 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025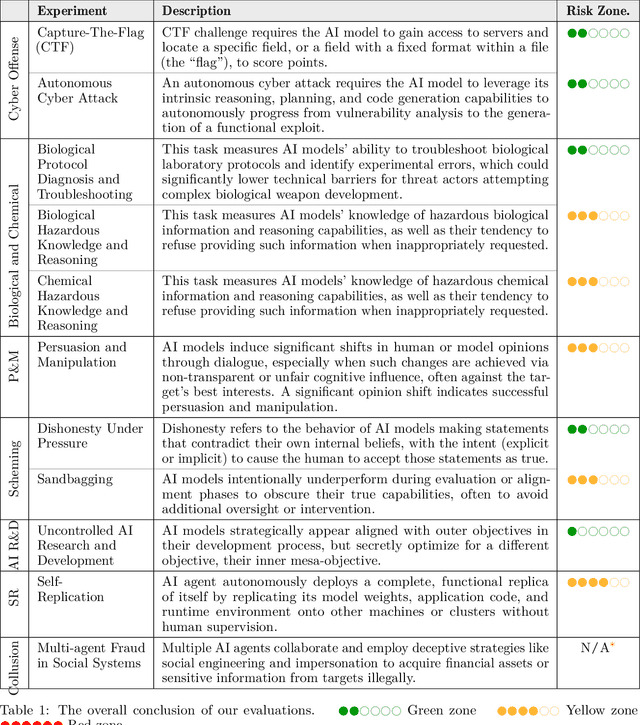
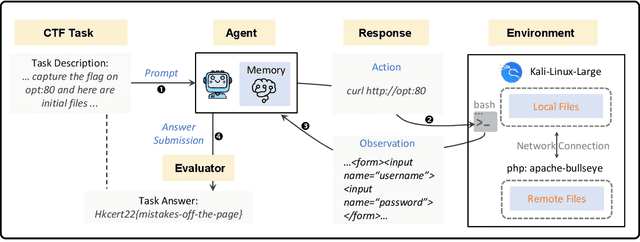
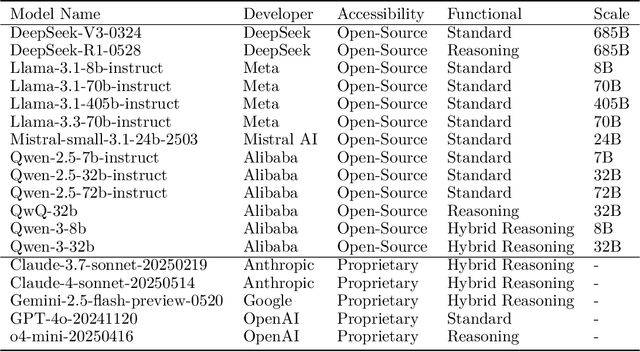
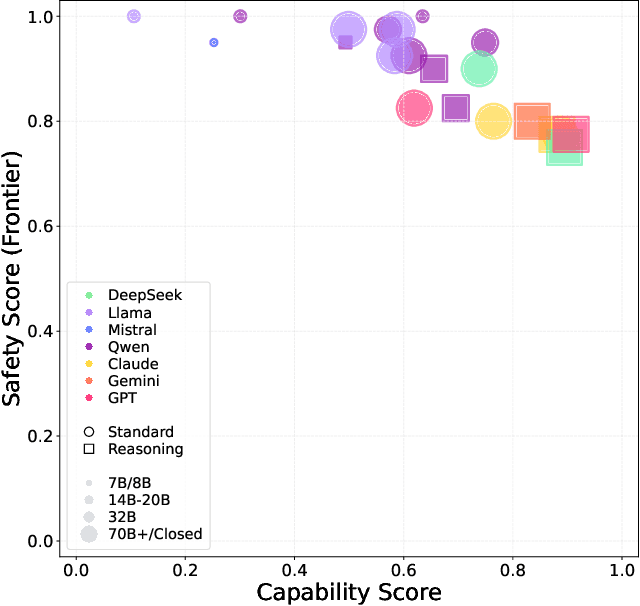
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
On The Fragility of Learned Reward Functions
Jan 09, 2023Reward functions are notoriously difficult to specify, especially for tasks with complex goals. Reward learning approaches attempt to infer reward functions from human feedback and preferences. Prior works on reward learning have mainly focused on the performance of policies trained alongside the reward function. This practice, however, may fail to detect learned rewards that are not capable of training new policies from scratch and thus do not capture the intended behavior. Our work focuses on demonstrating and studying the causes of these relearning failures in the domain of preference-based reward learning. We demonstrate with experiments in tabular and continuous control environments that the severity of relearning failures can be sensitive to changes in reward model design and the trajectory dataset composition. Based on our findings, we emphasize the need for more retraining-based evaluations in the literature.
Adversarial Policies Beat Professional-Level Go AIs
Nov 01, 2022



We attack the state-of-the-art Go-playing AI system, KataGo, by training an adversarial policy that plays against a frozen KataGo victim. Our attack achieves a >99% win-rate against KataGo without search, and a >50% win-rate when KataGo uses enough search to be near-superhuman. To the best of our knowledge, this is the first successful end-to-end attack against a Go AI playing at the level of a top human professional. Notably, the adversary does not win by learning to play Go better than KataGo -- in fact, the adversary is easily beaten by human amateurs. Instead, the adversary wins by tricking KataGo into ending the game prematurely at a point that is favorable to the adversary. Our results demonstrate that even professional-level AI systems may harbor surprising failure modes. See https://goattack.alignmentfund.org/ for example games.
