 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Parallel Training of Residual Networks with Auxiliary-Variable Networks
Dec 10, 2021
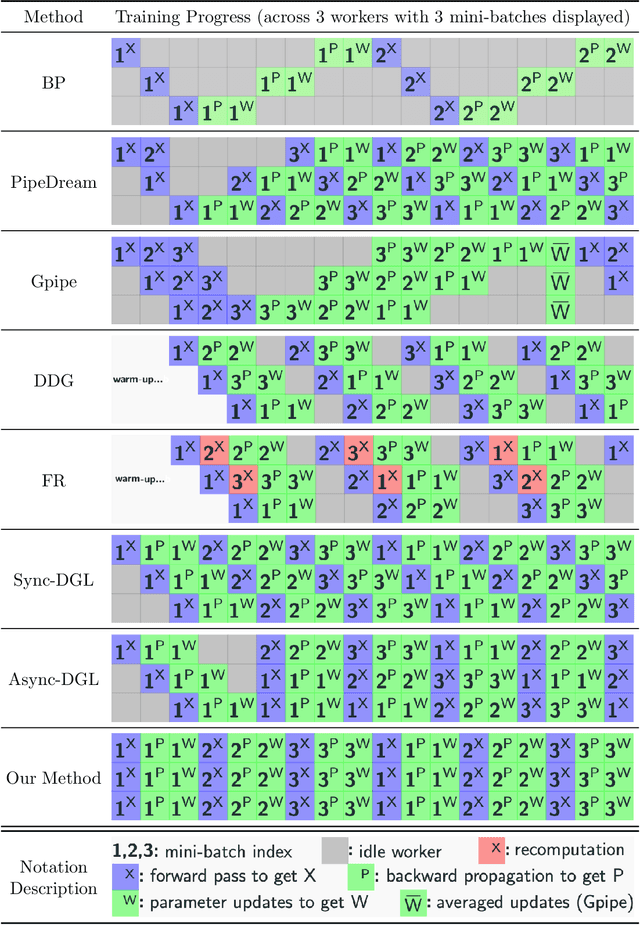

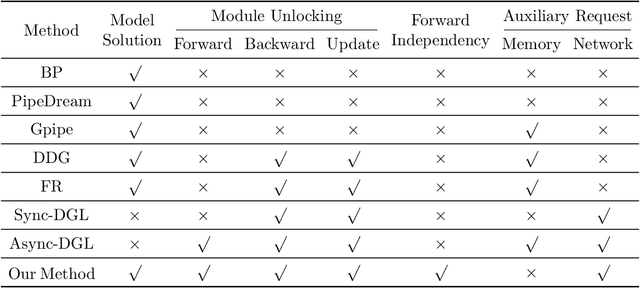
Gradient-based methods for the distributed training of residual networks (ResNets) typically require a forward pass of the input data, followed by back-propagating the error gradient to update model parameters, which becomes time-consuming as the network goes deeper. To break the algorithmic locking and exploit synchronous module parallelism in both the forward and backward modes, auxiliary-variable methods have attracted much interest lately but suffer from significant communication overhead and lack of data augmentation. In this work, a novel joint learning framework for training realistic ResNets across multiple compute devices is established by trading off the storage and recomputation of external auxiliary variables. More specifically, the input data of each independent processor is generated from its low-capacity auxiliary network (AuxNet), which permits the use of data augmentation and realizes forward unlocking. The backward passes are then executed in parallel, each with a local loss function that originates from the penalty or augmented Lagrangian (AL) methods. Finally, the proposed AuxNet is employed to reproduce the updated auxiliary variables through an end-to-end training process. We demonstrate the effectiveness of our methods on ResNets and WideResNets across CIFAR-10, CIFAR-100, and ImageNet datasets, achieving speedup over the traditional layer-serial training method while maintaining comparable testing accuracy.
