 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the CXR-LT 2026 Challenge: Multi-Center Long-Tailed and Zero Shot Chest X-ray Classification
Feb 25, 2026Chest X-ray (CXR) interpretation is hindered by the long-tailed distribution of pathologies and the open-world nature of clinical environments. Existing benchmarks often rely on closed-set classes from single institutions, failing to capture the prevalence of rare diseases or the appearance of novel findings. To address this, we present the CXR-LT 2026 challenge. This third iteration of the benchmark introduces a multi-center dataset comprising over 145,000 images from PadChest and NIH Chest X-ray datasets. The challenge defines two core tasks: (1) Robust Multi-Label Classification on 30 known classes and (2) Open-World Generalization to 6 unseen (out-of-distribution) rare disease classes. We report the results of the top-performing teams, evaluating them via mean Average Precision (mAP), AUROC, and F1-score. The winning solutions achieved an mAP of 0.5854 on Task 1 and 0.4315 on Task 2, demonstrating that large-scale vision-language pre-training significantly mitigates the performance drop typically associated with zero-shot diagnosis.
A Disease-Aware Dual-Stage Framework for Chest X-ray Report Generation
Nov 15, 2025Radiology report generation from chest X-rays is an important task in artificial intelligence with the potential to greatly reduce radiologists' workload and shorten patient wait times. Despite recent advances, existing approaches often lack sufficient disease-awareness in visual representations and adequate vision-language alignment to meet the specialized requirements of medical image analysis. As a result, these models usually overlook critical pathological features on chest X-rays and struggle to generate clinically accurate reports. To address these limitations, we propose a novel dual-stage disease-aware framework for chest X-ray report generation. In Stage~1, our model learns Disease-Aware Semantic Tokens (DASTs) corresponding to specific pathology categories through cross-attention mechanisms and multi-label classification, while simultaneously aligning vision and language representations via contrastive learning. In Stage~2, we introduce a Disease-Visual Attention Fusion (DVAF) module to integrate disease-aware representations with visual features, along with a Dual-Modal Similarity Retrieval (DMSR) mechanism that combines visual and disease-specific similarities to retrieve relevant exemplars, providing contextual guidance during report generation. Extensive experiments on benchmark datasets (i.e., CheXpert Plus, IU X-ray, and MIMIC-CXR) demonstrate that our disease-aware framework achieves state-of-the-art performance in chest X-ray report generation, with significant improvements in clinical accuracy and linguistic quality.
crossMoDA Challenge: Evolution of Cross-Modality Domain Adaptation Techniques for Vestibular Schwannoma and Cochlea Segmentation from 2021 to 2023
Jun 13, 2025The cross-Modality Domain Adaptation (crossMoDA) challenge series, initiated in 2021 in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), focuses on unsupervised cross-modality segmentation, learning from contrast-enhanced T1 (ceT1) and transferring to T2 MRI. The task is an extreme example of domain shift chosen to serve as a meaningful and illustrative benchmark. From a clinical application perspective, it aims to automate Vestibular Schwannoma (VS) and cochlea segmentation on T2 scans for more cost-effective VS management. Over time, the challenge objectives have evolved to enhance its clinical relevance. The challenge evolved from using single-institutional data and basic segmentation in 2021 to incorporating multi-institutional data and Koos grading in 2022, and by 2023, it included heterogeneous routine data and sub-segmentation of intra- and extra-meatal tumour components. In this work, we report the findings of the 2022 and 2023 editions and perform a retrospective analysis of the challenge progression over the years. The observations from the successive challenge contributions indicate that the number of outliers decreases with an expanding dataset. This is notable since the diversity of scanning protocols of the datasets concurrently increased. The winning approach of the 2023 edition reduced the number of outliers on the 2021 and 2022 testing data, demonstrating how increased data heterogeneity can enhance segmentation performance even on homogeneous data. However, the cochlea Dice score declined in 2023, likely due to the added complexity from tumour sub-annotations affecting overall segmentation performance. While progress is still needed for clinically acceptable VS segmentation, the plateauing performance suggests that a more challenging cross-modal task may better serve future benchmarking.