TransNAS-Bench-101: Improving Transferability and Generalizability of Cross-Task Neural Architecture Search
May 25, 2021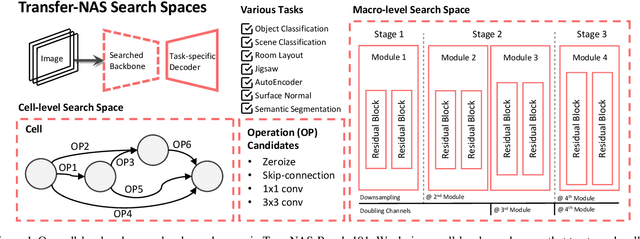
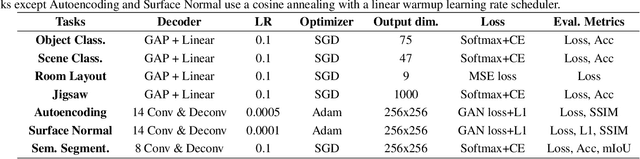


Recent breakthroughs of Neural Architecture Search (NAS) extend the field's research scope towards a broader range of vision tasks and more diversified search spaces. While existing NAS methods mostly design architectures on a single task, algorithms that look beyond single-task search are surging to pursue a more efficient and universal solution across various tasks. Many of them leverage transfer learning and seek to preserve, reuse, and refine network design knowledge to achieve higher efficiency in future tasks. However, the enormous computational cost and experiment complexity of cross-task NAS are imposing barriers for valuable research in this direction. Existing NAS benchmarks all focus on one type of vision task, i.e., classification. In this work, we propose TransNAS-Bench-101, a benchmark dataset containing network performance across seven tasks, covering classification, regression, pixel-level prediction, and self-supervised tasks. This diversity provides opportunities to transfer NAS methods among tasks and allows for more complex transfer schemes to evolve. We explore two fundamentally different types of search space: cell-level search space and macro-level search space. With 7,352 backbones evaluated on seven tasks, 51,464 trained models with detailed training information are provided. With TransNAS-Bench-101, we hope to encourage the advent of exceptional NAS algorithms that raise cross-task search efficiency and generalizability to the next level. Our dataset file will be available at Mindspore, VEGA.
CATCH: Context-based Meta Reinforcement Learning for Transferrable Architecture Search
Jul 22, 2020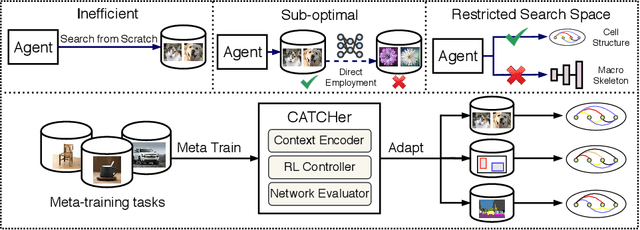
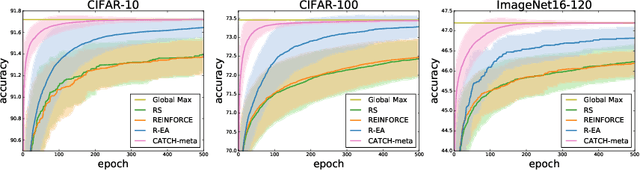
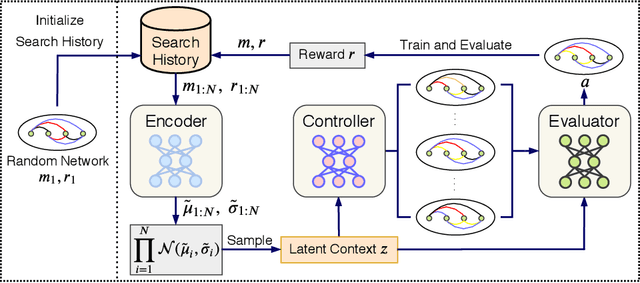
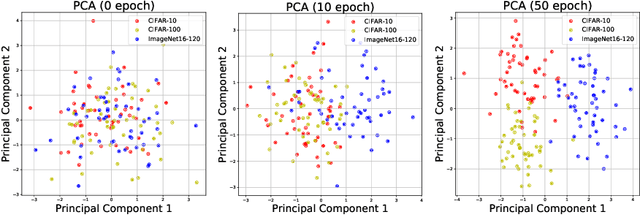
Neural Architecture Search (NAS) achieved many breakthroughs in recent years. In spite of its remarkable progress, many algorithms are restricted to particular search spaces. They also lack efficient mechanisms to reuse knowledge when confronting multiple tasks. These challenges preclude their applicability, and motivate our proposal of CATCH, a novel Context-bAsed meTa reinforcement learning (RL) algorithm for transferrable arChitecture searcH. The combination of meta-learning and RL allows CATCH to efficiently adapt to new tasks while being agnostic to search spaces. CATCH utilizes a probabilistic encoder to encode task properties into latent context variables, which then guide CATCH's controller to quickly "catch" top-performing networks. The contexts also assist a network evaluator in filtering inferior candidates and speed up learning. Extensive experiments demonstrate CATCH's universality and search efficiency over many other widely-recognized algorithms. It is also capable of handling cross-domain architecture search as competitive networks on ImageNet, COCO, and Cityscapes are identified. This is the first work to our knowledge that proposes an efficient transferrable NAS solution while maintaining robustness across various settings.