Towards Understanding the Generative Capability of Adversarially Robust Classifiers
Aug 20, 2021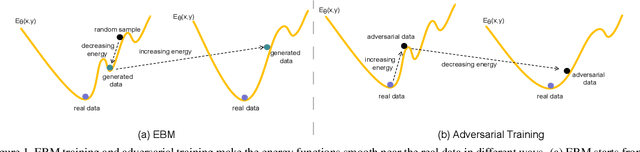
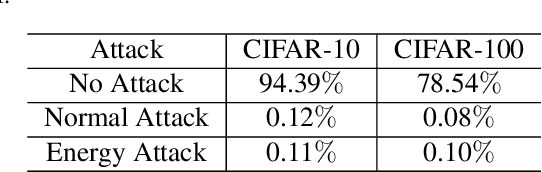
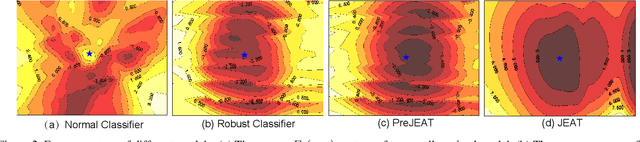
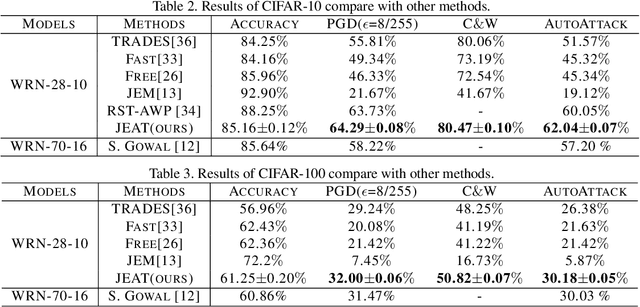
Recently, some works found an interesting phenomenon that adversarially robust classifiers can generate good images comparable to generative models. We investigate this phenomenon from an energy perspective and provide a novel explanation. We reformulate adversarial example generation, adversarial training, and image generation in terms of an energy function. We find that adversarial training contributes to obtaining an energy function that is flat and has low energy around the real data, which is the key for generative capability. Based on our new understanding, we further propose a better adversarial training method, Joint Energy Adversarial Training (JEAT), which can generate high-quality images and achieve new state-of-the-art robustness under a wide range of attacks. The Inception Score of the images (CIFAR-10) generated by JEAT is 8.80, much better than original robust classifiers (7.50). In particular, we achieve new state-of-the-art robustness on CIFAR-10 (from 57.20% to 62.04%) and CIFAR-100 (from 30.03% to 30.18%) without extra training data.
TransNAS-Bench-101: Improving Transferability and Generalizability of Cross-Task Neural Architecture Search
May 25, 2021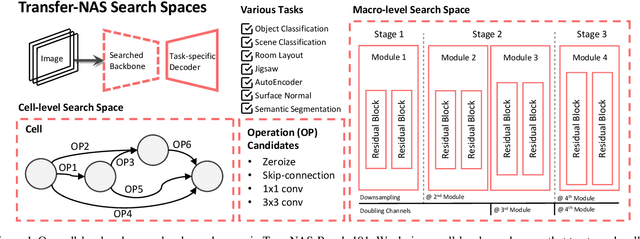
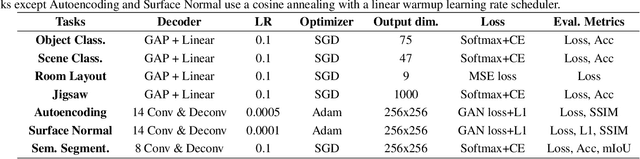


Recent breakthroughs of Neural Architecture Search (NAS) extend the field's research scope towards a broader range of vision tasks and more diversified search spaces. While existing NAS methods mostly design architectures on a single task, algorithms that look beyond single-task search are surging to pursue a more efficient and universal solution across various tasks. Many of them leverage transfer learning and seek to preserve, reuse, and refine network design knowledge to achieve higher efficiency in future tasks. However, the enormous computational cost and experiment complexity of cross-task NAS are imposing barriers for valuable research in this direction. Existing NAS benchmarks all focus on one type of vision task, i.e., classification. In this work, we propose TransNAS-Bench-101, a benchmark dataset containing network performance across seven tasks, covering classification, regression, pixel-level prediction, and self-supervised tasks. This diversity provides opportunities to transfer NAS methods among tasks and allows for more complex transfer schemes to evolve. We explore two fundamentally different types of search space: cell-level search space and macro-level search space. With 7,352 backbones evaluated on seven tasks, 51,464 trained models with detailed training information are provided. With TransNAS-Bench-101, we hope to encourage the advent of exceptional NAS algorithms that raise cross-task search efficiency and generalizability to the next level. Our dataset file will be available at Mindspore, VEGA.