Improved Prognostic Prediction of Pancreatic Cancer Using Multi-Phase CT by Integrating Neural Distance and Texture-Aware Transformer
Aug 01, 2023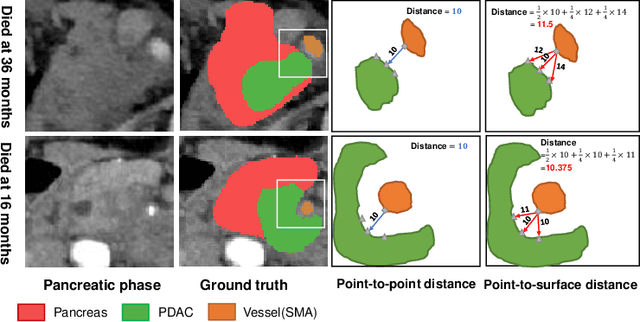
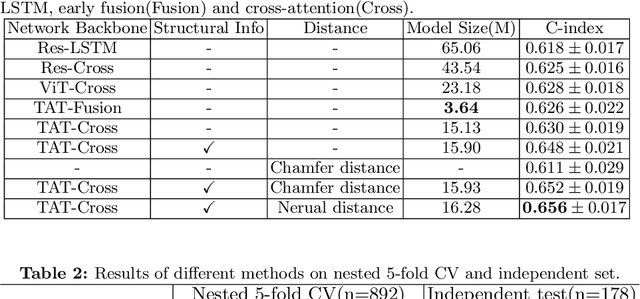
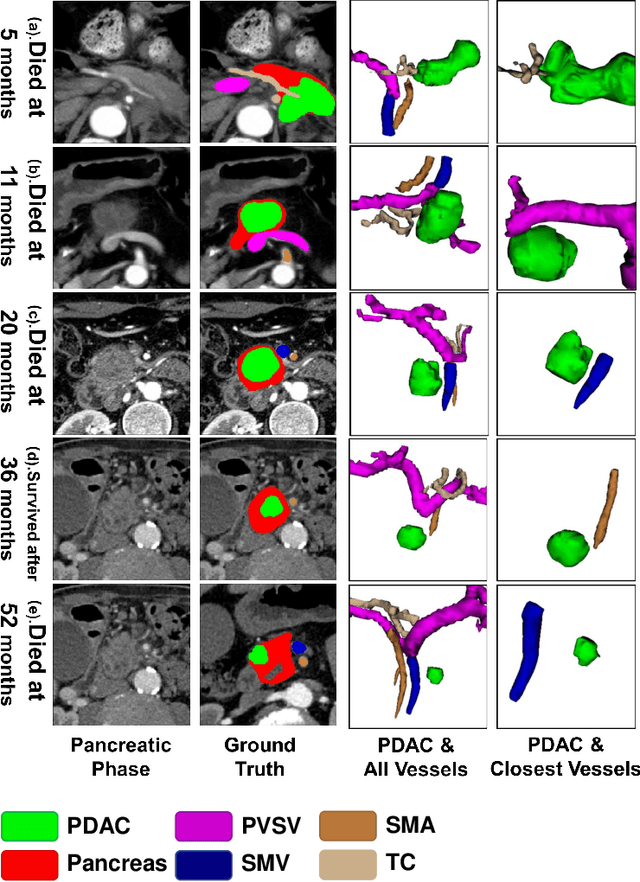
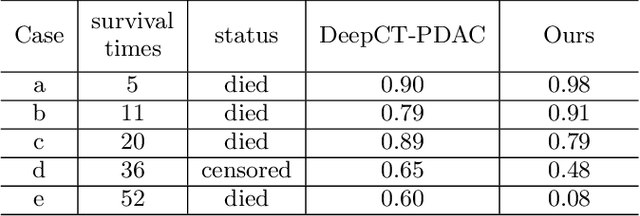
Pancreatic ductal adenocarcinoma (PDAC) is a highly lethal cancer in which the tumor-vascular involvement greatly affects the resectability and, thus, overall survival of patients. However, current prognostic prediction methods fail to explicitly and accurately investigate relationships between the tumor and nearby important vessels. This paper proposes a novel learnable neural distance that describes the precise relationship between the tumor and vessels in CT images of different patients, adopting it as a major feature for prognosis prediction. Besides, different from existing models that used CNNs or LSTMs to exploit tumor enhancement patterns on dynamic contrast-enhanced CT imaging, we improved the extraction of dynamic tumor-related texture features in multi-phase contrast-enhanced CT by fusing local and global features using CNN and transformer modules, further enhancing the features extracted across multi-phase CT images. We extensively evaluated and compared the proposed method with existing methods in the multi-center (n=4) dataset with 1,070 patients with PDAC, and statistical analysis confirmed its clinical effectiveness in the external test set consisting of three centers. The developed risk marker was the strongest predictor of overall survival among preoperative factors and it has the potential to be combined with established clinical factors to select patients at higher risk who might benefit from neoadjuvant therapy.
