 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Problems in Mechanistic Interpretability
Jan 27, 2025



Mechanistic interpretability aims to understand the computational mechanisms underlying neural networks' capabilities in order to accomplish concrete scientific and engineering goals. Progress in this field thus promises to provide greater assurance over AI system behavior and shed light on exciting scientific questions about the nature of intelligence. Despite recent progress toward these goals, there are many open problems in the field that require solutions before many scientific and practical benefits can be realized: Our methods require both conceptual and practical improvements to reveal deeper insights; we must figure out how best to apply our methods in pursuit of specific goals; and the field must grapple with socio-technical challenges that influence and are influenced by our work. This forward-facing review discusses the current frontier of mechanistic interpretability and the open problems that the field may benefit from prioritizing.
Gradient Routing: Masking Gradients to Localize Computation in Neural Networks
Oct 06, 2024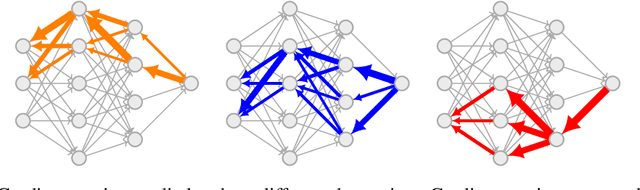

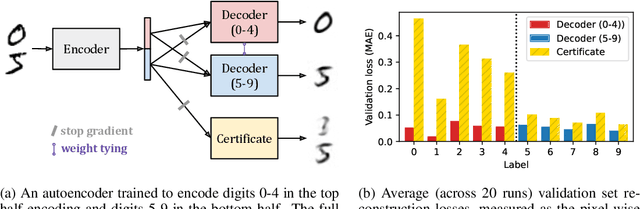

Neural networks are trained primarily based on their inputs and outputs, without regard for their internal mechanisms. These neglected mechanisms determine properties that are critical for safety, like (i) transparency; (ii) the absence of sensitive information or harmful capabilities; and (iii) reliable generalization of goals beyond the training distribution. To address this shortcoming, we introduce gradient routing, a training method that isolates capabilities to specific subregions of a neural network. Gradient routing applies data-dependent, weighted masks to gradients during backpropagation. These masks are supplied by the user in order to configure which parameters are updated by which data points. We show that gradient routing can be used to (1) learn representations which are partitioned in an interpretable way; (2) enable robust unlearning via ablation of a pre-specified network subregion; and (3) achieve scalable oversight of a reinforcement learner by localizing modules responsible for different behaviors. Throughout, we find that gradient routing localizes capabilities even when applied to a limited, ad-hoc subset of the data. We conclude that the approach holds promise for challenging, real-world applications where quality data are scarce.
Transformer Circuit Faithfulness Metrics are not Robust
Jul 11, 2024



Mechanistic interpretability work attempts to reverse engineer the learned algorithms present inside neural networks. One focus of this work has been to discover 'circuits' -- subgraphs of the full model that explain behaviour on specific tasks. But how do we measure the performance of such circuits? Prior work has attempted to measure circuit 'faithfulness' -- the degree to which the circuit replicates the performance of the full model. In this work, we survey many considerations for designing experiments that measure circuit faithfulness by ablating portions of the model's computation. Concerningly, we find existing methods are highly sensitive to seemingly insignificant changes in the ablation methodology. We conclude that existing circuit faithfulness scores reflect both the methodological choices of researchers as well as the actual components of the circuit - the task a circuit is required to perform depends on the ablation used to test it. The ultimate goal of mechanistic interpretability work is to understand neural networks, so we emphasize the need for more clarity in the precise claims being made about circuits. We open source a library at https://github.com/UFO-101/auto-circuit that includes highly efficient implementations of a wide range of ablation methodologies and circuit discovery algorithms.
Adversarial Policies Beat Professional-Level Go AIs
Nov 01, 2022



We attack the state-of-the-art Go-playing AI system, KataGo, by training an adversarial policy that plays against a frozen KataGo victim. Our attack achieves a >99% win-rate against KataGo without search, and a >50% win-rate when KataGo uses enough search to be near-superhuman. To the best of our knowledge, this is the first successful end-to-end attack against a Go AI playing at the level of a top human professional. Notably, the adversary does not win by learning to play Go better than KataGo -- in fact, the adversary is easily beaten by human amateurs. Instead, the adversary wins by tricking KataGo into ending the game prematurely at a point that is favorable to the adversary. Our results demonstrate that even professional-level AI systems may harbor surprising failure modes. See https://goattack.alignmentfund.org/ for example games.