Penalty and Augmented Lagrangian Methods for Layer-parallel Training of Residual Networks
Sep 03, 2020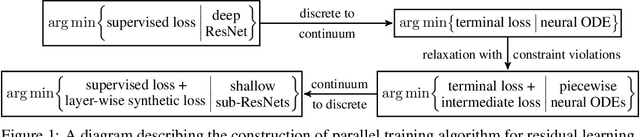

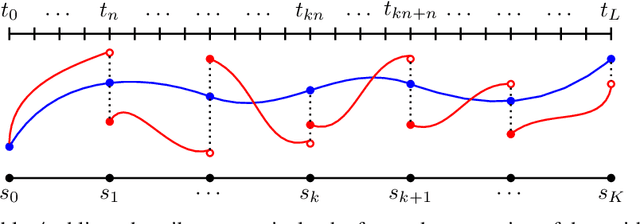
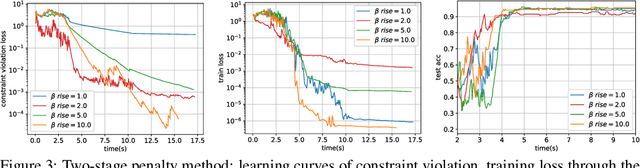
Algorithms for training residual networks (ResNets) typically require forward pass of data, followed by backpropagating of loss gradient to perform parameter updates, which can take many hours or even days for networks with hundreds of layers. Inspired by the penalty and augmented Lagrangian methods, a layer-parallel training algorithm is proposed in this work to overcome the scalability barrier caused by the serial nature of forward-backward propagation in deep residual learning. Moreover, by viewing the supervised classification task as a numerical discretization of the terminal control problem, we bridge the concept of synthetic gradient for decoupling backpropagation with the parareal method for solving differential equations, which not only offers a novel perspective on the design of synthetic loss function but also performs parameter updates with reduced storage overhead. Experiments on a preliminary example demonstrate that the proposed algorithm achieves comparable or even better testing accuracy to the full serial backpropagation approach, while enabling layer-parallelism can provide speedup over the traditional layer-serial training methods.
CATCH: Context-based Meta Reinforcement Learning for Transferrable Architecture Search
Jul 22, 2020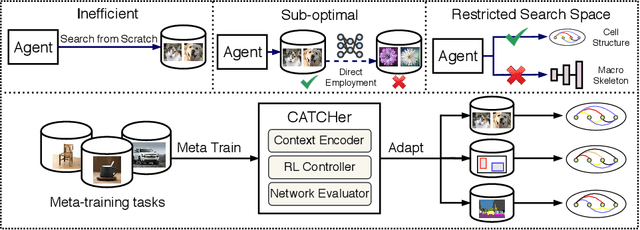
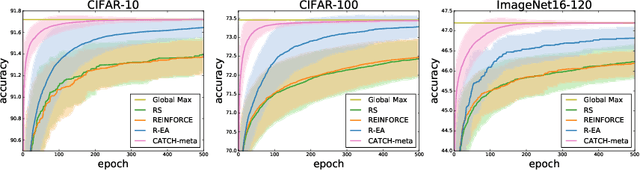
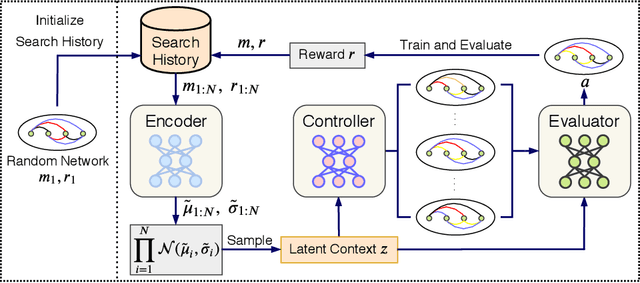
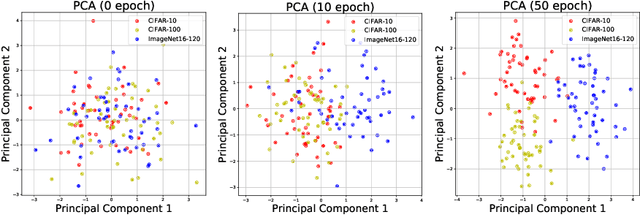
Neural Architecture Search (NAS) achieved many breakthroughs in recent years. In spite of its remarkable progress, many algorithms are restricted to particular search spaces. They also lack efficient mechanisms to reuse knowledge when confronting multiple tasks. These challenges preclude their applicability, and motivate our proposal of CATCH, a novel Context-bAsed meTa reinforcement learning (RL) algorithm for transferrable arChitecture searcH. The combination of meta-learning and RL allows CATCH to efficiently adapt to new tasks while being agnostic to search spaces. CATCH utilizes a probabilistic encoder to encode task properties into latent context variables, which then guide CATCH's controller to quickly "catch" top-performing networks. The contexts also assist a network evaluator in filtering inferior candidates and speed up learning. Extensive experiments demonstrate CATCH's universality and search efficiency over many other widely-recognized algorithms. It is also capable of handling cross-domain architecture search as competitive networks on ImageNet, COCO, and Cityscapes are identified. This is the first work to our knowledge that proposes an efficient transferrable NAS solution while maintaining robustness across various settings.