Cluster-Induced Mask Transformers for Effective Opportunistic Gastric Cancer Screening on Non-contrast CT Scans
Jul 16, 2023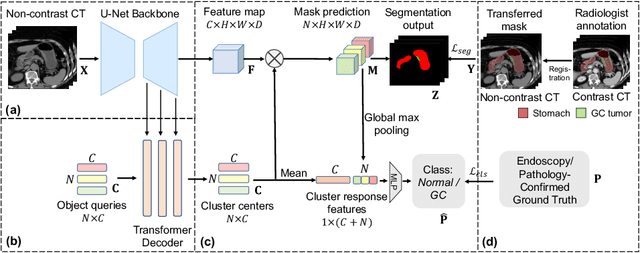
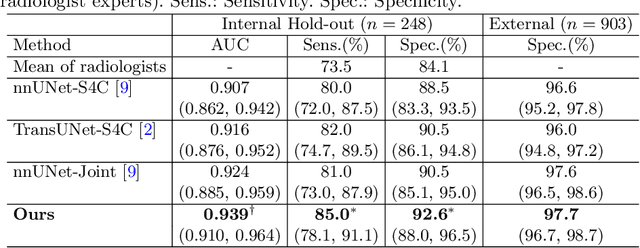
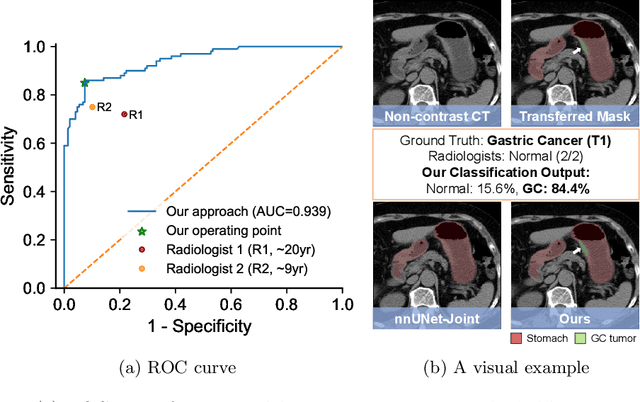
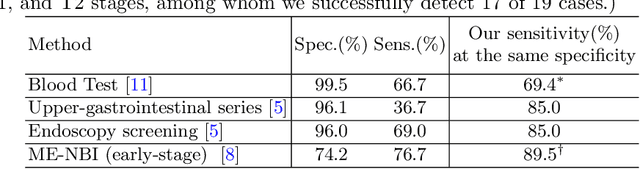
Gastric cancer is the third leading cause of cancer-related mortality worldwide, but no guideline-recommended screening test exists. Existing methods can be invasive, expensive, and lack sensitivity to identify early-stage gastric cancer. In this study, we explore the feasibility of using a deep learning approach on non-contrast CT scans for gastric cancer detection. We propose a novel cluster-induced Mask Transformer that jointly segments the tumor and classifies abnormality in a multi-task manner. Our model incorporates learnable clusters that encode the texture and shape prototypes of gastric cancer, utilizing self- and cross-attention to interact with convolutional features. In our experiments, the proposed method achieves a sensitivity of 85.0% and specificity of 92.6% for detecting gastric tumors on a hold-out test set consisting of 100 patients with cancer and 148 normal. In comparison, two radiologists have an average sensitivity of 73.5% and specificity of 84.3%. We also obtain a specificity of 97.7% on an external test set with 903 normal cases. Our approach performs comparably to established state-of-the-art gastric cancer screening tools like blood testing and endoscopy, while also being more sensitive in detecting early-stage cancer. This demonstrates the potential of our approach as a novel, non-invasive, low-cost, and accurate method for opportunistic gastric cancer screening.
