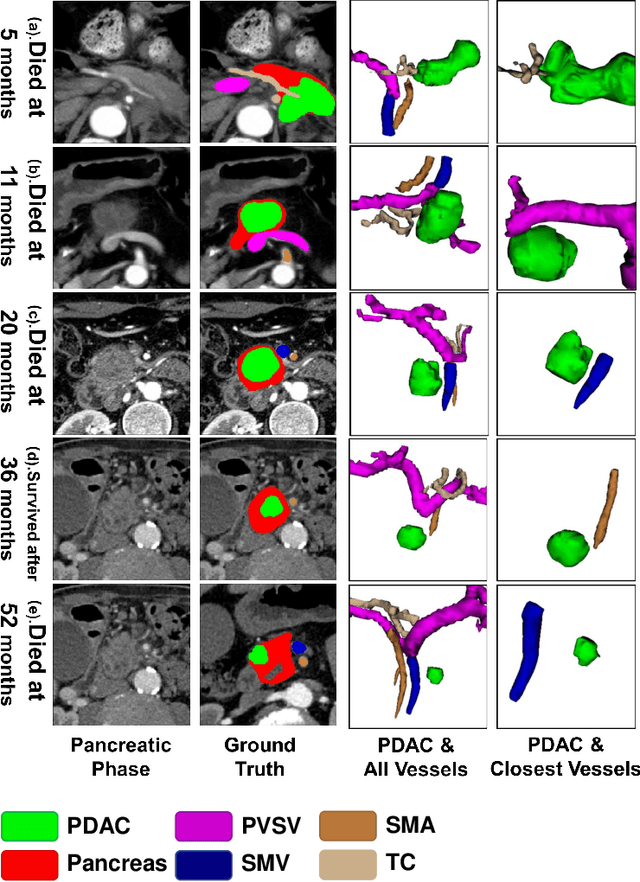
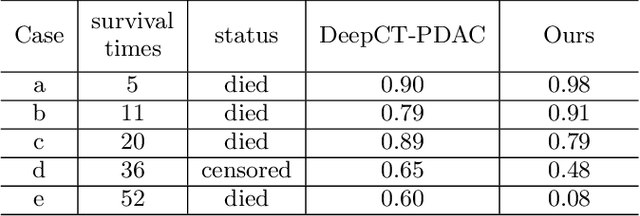
Pancreatic ductal adenocarcinoma (PDAC) is a highly lethal cancer in which the tumor-vascular involvement greatly affects the resectability and, thus, overall survival of patients. However, current prognostic prediction methods fail to explicitly and accurately investigate relationships between the tumor and nearby important vessels. This paper proposes a novel learnable neural distance that describes the precise relationship between the tumor and vessels in CT images of different patients, adopting it as a major feature for prognosis prediction. Besides, different from existing models that used CNNs or LSTMs to exploit tumor enhancement patterns on dynamic contrast-enhanced CT imaging, we improved the extraction of dynamic tumor-related texture features in multi-phase contrast-enhanced CT by fusing local and global features using CNN and transformer modules, further enhancing the features extracted across multi-phase CT images. We extensively evaluated and compared the proposed method with existing methods in the multi-center (n=4) dataset with 1,070 patients with PDAC, and statistical analysis confirmed its clinical effectiveness in the external test set consisting of three centers. The developed risk marker was the strongest predictor of overall survival among preoperative factors and it has the potential to be combined with established clinical factors to select patients at higher risk who might benefit from neoadjuvant therapy.