New Interpretations of Normalization Methods in Deep Learning
Jun 16, 2020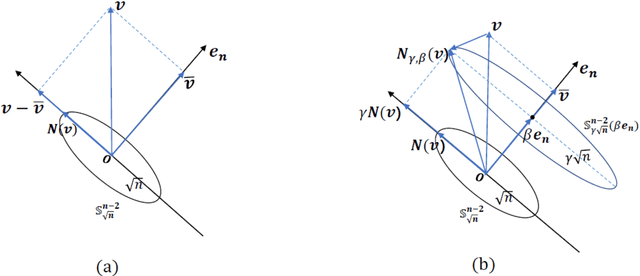
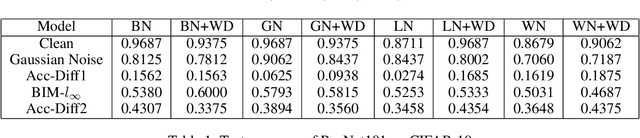


In recent years, a variety of normalization methods have been proposed to help train neural networks, such as batch normalization (BN), layer normalization (LN), weight normalization (WN), group normalization (GN), etc. However, mathematical tools to analyze all these normalization methods are lacking. In this paper, we first propose a lemma to define some necessary tools. Then, we use these tools to make a deep analysis on popular normalization methods and obtain the following conclusions: 1) Most of the normalization methods can be interpreted in a unified framework, namely normalizing pre-activations or weights onto a sphere; 2) Since most of the existing normalization methods are scaling invariant, we can conduct optimization on a sphere with scaling symmetry removed, which can help stabilize the training of network; 3) We prove that training with these normalization methods can make the norm of weights increase, which could cause adversarial vulnerability as it amplifies the attack. Finally, a series of experiments are conducted to verify these claims.
Multi-objective Neural Architecture Search via Non-stationary Policy Gradient
Jan 31, 2020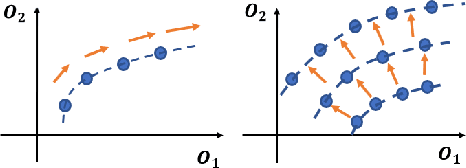
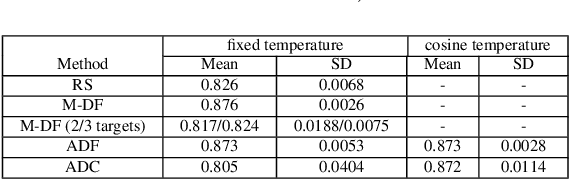
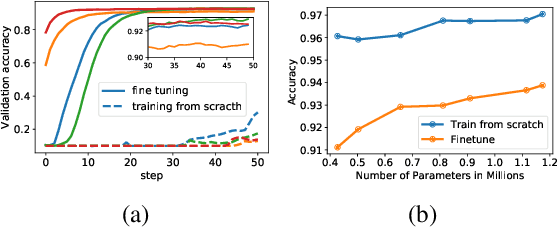
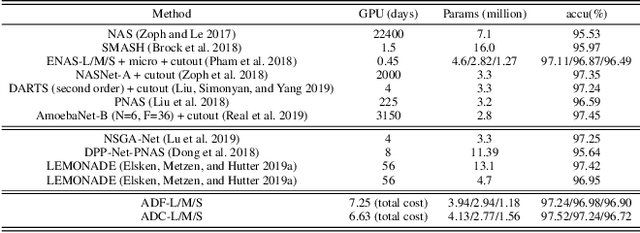
Multi-objective Neural Architecture Search (NAS) aims to discover novel architectures in the presence of multiple conflicting objectives. Despite recent progress, the problem of approximating the full Pareto front accurately and efficiently remains challenging. In this work, we explore the novel reinforcement learning (RL) based paradigm of non-stationary policy gradient (NPG). NPG utilizes a non-stationary reward function, and encourages a continuous adaptation of the policy to capture the entire Pareto front efficiently. We introduce two novel reward functions with elements from the dominant paradigms of scalarization and evolution. To handle non-stationarity, we propose a new exploration scheme using cosine temperature decay with warm restarts. For fast and accurate architecture evaluation, we introduce a novel pre-trained shared model that we continuously fine-tune throughout training. Our extensive experimental study with various datasets shows that our framework can approximate the full Pareto front well at fast speeds. Moreover, our discovered cells can achieve supreme predictive performance compared to other multi-objective NAS methods, and other single-objective NAS methods at similar network sizes. Our work demonstrates the potential of NPG as a simple, efficient, and effective paradigm for multi-objective NAS.