Devil is in the Queries: Advancing Mask Transformers for Real-world Medical Image Segmentation and Out-of-Distribution Localization
Apr 01, 2023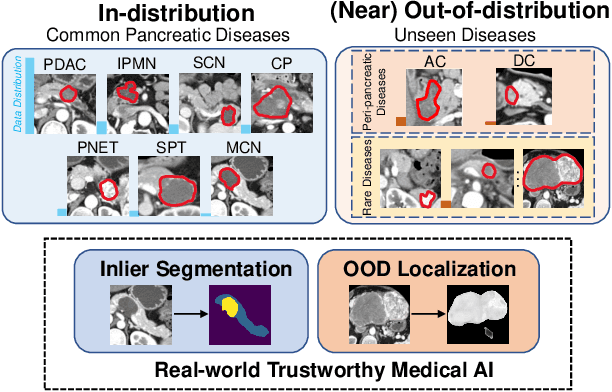
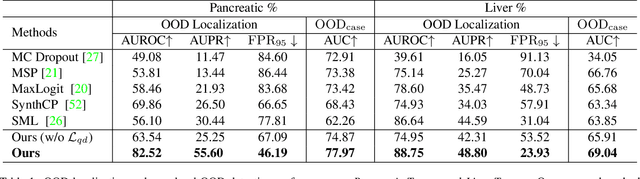
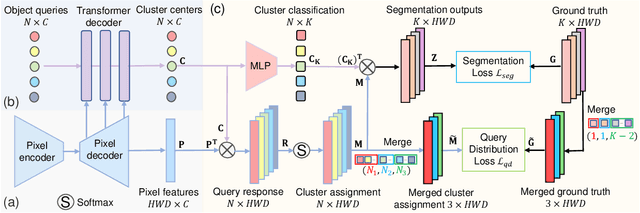

Real-world medical image segmentation has tremendous long-tailed complexity of objects, among which tail conditions correlate with relatively rare diseases and are clinically significant. A trustworthy medical AI algorithm should demonstrate its effectiveness on tail conditions to avoid clinically dangerous damage in these out-of-distribution (OOD) cases. In this paper, we adopt the concept of object queries in Mask Transformers to formulate semantic segmentation as a soft cluster assignment. The queries fit the feature-level cluster centers of inliers during training. Therefore, when performing inference on a medical image in real-world scenarios, the similarity between pixels and the queries detects and localizes OOD regions. We term this OOD localization as MaxQuery. Furthermore, the foregrounds of real-world medical images, whether OOD objects or inliers, are lesions. The difference between them is less than that between the foreground and background, possibly misleading the object queries to focus redundantly on the background. Thus, we propose a query-distribution (QD) loss to enforce clear boundaries between segmentation targets and other regions at the query level, improving the inlier segmentation and OOD indication. Our proposed framework is tested on two real-world segmentation tasks, i.e., segmentation of pancreatic and liver tumors, outperforming previous state-of-the-art algorithms by an average of 7.39% on AUROC, 14.69% on AUPR, and 13.79% on FPR95 for OOD localization. On the other hand, our framework improves the performance of inlier segmentation by an average of 5.27% DSC when compared with the leading baseline nnUNet.
Region-Aware Metric Learning for Open World Semantic Segmentation via Meta-Channel Aggregation
May 17, 2022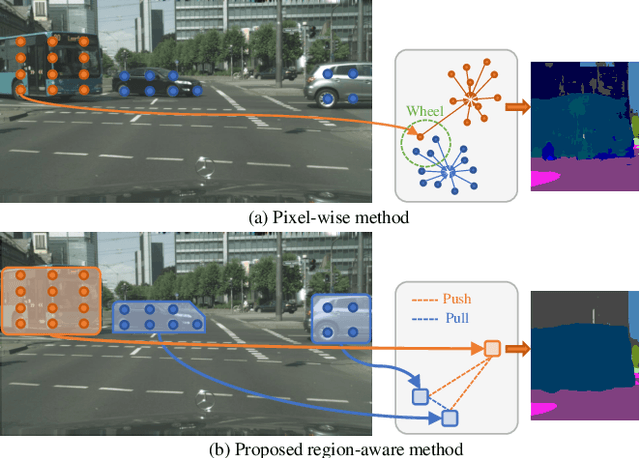
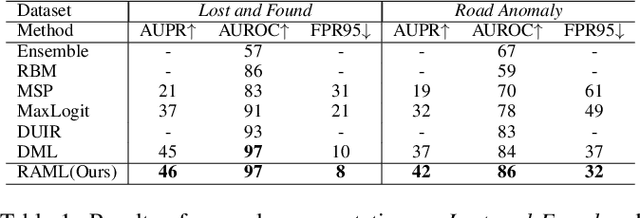
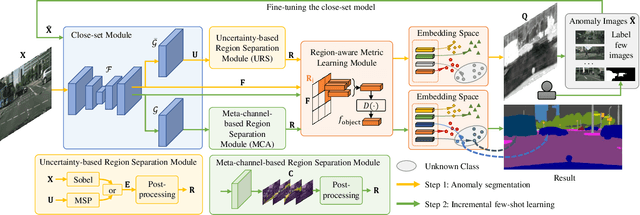
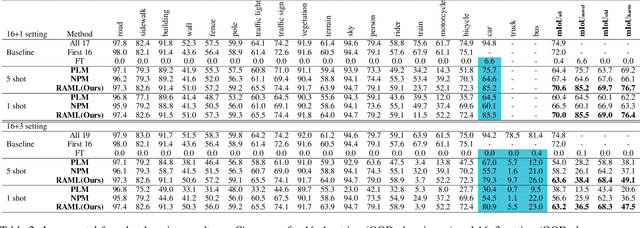
As one of the most challenging and practical segmentation tasks, open-world semantic segmentation requires the model to segment the anomaly regions in the images and incrementally learn to segment out-of-distribution (OOD) objects, especially under a few-shot condition. The current state-of-the-art (SOTA) method, Deep Metric Learning Network (DMLNet), relies on pixel-level metric learning, with which the identification of similar regions having different semantics is difficult. Therefore, we propose a method called region-aware metric learning (RAML), which first separates the regions of the images and generates region-aware features for further metric learning. RAML improves the integrity of the segmented anomaly regions. Moreover, we propose a novel meta-channel aggregation (MCA) module to further separate anomaly regions, forming high-quality sub-region candidates and thereby improving the model performance for OOD objects. To evaluate the proposed RAML, we have conducted extensive experiments and ablation studies on Lost And Found and Road Anomaly datasets for anomaly segmentation and the CityScapes dataset for incremental few-shot learning. The results show that the proposed RAML achieves SOTA performance in both stages of open world segmentation. Our code and appendix are available at https://github.com/czifan/RAML.