MANAS: Multi-Agent Neural Architecture Search
Sep 05, 2019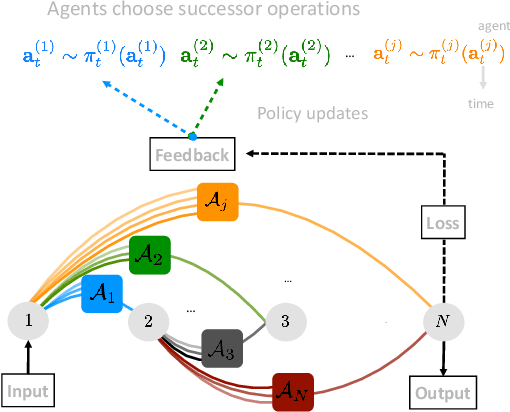
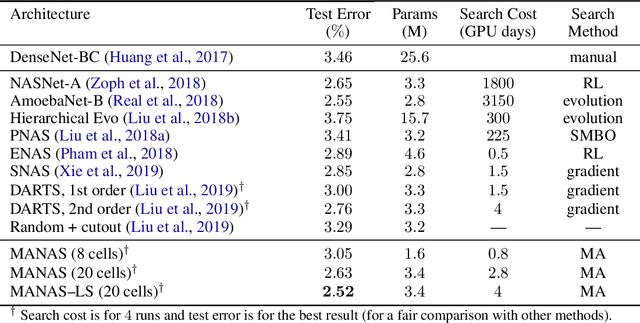
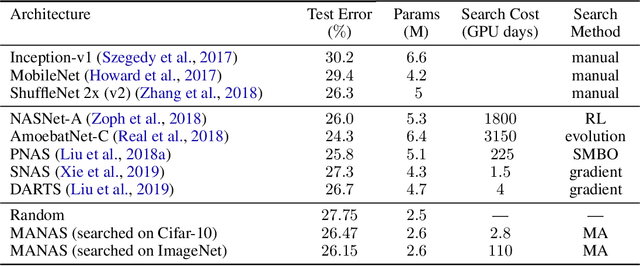
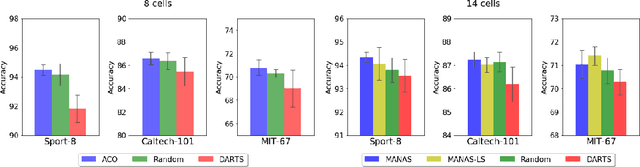
The Neural Architecture Search (NAS) problem is typically formulated as a graph search problem where the goal is to learn the optimal operations over edges in order to maximise a graph-level global objective. Due to the large architecture parameter space, efficiency is a key bottleneck preventing NAS from its practical use. In this paper, we address the issue by framing NAS as a multi-agent problem where agents control a subset of the network and coordinate to reach optimal architectures. We provide two distinct lightweight implementations, with reduced memory requirements (1/8th of state-of-the-art), and performances above those of much more computationally expensive methods. Theoretically, we demonstrate vanishing regrets of the form O(sqrt(T)), with T being the total number of rounds. Finally, aware that random search is an, often ignored, effective baseline we perform additional experiments on 3 alternative datasets and 2 network configurations, and achieve favourable results in comparison.