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022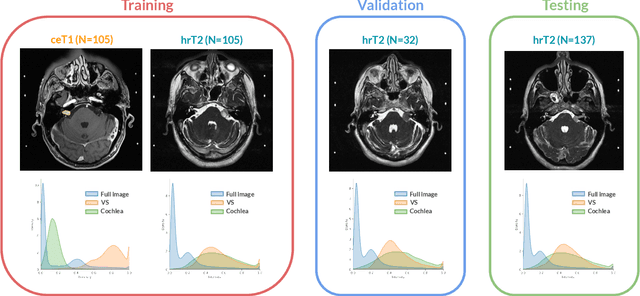
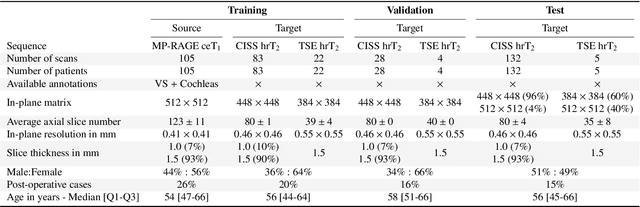
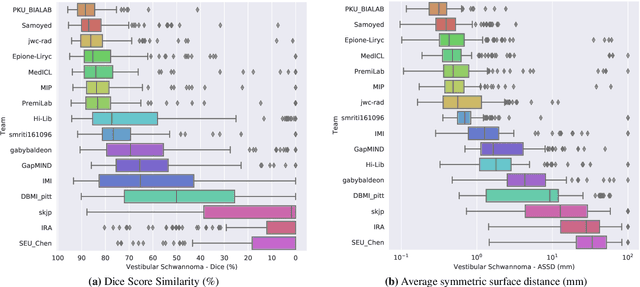
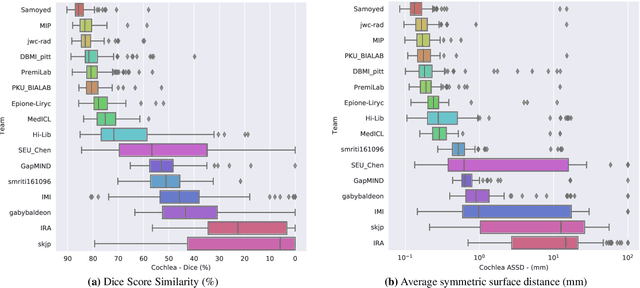
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.
Layer-Parallel Training of Residual Networks with Auxiliary-Variable Networks
Dec 10, 2021
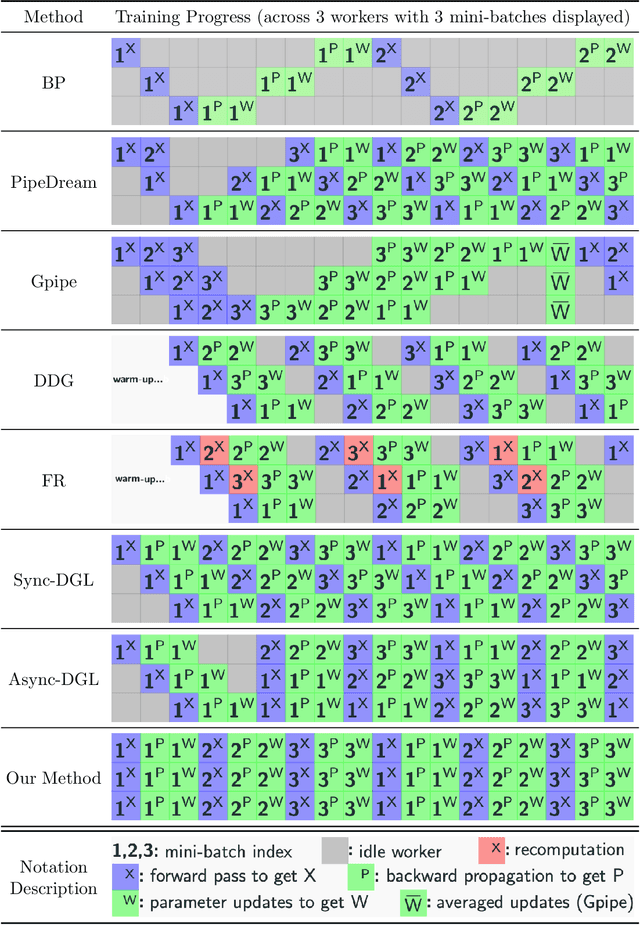

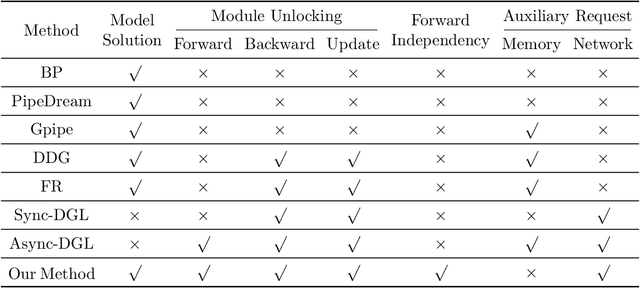
Gradient-based methods for the distributed training of residual networks (ResNets) typically require a forward pass of the input data, followed by back-propagating the error gradient to update model parameters, which becomes time-consuming as the network goes deeper. To break the algorithmic locking and exploit synchronous module parallelism in both the forward and backward modes, auxiliary-variable methods have attracted much interest lately but suffer from significant communication overhead and lack of data augmentation. In this work, a novel joint learning framework for training realistic ResNets across multiple compute devices is established by trading off the storage and recomputation of external auxiliary variables. More specifically, the input data of each independent processor is generated from its low-capacity auxiliary network (AuxNet), which permits the use of data augmentation and realizes forward unlocking. The backward passes are then executed in parallel, each with a local loss function that originates from the penalty or augmented Lagrangian (AL) methods. Finally, the proposed AuxNet is employed to reproduce the updated auxiliary variables through an end-to-end training process. We demonstrate the effectiveness of our methods on ResNets and WideResNets across CIFAR-10, CIFAR-100, and ImageNet datasets, achieving speedup over the traditional layer-serial training method while maintaining comparable testing accuracy.
Unsupervised Domain Adaptation in Semantic Segmentation Based on Pixel Alignment and Self-Training
Sep 29, 2021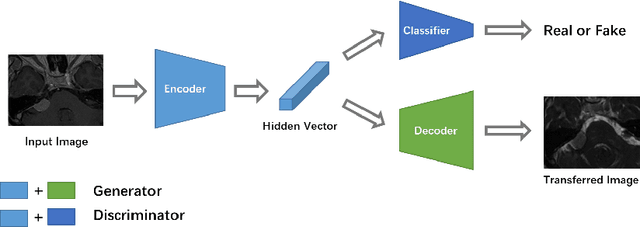
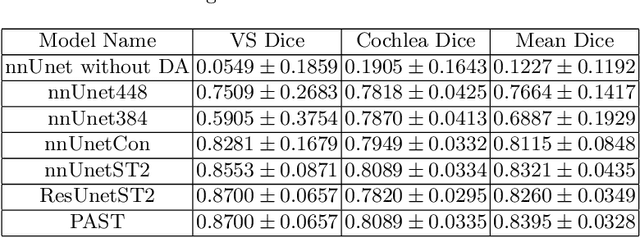
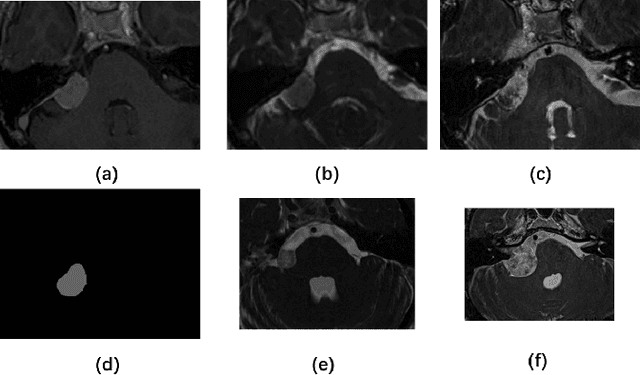
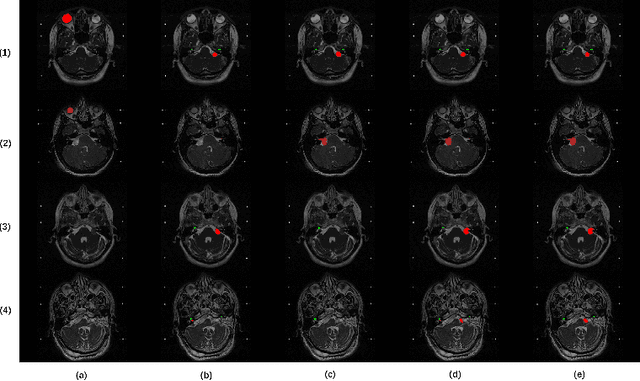
This paper proposes an unsupervised cross-modality domain adaptation approach based on pixel alignment and self-training. Pixel alignment transfers ceT1 scans to hrT2 modality, helping to reduce domain shift in the training segmentation model. Self-training adapts the decision boundary of the segmentation network to fit the distribution of hrT2 scans. Experiment results show that PAST has outperformed the non-UDA baseline significantly, and it received rank-2 on CrossMoDA validation phase Leaderboard with a mean Dice score of 0.8395.